

 新火種
2023-09-15
新火種
2023-09-15 


機(jī)器學(xué)習(xí)在馬蜂窩酒店聚合中的應(yīng)用初探
出門旅行,訂酒店是必不可少的一個(gè)環(huán)節(jié)。住得干凈、舒心對于每個(gè)出門在外的人來說都非常重要。在線預(yù)訂酒店讓這件事更加方便。當(dāng)用戶在馬蜂窩打開一家選中的酒店時(shí),不同供應(yīng)商提供的預(yù)訂信息會形成一個(gè)聚合列表準(zhǔn)確地展示給用戶。這樣做首先避免同樣的信息多次展示給用戶影響體驗(yàn),更重要的是幫助用戶進(jìn)行全網(wǎng)酒店實(shí)時(shí)比價(jià),快速找到性價(jià)比最高的供應(yīng)商,完成消費(fèi)決策。酒店聚合能力的強(qiáng)弱,決定著用戶預(yù)訂酒店時(shí)可選價(jià)格的「厚度」,進(jìn)而影響用戶個(gè)性化、多元化的預(yù)訂體驗(yàn)。為了使酒店聚合更加實(shí)時(shí)、準(zhǔn)確、高效,現(xiàn)在馬蜂窩酒店業(yè)務(wù)中近 80% 的聚合任務(wù)都是由機(jī)器自動完成。本文將詳細(xì)闡述酒店聚合是什么,以及時(shí)下熱門的機(jī)器學(xué)習(xí)技術(shù)在酒店聚合中是如何應(yīng)用的。
Part.1應(yīng)用場景和挑戰(zhàn)
1.酒店聚合的應(yīng)用場景馬蜂窩酒旅平臺接入了大量的供應(yīng)商,不同供應(yīng)商會提供很多相同的酒店,但對同一酒店的描述可能會存在差異,比如:
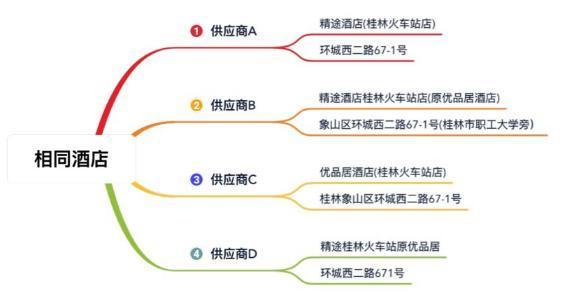
酒店聚合要做的,就是將這些來自不同供應(yīng)商的酒店信息聚合在一起集中展示給用戶,為用戶提供一站式實(shí)時(shí)比價(jià)預(yù)訂服務(wù):
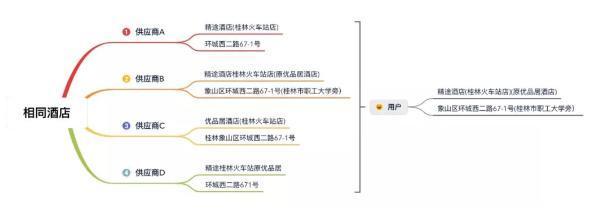
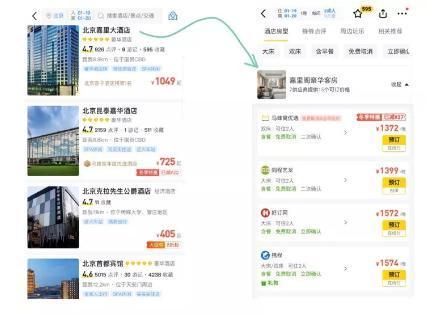
下圖為馬蜂窩對不同供應(yīng)商的酒店進(jìn)行聚合后的展示,不同供應(yīng)商的報(bào)價(jià)一目了然,用戶進(jìn)行消費(fèi)決策更加高效、便捷。
2.挑戰(zhàn)
(1) 準(zhǔn)確性上文說過,不同供應(yīng)商對于同一酒店的描述可能存在偏差。如果聚合出現(xiàn)錯(cuò)誤,就會導(dǎo)致用戶在 App 中看到的酒店不是實(shí)際想要預(yù)訂的:
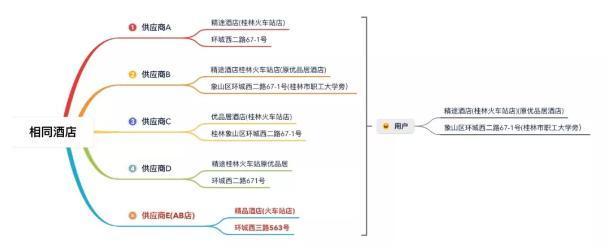
在上圖中,用戶在 App 中希望打開的是「精途酒店」,但系統(tǒng)可能為用戶訂到了供應(yīng)商 E 提供的「精品酒店」,對于這類聚合錯(cuò)誤的酒店我們稱之為 「AB 店」。可以想象,當(dāng)?shù)降旰髤s發(fā)現(xiàn)沒有訂單,這無疑會給用戶體驗(yàn)造成災(zāi)難性的影響。
(2) 實(shí)時(shí)性解決上述問題,最直接的方式就是全部采取人工聚合。人工聚合可以保證高準(zhǔn)確率,在供應(yīng)商和酒店數(shù)據(jù)量還不是那么大的時(shí)候是可行的。但馬蜂窩對接的是全網(wǎng)供應(yīng)商的酒店資源。采用人工的方式聚合處理得會非常慢,一來會造成一些酒店資源沒有聚合,無法為用戶展示豐富的預(yù)訂信息;二是如果價(jià)格出現(xiàn)波動,無法為用戶及時(shí)提供當(dāng)前報(bào)價(jià)。而且還會耗費(fèi)大量的人力資源。
酒店聚合的重要性顯而易見。但隨著業(yè)務(wù)的發(fā)展,接入的酒店數(shù)據(jù)快速增長,越來越多的技術(shù)難點(diǎn)和挑戰(zhàn)接踵而來。Part.2初期方案:余弦相似度算法初期我們基于余弦相似度算法進(jìn)行酒店聚合處理,以期降低人工成本,提高聚合效率。通常情況下,有了名稱、地址、坐標(biāo)這些信息,我們就能對一家酒店進(jìn)行唯一確定。當(dāng)然,最容易想到的技術(shù)方案就是通過比對兩家酒店的名稱、地址、距離來判斷是否相同。
基于以上分析,我們初版技術(shù)方案的聚合流程為:1.輸入待聚合酒店 A;2.ES 搜索與 A 酒店相距 5km 范圍內(nèi)相似度最高的 N 家線上酒店;3.N 家酒店與 A 酒店分別開始進(jìn)行兩兩比對;4.酒店兩兩計(jì)算整體名稱余弦相似度、整體地址余弦相似度、距離;5.通過人工制定相似度、距離的閾值來得出酒店是否相同的結(jié)論。
整體流程示意圖如下:
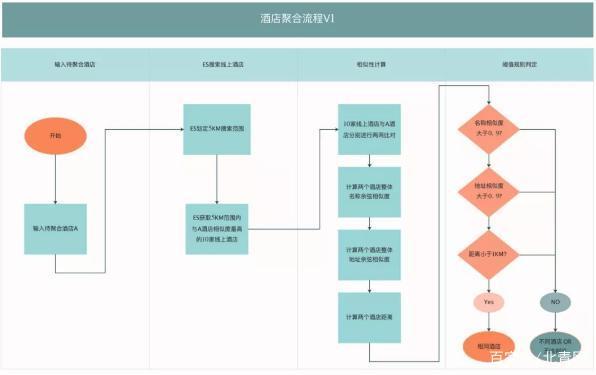
「酒店聚合流程 V1」上線后,我們驗(yàn)證了這個(gè)方案是可行的。它最大的優(yōu)點(diǎn)就是簡單,技術(shù)實(shí)現(xiàn)、維護(hù)成本很低,同時(shí)機(jī)器也能自動處理部分酒店聚合任務(wù),相比完全人工處理更加高效及時(shí)。但也正是因?yàn)檫@個(gè)方案太簡單了,問題也同樣明顯,我們來看下面的例子 (圖中數(shù)據(jù)虛構(gòu),僅為方便舉例):
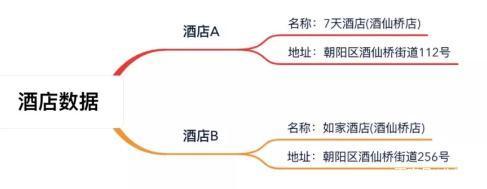
相信我們每個(gè)人都可以很快判斷出這是兩家不同的酒店。但是當(dāng)機(jī)器進(jìn)行整體的相似度計(jì)算時(shí),得到的數(shù)值并不低:
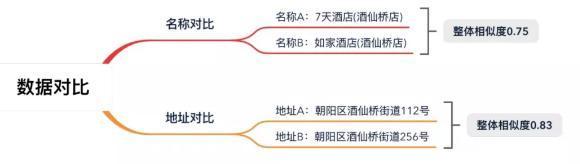
為了降低誤差率,我們需要將相似度比對的閾值提升至一個(gè)較高的指標(biāo)范圍內(nèi),因此大量的相似酒店都不會自動聚合,仍需要人工處理。最后,此版方案機(jī)器能自動處理的部分只占到約 30%,剩余 70% 仍需要人工處理;且機(jī)器自動聚合準(zhǔn)確率約為 95%,也就是有 5% 的概率會產(chǎn)生 AB 店,用戶到店無單,入住體驗(yàn)非常不好。于是,伴隨著機(jī)器學(xué)習(xí)的興起,我們開始了將機(jī)器學(xué)習(xí)技術(shù)應(yīng)用于酒店聚合中的探索之旅,來解決實(shí)時(shí)性和準(zhǔn)確性這對矛盾。Part.3機(jī)器學(xué)習(xí)在酒店聚合中的應(yīng)用下面我將結(jié)合酒店聚合業(yè)務(wù)場景,分別從機(jī)器學(xué)習(xí)中的分詞處理、特征構(gòu)建、算法選擇、模型訓(xùn)練迭代、模型效果來一一介紹。
3.1 分詞處理之前的方案通過比對「整體名稱、地址」獲取相似度,粒度太粗。分詞是指對酒店名稱、地址等進(jìn)行文本切割,將整體的字符串分為結(jié)構(gòu)化的數(shù)據(jù),目的是解決名稱、地址整體比對粒度太粗的問題,同時(shí)也為后面構(gòu)建特征向量做準(zhǔn)備。
3.1.1 分詞詞典在聊具體的名稱、地址分詞之前,我們先來聊一下分詞詞典的構(gòu)建。現(xiàn)有分詞技術(shù)一般都基于詞典進(jìn)行分詞,詞典是否豐富、準(zhǔn)確,往往決定了分詞結(jié)果的好壞。在對酒店的名稱分詞時(shí),我們需要使用到酒店品牌、酒店類型詞典,如果純靠人工維護(hù)的話,需要耗費(fèi)大量的人力,且效率較低,很難維護(hù)出一套豐富的詞典。
在這里我們使用統(tǒng)計(jì)的思想,采用機(jī)器+人工的方式來快速維護(hù)分詞詞典:1. 隨機(jī)選取 100000+酒店,獲取其名稱數(shù)據(jù);2.對名稱從后往前、從前往后依次逐級切割;3.每一次切割獲取切割詞且切割詞的出現(xiàn)頻率+1;4.出現(xiàn)頻率較高的詞,往往就是酒店品牌詞或類型詞。
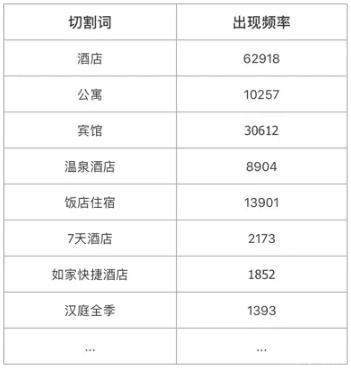
上表中示意的是出現(xiàn)頻率較高的詞,得到這些詞后再經(jīng)過人工簡單篩查,很快就能構(gòu)建出酒店品牌、酒店類型的分詞詞典。
3.1.2 名稱分詞想象一下人是如何比對兩家酒店名稱的?比如:A:7 天酒店 (酒仙橋店)B:如家酒店 (望京店)首先,因?yàn)榻?jīng)驗(yàn)知識的存在,人會不自覺地進(jìn)行「先分詞后對比」的判斷過程,即:7 天--->如家酒店--->酒店酒仙橋店--->望京店所以要想對比準(zhǔn)確,我們得按照人的思維進(jìn)行分詞。經(jīng)過對大量酒店名稱進(jìn)行人工模擬分詞,我們對酒店名稱分為如下結(jié)構(gòu)化字段:
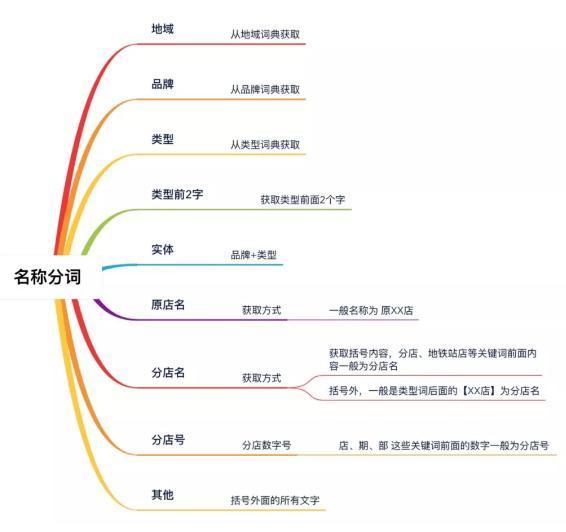
著重說下「類型前 2 字」這個(gè)字段。假如我們需要對如下 2 家酒店名稱進(jìn)行分詞:酒店 1:龍門南昆山碧桂園紫來龍庭溫泉度假別墅酒店 2:龍門南昆山碧桂園瀚名居溫泉度假別墅分詞效果如下:
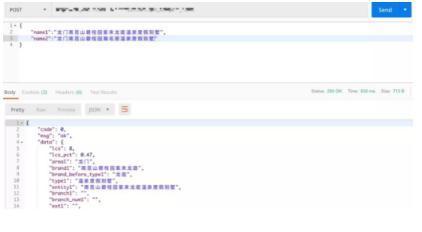
我們看到分詞后各個(gè)字段相似度都很高。但類型前 2 字分別為:酒店 1 類型前 2 字:龍庭酒店 2 類型前 2 字:名居這種情況下此字段 (類型前 2 字) 具有極高的區(qū)分度,因此可以作為一個(gè)很高效的對比特征。
3.1.3 地址分詞同樣,模擬人的思維進(jìn)行地址分詞,使之地址的比對粒度更細(xì)更具體。具體分詞方式見下圖:
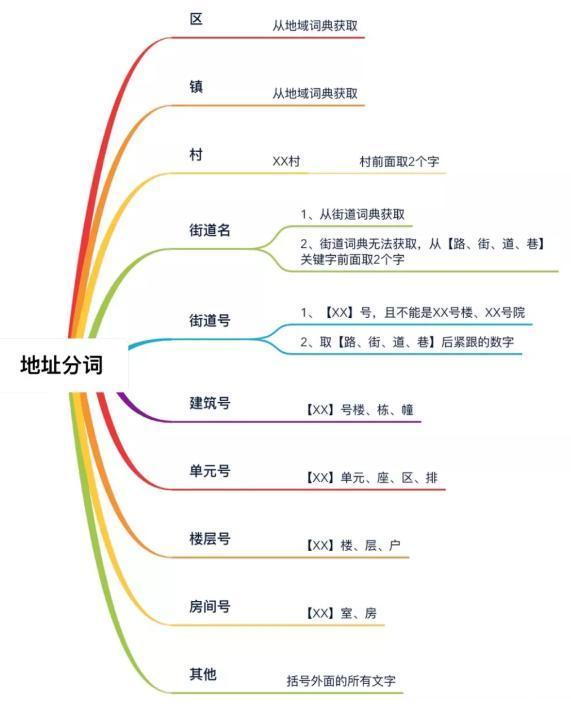
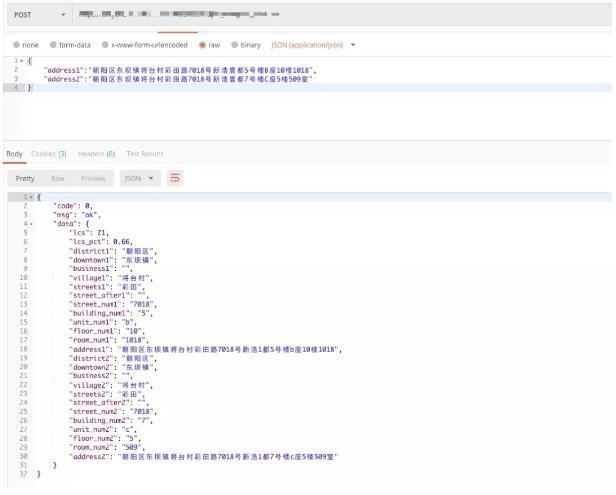
下面是具體的分詞效果展示如下:
小結(jié)分詞解決了對比粒度太粗的缺點(diǎn),現(xiàn)在我們大約有了 20 個(gè)對比維度。但對比規(guī)則、閾值怎么確定呢?人工制定規(guī)則、閾值存在很多缺點(diǎn),比如:
1.規(guī)則多變。20 個(gè)對比維度進(jìn)行組合會出現(xiàn) N 個(gè)規(guī)則,人工不可能全部覆蓋這些規(guī)則;
2.人工制定閾值容易受「經(jīng)驗(yàn)主義」先導(dǎo),容易出現(xiàn)誤判。
3.所以,對比維度雖然豐富了,但規(guī)則制定的難度相對來說提升了 N 個(gè)數(shù)量級。
機(jī)器學(xué)習(xí)的出現(xiàn),正好可以彌補(bǔ)這個(gè)缺點(diǎn)。機(jī)器學(xué)習(xí)通過大量訓(xùn)練數(shù)據(jù),從而學(xué)習(xí)到多變的規(guī)則,有效解決人基本無法完成的任務(wù)。下面我們來詳細(xì)看下特征構(gòu)建以及機(jī)器學(xué)習(xí)的過程。
3.2 特征構(gòu)建我們花了很大的力氣來模擬人的思維進(jìn)行分詞,其實(shí)也是為構(gòu)建特征向量做準(zhǔn)備。特征構(gòu)建的過程其實(shí)也是模擬人思維的一個(gè)過程,目的是針對分詞的結(jié)構(gòu)化數(shù)據(jù)進(jìn)行兩兩比對,將比對結(jié)果數(shù)字化以構(gòu)造特征向量,為機(jī)器學(xué)習(xí)做準(zhǔn)備。
對于不同供應(yīng)商,我們確定能拿到的數(shù)據(jù)主要包括酒店名稱、地址、坐標(biāo)經(jīng)緯度,可能獲得的數(shù)據(jù)還包括電話和郵箱。1.經(jīng)過一系列數(shù)據(jù)調(diào)研,最終確定可用的數(shù)據(jù)為名稱、地址、電話,主要是:因?yàn)?.部分供應(yīng)商經(jīng)緯度坐標(biāo)系有問題,精準(zhǔn)度不高,因此我們暫不使用,但待聚合酒店距離限制在 5km 范圍內(nèi);3.郵箱覆蓋率較低,暫不使用。4.要注意的是,名稱、地址拓展對比維度主要基于其分詞結(jié)果,但電話數(shù)據(jù)加入對比的話首先要進(jìn)行電話數(shù)據(jù)格式的清洗。最終確定的特征向量大致如下,因?yàn)橄嗨贫人惴ū容^簡單,這里不再贅述:
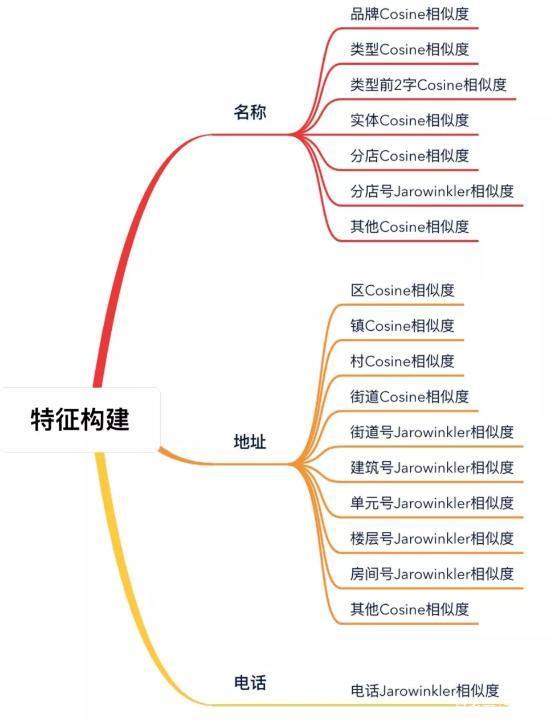
3.3 算法選擇:決策樹判斷酒店是否相同,很明顯這是有監(jiān)督的二分類問題,判斷標(biāo)準(zhǔn)為:有人工標(biāo)注的訓(xùn)練集、驗(yàn)證集、測試集;輸入兩家酒店,模型返回的結(jié)果只分為「相同」或「不同」兩類情況。·經(jīng)過對多個(gè)現(xiàn)有成熟算法的對比,我們最終選擇了決策樹,核心思想是根據(jù)在不同 Feature 上的劃分,最終得到?jīng)Q策樹。每一次劃分都向減小信息熵的方向進(jìn)行,從而做到每一次劃分都減少一次不確定性。這里摘錄一張圖片,方便大家理解: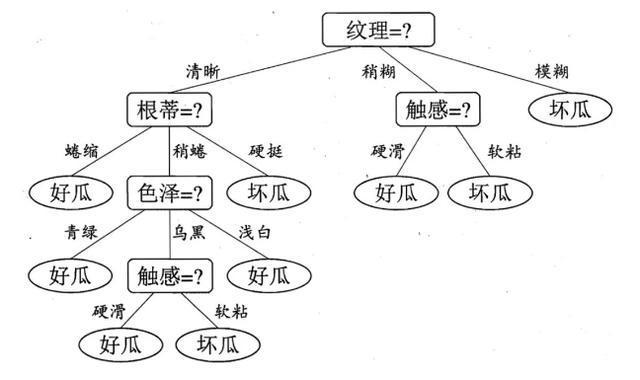
(圖源:《機(jī)器學(xué)習(xí)西瓜書》)
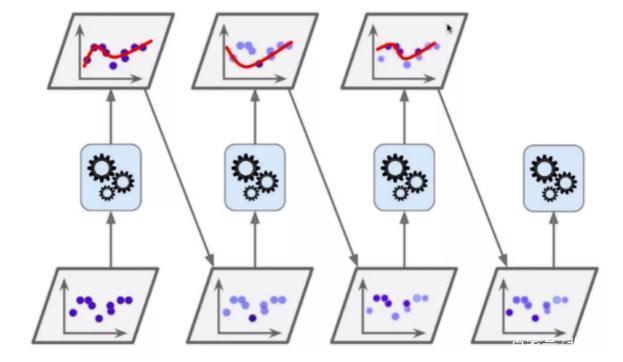
3.3.1 Ada Boosting OR Gradient Boosting具體的算法我們選擇的是 Boosting。「三個(gè)臭皮匠,頂過諸葛亮」這句話是對 Boosting 很好的描述。Boosting 類似于專家會診,一個(gè)人決策可能會有不確定性,可能會失誤,但一群人最終決策產(chǎn)生的誤差通常就會非常小。Boosting 一般以樹模型作為基礎(chǔ),其分類目前主要為 Ada Boosting、Gradient Boosting。Ada Boosting初次得出來一個(gè)模型,存在無法擬合的點(diǎn),然后對無法擬合的點(diǎn)提高權(quán)重,依次得到多個(gè)模型。得出來的多個(gè)模型,在預(yù)測的時(shí)候進(jìn)行投票選擇。如下圖所示:
Gradient Boosting 則是通過對前一個(gè)模型產(chǎn)生的錯(cuò)誤由后一個(gè)模型去擬合,對于后一個(gè)模型產(chǎn)生的錯(cuò)誤再由后面一個(gè)模型去擬合…然后依次疊加這些模型: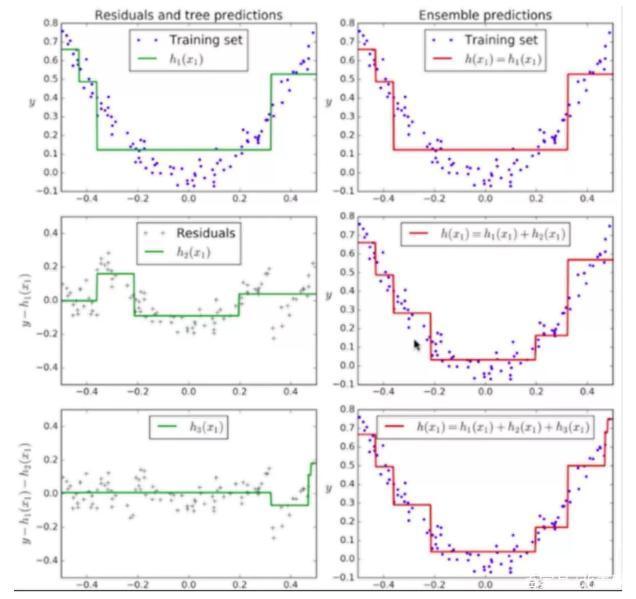
一般來說,Gradient Boosting 在工業(yè)界使用的更廣泛,我們也以 Gradient Boosting 作為基礎(chǔ)。3.3.2 XGBoost OR LightGBMXGBoost、LightGBM 都是 Gradient Boosting 的一種高效系統(tǒng)實(shí)現(xiàn)。我們分別從內(nèi)存占用、準(zhǔn)確率、訓(xùn)練耗時(shí)方面進(jìn)行了對比,LightGBM 內(nèi)存占用降低了很多,準(zhǔn)確率方面兩者基本一致,但訓(xùn)練耗時(shí)卻也降低了很多。
內(nèi)存占用對比:
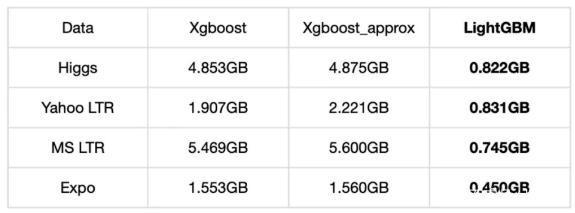
準(zhǔn)確率對比:
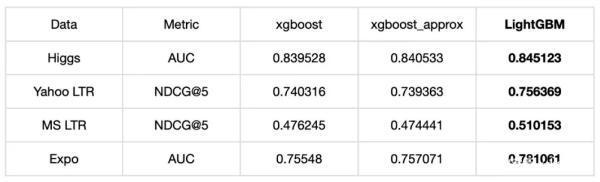
訓(xùn)練耗時(shí)對比:
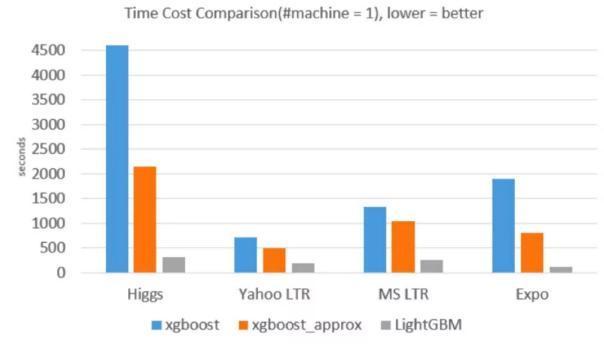
(圖源:微軟亞洲研究院)
基于以上對比數(shù)據(jù)參考,為了模型快速迭代訓(xùn)練,我們最終選擇了 LightGBM。
3.4 模型訓(xùn)練迭代由于使用 LightGBM,訓(xùn)練耗時(shí)大大縮小,所以我們可以進(jìn)行快速的迭代。模型訓(xùn)練主要關(guān)注兩方面內(nèi)容:訓(xùn)練結(jié)果分析模型超參調(diào)節(jié)
3.4.1 訓(xùn)練結(jié)果分析訓(xùn)練結(jié)果可能一開始差強(qiáng)人意,沒有達(dá)到理想的效果,這時(shí)需要我們仔細(xì)分析什么原因?qū)е碌倪@個(gè)結(jié)果,是特征向量的問題?還是相似度計(jì)算的問題?還是算法的問題?具體原因具體分析,但總歸會慢慢達(dá)到理想的結(jié)果。
3.4.2 模型超參調(diào)節(jié)這里主要介紹一些超參數(shù)調(diào)節(jié)的經(jīng)驗(yàn)。
首先大致說一下比較重要的參數(shù):
(1) maxdepth 與 numleavesmaxdepth 與 numleaves 是提高精度以及防止過擬合的重要參數(shù):maxdepth : 顧名思義為「樹的深度」,過大可能導(dǎo)致過擬合numleaves 一棵樹的葉子數(shù)。LightGBM 使用的是 leaf-wise 算法,此參數(shù)是控制樹模型復(fù)雜度的主要參數(shù)
(2) feature_fraction 與 bagging_fractionfeature_fraction 與 bagging_fraction 可以防止過擬合以及提高訓(xùn)練速度:feature_fraction :隨機(jī)選擇部分特征 (0<<>feature_fraction<1)bagging_fraction 隨機(jī)選擇部分?jǐn)?shù)據(jù) (0<<>bagging_fraction<1)
(3) lambda_l1 與 lambda_l2lambda_l1 與 lambda_l2 都是正則化項(xiàng),可以有效防止過擬合。lambda_l1 :L1 正則化項(xiàng)lambda_l2 :L2 正則化項(xiàng)
3.5 模型效果經(jīng)過多輪迭代、優(yōu)化、驗(yàn)證,目前我們的酒店聚合模型已趨于穩(wěn)定。對方案效果的評估通常是憑借「準(zhǔn)確率」與「召回率」兩個(gè)指標(biāo)。但酒店聚合業(yè)務(wù)場景下,需要首先保證絕對高的準(zhǔn)確率(聚合錯(cuò)誤產(chǎn)生 AB 店影響用戶入住),然后才是較高的召回率。經(jīng)過多輪驗(yàn)證,目前模型的準(zhǔn)確率可以達(dá)到 99.92% 以上,召回率也達(dá)到了 85.62% 以上:
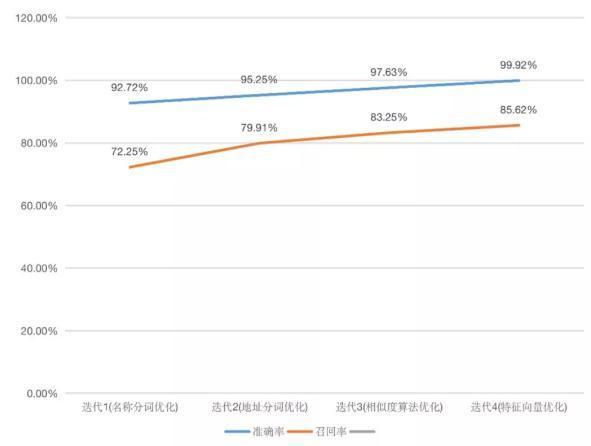
可以看到準(zhǔn)確率已經(jīng)達(dá)到一個(gè)比較高的水準(zhǔn)。但為保險(xiǎn)起見,聚合完成后我們還會根據(jù)酒店名稱、地址、坐標(biāo)、設(shè)施、類型等不同維度建立一套二次校驗(yàn)的規(guī)則;同時(shí)對于部分當(dāng)天預(yù)訂當(dāng)天入住的訂單,我們還會介入人工進(jìn)行實(shí)時(shí)的校驗(yàn),來進(jìn)一步控制 AB 店出現(xiàn)的風(fēng)險(xiǎn)。3.6 方案總結(jié)整體方案介紹完后,我們將基于機(jī)器學(xué)習(xí)的酒店聚合流程大致示意為下圖:
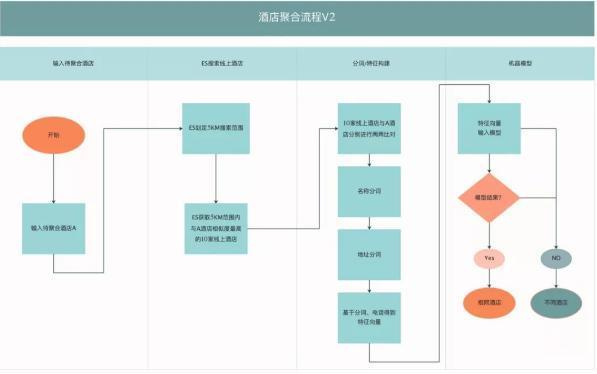
經(jīng)過上面的探索,我們大致理解了:1.解決方案都是一個(gè)慢慢演進(jìn)的過程,當(dāng)發(fā)現(xiàn)滿足不了需求的時(shí)候就會進(jìn)行迭代;2.分詞解決了對比粒度太粗的缺點(diǎn),模擬人的思維進(jìn)行斷句分詞;3.機(jī)器學(xué)習(xí)可以得到復(fù)雜的規(guī)則,通過大量訓(xùn)練數(shù)據(jù)解決人無法完成的任務(wù)。Part 4寫在最后新技術(shù)的探索充滿挑戰(zhàn)也很有意義。未來我們會進(jìn)一步迭代優(yōu)化,高效完成酒店的聚合,保證信息的準(zhǔn)確性和及時(shí)性,提升用戶的預(yù)訂體驗(yàn),比如:
1.進(jìn)行不同供應(yīng)商國內(nèi)酒店資源的坐標(biāo)系統(tǒng)一。坐標(biāo)對于酒店聚合是很重要的 Feature,相信坐標(biāo)系統(tǒng)一后,酒店聚合的準(zhǔn)確率、召回率會進(jìn)一步提高。
2.打通風(fēng)控與聚合的閉環(huán)。風(fēng)控與聚合建立實(shí)時(shí)雙向數(shù)據(jù)通道,從而進(jìn)一步提高兩個(gè)服務(wù)的基礎(chǔ)能力。
上述主要講的是國內(nèi)酒店聚合的演進(jìn)方案,對于「國外酒店」數(shù)據(jù)的機(jī)器聚合,方法其實(shí)又很不同,比如國外酒店名稱、地址如何分詞,詞形還原與詞干提取怎么做等,我們在這方面有相應(yīng)的探索和實(shí)戰(zhàn),總體效果甚至優(yōu)于國內(nèi)酒店的聚合,后續(xù)我們也會通過文章和大家分享,希望感興趣的同學(xué)持續(xù)關(guān)注。
免責(zé)聲明:市場有風(fēng)險(xiǎn),選擇需謹(jǐn)慎!此文僅供參考,不作買賣依據(jù)。
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
