

 新火種
2023-10-28
新火種
2023-10-28 


Aquarium華人CEO分享:機器學習在自動駕駛中落地,核心不是模型,是管道

編輯 | 陳彩嫻
當我大學畢業(yè)后開始第一份工作時,我自認為對機器學習了解不少。我曾在 Pinterest 和可汗學院(Khan Academy)有過兩次實習,工作內容是建立機器學習系統(tǒng)。在伯克利大學的最后一年,我展開了計算機視覺深度學習的研究,并在 Caffe 上工作,這是最早流行的深度學習庫之一。畢業(yè)后,我加入了一家名為“ Cruise ”的小型創(chuàng)業(yè)公司,Cruise專門生產(chǎn)自動駕駛汽車。現(xiàn)在我在 Aquarium,幫助多家公司部署深度學習模型來解決重要的社會問題。這些年來,我建立了相當酷的深度學習和計算機視覺堆棧。與我在伯克利做研究的時候相比,現(xiàn)在有更多的人在生產(chǎn)應用程序中使用深度學習。現(xiàn)在他們面臨的許多問題,與我2016年在 Cruise 所面臨的問題是一樣的。我有很多在生產(chǎn)中進行深度學習的經(jīng)驗教訓想與你們分享,希望大家可以不必通過艱難的方式來學習它們。
將ML模型部署到自動駕駛車上的故事首先,讓我談談 Cruise 公司有史以來第一個部署在汽車上的ML模型。在我們開發(fā)模型的過程中,工作流程感覺很像我在研究時期所習慣的那樣。我們在開源數(shù)據(jù)上訓練開源模型,將之集成到公司產(chǎn)品軟件堆棧中,并部署到汽車上。經(jīng)過幾個星期的工作,我們合并的最終 PR, 在汽車上運行模型。“任務完成了!”我心想,我們該繼續(xù)撲滅下一場大火。我不知道的是,真正的工作才剛剛開始。模型投入生產(chǎn)運行,我們的 QA 團隊開始注意到它的性能方面的問題。但是我們還有其他的模型要建立,還有其他任務要做,所以我們沒有立即去解決這些問題。3個月后,當我們研究這些問題時,我們發(fā)現(xiàn)訓練和驗證腳本已經(jīng)全部崩潰,因為自我們第一次部署以來,代碼庫已經(jīng)發(fā)生了變化。經(jīng)過一個星期的修復,我們查看了過去幾個月的故障,意識到在模型生產(chǎn)運行中觀察到的許多問題不能通過修改模型代碼輕松解決,我們需要去收集和標記來自我們公司車輛的新數(shù)據(jù),而不是依靠開放源碼的數(shù)據(jù)。這意味著我們需要建立一個標簽流程,包括流程所需要的所有工具、操作和基礎設施。又過了3個月,我們運行了一個新的模型,這個模型是根據(jù)我們從車上隨機選取的數(shù)據(jù)進行訓練的。然后,用我們自己的工具進行標記。但是當我們開始解決簡單的問題時,我們不得不對哪些變化可能產(chǎn)生結果變得更加敏銳。大約90% 的問題是通過對艱難或罕見的場景進行仔細的數(shù)據(jù)整理來解決的,而不是通過深度模型架構變更或超參數(shù)調整。例如,我們發(fā)現(xiàn)模型在雨天的表現(xiàn)很差(在舊金山很罕見),所以我們標記了更多雨天的數(shù)據(jù),在新的數(shù)據(jù)上重新訓練模型,結果模型的表現(xiàn)得到了改善。同樣,我們發(fā)現(xiàn)該模型在綠色視錐上的性能較差(與橙色視錐相比較少見),因此我們收集了綠色視錐的數(shù)據(jù),經(jīng)過了同樣的過程,模型的性能得到了改善。我們需要建立一個可以快速識別和解決這類問題的流程。花費數(shù)個星期,這個模型的 1.0 版本組裝好了,又用了6個月,新推出一個改進版本模型。隨著我們在一些方面(更好地標記基礎設施、云數(shù)據(jù)處理、培訓基礎設施、部署監(jiān)控)的工作越來越多,大約每月到每周都能重新訓練和重新部署模型。當我們從頭開始建立更多的模型管道,并努力改善它們,我們開始看到一些共同的主題。將我們所學到的知識應用到新的管道中,更快更省力地運行更好的型號變得容易了。
保持迭代學習
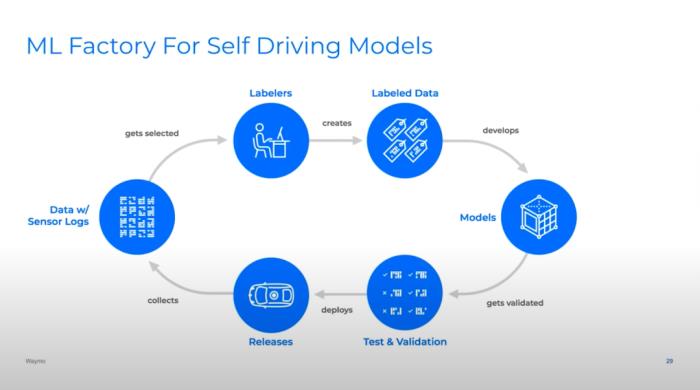
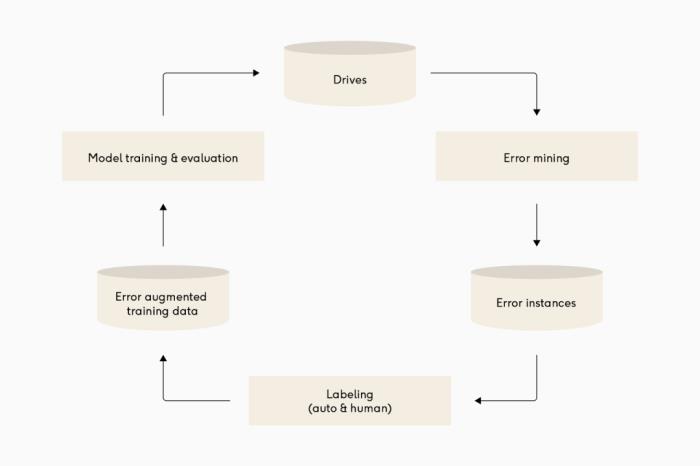
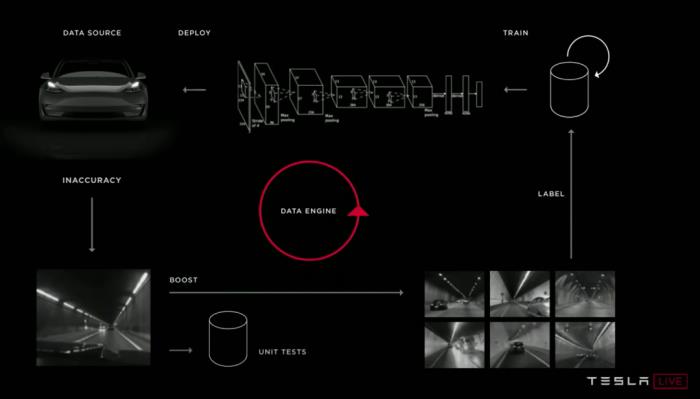
建立反饋回路
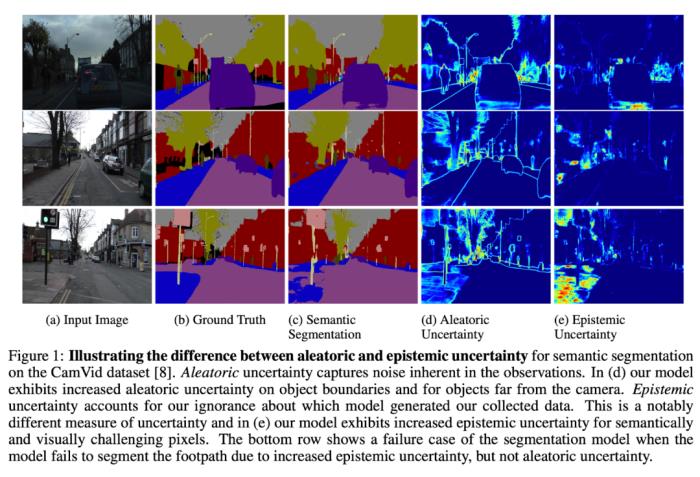 校準模型的不確定性是一個誘人的研究領域,模型可以標記它認為可能失敗的地方。對模型進行有效迭代的一個關鍵部分是集中精力解決最具影響力的問題。要改進一個模型,你需要知道它有什么問題,并且能夠根據(jù)產(chǎn)品/業(yè)務的優(yōu)先級對問題進行分類。建立反饋回路的方法有很多,但是首先要發(fā)現(xiàn)和分類錯誤。利用特定領域的反饋回路。如果有的話,這可能是獲得模型反饋的非常強大和有效的方法。例如,預測任務可以通過對實際發(fā)生的歷史數(shù)據(jù)進行訓練來“免費 ”獲得標簽數(shù)據(jù),使他們能夠不斷地輸入大量的新數(shù)據(jù),并相當自動地適應新情況。設置一個工作流程,讓人可以審查你的模型的輸出,并在發(fā)生錯誤時進行標記。當人們很容易通過許多模型推斷捕獲錯誤時,這種方法尤其適用。這種情況最常見的發(fā)生方式是當客戶注意到模型輸出中的錯誤并向機器學習團隊投訴。這是不可低估的,因為這個渠道可以讓您直接將客戶反饋納入開發(fā)周期!一個團隊可以讓人類雙重檢查客戶可能錯過的模型輸出:想象一下一個操作人員看著一個機器人在傳送帶上對包進行分類,當他們發(fā)現(xiàn)一個錯誤發(fā)生時,就點擊一個按鈕。設置一個工作流程,讓人可以審查你的模型的輸出,并在發(fā)生錯誤時進行標記。當人類審查很容易捕捉到大量模型推論中的錯誤時,這就特別合適。最常見的方式是當客戶注意到模型輸出中的錯誤并向ML團隊投訴時。這一點不容小覷,因為這個渠道可以讓你直接將客戶的反饋納入開發(fā)周期中 一個團隊可以讓人類仔細檢查客戶可能錯過的模型輸出:想想一個操作人員看著機器人在傳送帶上分揀包裹,每當他們發(fā)現(xiàn)有錯誤發(fā)生時就點擊一個按鈕。當模型運行的頻率太高,以至于人們無法進行檢查時,可以考慮設置自動復查。當很容易針對模型輸出編寫“健全性檢查”時,這尤其有用。例如,每當激光雷達目標檢測器和二維圖像目標檢測器不一致時,或者幀到幀檢測器與時間跟蹤系統(tǒng)不一致時,標記。當它工作時,它提供了許多有用的反饋,告訴我們哪里出現(xiàn)了故障情況。當它不起作用時,它只是暴露了你的檢查系統(tǒng)中的錯誤,或者漏掉了所有系統(tǒng)出錯的情況,這是非常低風險高回報的。最通用(但困難)的解決方案是分析它所運行的數(shù)據(jù)的模型不確定性。一個簡單的例子是查看模型在生產(chǎn)中產(chǎn)生低置信度輸出的例子。這可以表現(xiàn)出模型確實不確定的地方,但不是100% 精確。有時候,模型可能是自信地錯誤的。有時模型是不確定的,因為缺乏可用的信息進行良好的推理(例如,人們很難理解的有噪聲的輸入數(shù)據(jù))。有一些模型可以解決這些問題,但這是一個活躍的研究領域。最后,可以利用模型對訓練集的反饋。例如,檢查模型與其訓練/驗證數(shù)據(jù)集(即高損失的例子)的不一致表明高可信度失敗或標記錯誤。神經(jīng)網(wǎng)絡嵌入分析可以提供一種理解訓練/驗證數(shù)據(jù)集中故障模式模式的方法,并且可以發(fā)現(xiàn)訓練數(shù)據(jù)集和生產(chǎn)數(shù)據(jù)集中原始數(shù)據(jù)分布的差異。
校準模型的不確定性是一個誘人的研究領域,模型可以標記它認為可能失敗的地方。對模型進行有效迭代的一個關鍵部分是集中精力解決最具影響力的問題。要改進一個模型,你需要知道它有什么問題,并且能夠根據(jù)產(chǎn)品/業(yè)務的優(yōu)先級對問題進行分類。建立反饋回路的方法有很多,但是首先要發(fā)現(xiàn)和分類錯誤。利用特定領域的反饋回路。如果有的話,這可能是獲得模型反饋的非常強大和有效的方法。例如,預測任務可以通過對實際發(fā)生的歷史數(shù)據(jù)進行訓練來“免費 ”獲得標簽數(shù)據(jù),使他們能夠不斷地輸入大量的新數(shù)據(jù),并相當自動地適應新情況。設置一個工作流程,讓人可以審查你的模型的輸出,并在發(fā)生錯誤時進行標記。當人們很容易通過許多模型推斷捕獲錯誤時,這種方法尤其適用。這種情況最常見的發(fā)生方式是當客戶注意到模型輸出中的錯誤并向機器學習團隊投訴。這是不可低估的,因為這個渠道可以讓您直接將客戶反饋納入開發(fā)周期!一個團隊可以讓人類雙重檢查客戶可能錯過的模型輸出:想象一下一個操作人員看著一個機器人在傳送帶上對包進行分類,當他們發(fā)現(xiàn)一個錯誤發(fā)生時,就點擊一個按鈕。設置一個工作流程,讓人可以審查你的模型的輸出,并在發(fā)生錯誤時進行標記。當人類審查很容易捕捉到大量模型推論中的錯誤時,這就特別合適。最常見的方式是當客戶注意到模型輸出中的錯誤并向ML團隊投訴時。這一點不容小覷,因為這個渠道可以讓你直接將客戶的反饋納入開發(fā)周期中 一個團隊可以讓人類仔細檢查客戶可能錯過的模型輸出:想想一個操作人員看著機器人在傳送帶上分揀包裹,每當他們發(fā)現(xiàn)有錯誤發(fā)生時就點擊一個按鈕。當模型運行的頻率太高,以至于人們無法進行檢查時,可以考慮設置自動復查。當很容易針對模型輸出編寫“健全性檢查”時,這尤其有用。例如,每當激光雷達目標檢測器和二維圖像目標檢測器不一致時,或者幀到幀檢測器與時間跟蹤系統(tǒng)不一致時,標記。當它工作時,它提供了許多有用的反饋,告訴我們哪里出現(xiàn)了故障情況。當它不起作用時,它只是暴露了你的檢查系統(tǒng)中的錯誤,或者漏掉了所有系統(tǒng)出錯的情況,這是非常低風險高回報的。最通用(但困難)的解決方案是分析它所運行的數(shù)據(jù)的模型不確定性。一個簡單的例子是查看模型在生產(chǎn)中產(chǎn)生低置信度輸出的例子。這可以表現(xiàn)出模型確實不確定的地方,但不是100% 精確。有時候,模型可能是自信地錯誤的。有時模型是不確定的,因為缺乏可用的信息進行良好的推理(例如,人們很難理解的有噪聲的輸入數(shù)據(jù))。有一些模型可以解決這些問題,但這是一個活躍的研究領域。最后,可以利用模型對訓練集的反饋。例如,檢查模型與其訓練/驗證數(shù)據(jù)集(即高損失的例子)的不一致表明高可信度失敗或標記錯誤。神經(jīng)網(wǎng)絡嵌入分析可以提供一種理解訓練/驗證數(shù)據(jù)集中故障模式模式的方法,并且可以發(fā)現(xiàn)訓練數(shù)據(jù)集和生產(chǎn)數(shù)據(jù)集中原始數(shù)據(jù)分布的差異。自動化和委托

鼓勵ML工程師健身

結語總結一下: 在研究和原型開發(fā)階段,重點是建立和發(fā)布一個模型。但是,隨著一個系統(tǒng)進入生產(chǎn)階段,核心任務是建立一個系統(tǒng),這個系統(tǒng)能夠以最小的努力定期發(fā)布改進的模型。這方面你做得越好,你可以建造的模型就越多!為此,我們需要關注以下方面:以規(guī)律的節(jié)奏運行模型管道,并專注于比以前更好的運輸模型。每周或更短的時間內獲得一個新的改進型號投入生產(chǎn)!建立一個良好的從模型輸出到開發(fā)過程的反饋回路。找出模型在哪些示例上做得不好,并向您的培訓數(shù)據(jù)集中添加更多的示例。自動化管道中特別繁重的任務,并建立一個團隊結構,使您的團隊成員能夠專注于他們的專業(yè)領域。特斯拉的Andrej Karpathy稱理想的最終狀態(tài)為“假期行動”。我建議,建立一個工作流程,讓你的機器學習工程師去健身房,讓你的機器學習管道來完成繁重的工作!最后,需要強調一下,在我的經(jīng)驗中,絕大多數(shù)關于模型性能的問題可以用數(shù)據(jù)來解決,但是有些問題只能通過修改模型代碼來解決。這些變化往往是非常特殊的模型架構在手頭,例如,在圖像對象檢測器工作了若干年后,我花了太多的時間擔心最佳先前的盒子分配為某些方位比和提高特征映射對小對象的分辨率。然而,隨著Transformer顯示出成為許多不同深度學習任務的萬能模型架構類型的希望,我懷疑這些技巧中的更多將變得不那么相關,機器學習發(fā)展的重點將進一步轉向改進數(shù)據(jù)集。參考鏈接:https://thegradient.pub/lessons-from-deploying-deep-learning-to-production/Kendall, A. & Gal, Y. (2017). What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Advances in Neural Information Processing Systems, 5574-5584.


相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
