

 新火種
2023-10-28
新火種
2023-10-28 


Baichuan2完勝LLaMA2,本土開源大模型的時代來了
本土大模型時代早晚會到來是業界共識,但卻沒想到來的這么快!
近日,中國大模型火了,在全球知名大模型開源社區HuggingFace上百川智能的兩款開源模型Baichuan7B、Baichuan13B受到了全球開發者們的熱捧,Baichuan開源系列近一個月下載量超347萬次,是月下載量最大的開源模型。
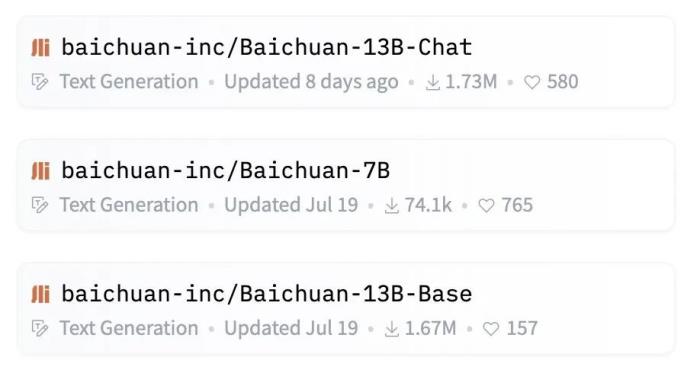
其中Baichuan-13B-Base在HuggingFace的下載量高達167萬次,Baichuan-13B-Chat的下載量超過173萬次,遠超LLaMA/LLaMA-2-13b-hf的14.9萬。
持續助力開源生態,百川智能再發兩款開源大模型
百川智能并未因此而沾沾自喜,在以開源模型助力中國大模型生態發展愿景的驅使下,9月6日,百川智能召開主題為“百川匯海,開源共贏”的大模型發布會,會上宣布正式開源Baichuan 2系列大模型,包含 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化,并且均為免費可商用。
Baichuan 2下載地址:https://github.com/baichuan-inc/Baichuan2
一直備受矚目的百川智能,自成立以來平均28天就能發布一款大模型。如果只是在速度上持續領先,或許可以理解為本就是一個“明星”創業公司的“分內之事”。但如果保持研發速度的同時,在質量上還完成了對LLaMA2的超越甚至是吊打,那必須值得稱贊一番。
本次百川智能發布的Baichuan-2實現了對LLaMA2的全面碾壓,這意味著中國開源大模型進入到了本土時代。
全面超越LLaMA2,Baichuan-2殺瘋了
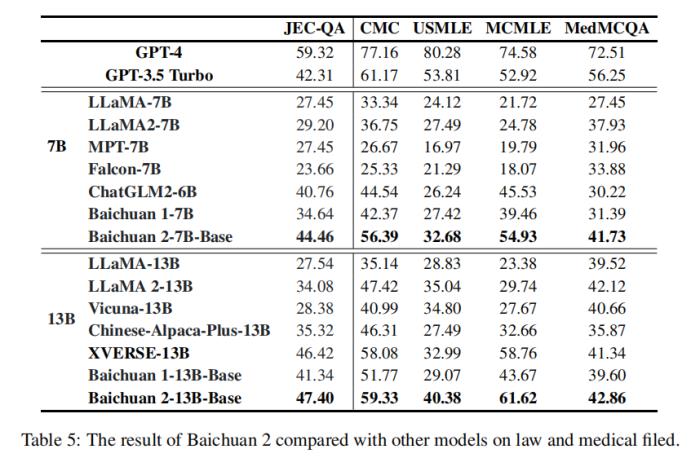
口說無憑,為評估模型的整體能力,Baichuan2系列大模型選擇了包括MMLU、CMMLU、MedQAUSMLE在內的8個基準,從總體性能、垂直領域、數學和編程、多語言、安全性以及中間檢查點六個部分進行了整體的LLM評估。
結果顯示Baichuan2系列大模型在大多數評估任務中的表現大幅領先LLaMA2,緊追GPT。
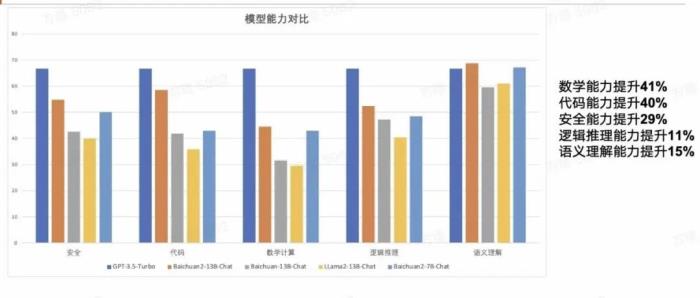
相較于此前開源的Baichuan-13B-chat,Baichuan2-13B-Chat在安全、對話、邏輯推理,語義理解、代碼等方面的能力有顯著提升,其中安全提升29%,對話提升42%,語義理解提升50%,邏輯推理提升58%,代碼提升70%。
不僅如此,Baichuan2-7B僅憑70億參數在英文基準上就已經能夠與LLaMA2的130億參數模型能力持平。這更從側面證明了Baichuan2系列模型在同參數級別下吊打LLaMA2的真實性。
Baichuan2之所以如此強悍,是因為百川智能在研發過程中借鑒了很多搜索經驗,對大量模型訓練數據進行了多粒度內容質量打分,同時Baichuan2-7B和Baichuan2-13B訓練時均使用了2.6億T的語料,并且加入了多語言的支持。
首創開源新模式,主打一個開放的徹底性
與移動互聯網時代手機操作系統比如安卓的開源不同,所謂的大模型開源,通常指的是公開自身的模型權重,很少有企業會選擇開源數據比重、數據處理等訓練細節。
科研機構、企業和開發者們即使拿到開源權限,也很難進行深入研究。換言之,即使OpenAI大發善心馬上就將GPT-4的參數權重開源出來,從業者們能做的也是在其基礎上做一些淺層的微調,想要復刻一個一模一樣的GPT-4根本不可能。
為了更好地助力大模型的學術研究,百川智能公布了3000億到2.6萬億Token模型訓練全過程的CheckPonit。
等于說,百川智能為大模型訓練剖開了一個完整的切面,讓大家可以更直觀的了解到大模型預訓練中的量化策略和模型的價值觀對齊等具體操作方法,這將為國內大模型的科研工作提供極大助力,這種開源方式在中文大模型領域是首創。
不僅如此,百川智能還在發布會上公開了Baichuan2-7B的技術報告。技術報告詳細介紹了Baichuan2-7B訓練的全過程,包括數據處理、模型結構優化、ScalingLaw、過程指標等。
這一系列徹底開放的操作,相當于重新定義了大模型“開源”,其開源模式或將成為國內“開源”的標桿。以后,“猶抱琵琶半遮面”式的開源將很難再出現。
另一個耐人尋味的事情是,在模型參數和結構設置上,Baichuan開源大模型在盡可能的靠近LLaMA系列,這意味著用戶能夠直接從LLaMA換成百川的模型。不難發現,百川智能不僅要在與LLaMA2正面硬剛中完勝,還要來個“釜底抽薪”,簡直贏麻了。
如何選擇開源大模型,不再是問題
“生存還是毀滅,這是一個值得考慮的問題”,這是《哈姆雷特》中的經典獨白。此前,國內企業在模型的選擇上面臨著同樣的掙扎。
OpenAI并不Open,只提供API調用,讓國內從業人員頗為頭疼。LLaMA的開源,似乎讓國內企業看到了更好的道路,尤其對于中小企業而言,無需從無到有訓練一個基礎模型,可以極大節省成本。
但使用LLaMA也面臨著兩個無解的問題。首先,LLaMA2在商業協議中明確表示不允許英文以外的語言商用,雖然不排除通過合理溝通解決這一問題的可能性,但需要耗費巨大的機會成本。

其次,LLaMA的中文表現差強人意。由于它并非多語言模型,其預訓練數據絕大部分使用的是英文數據集,中文預訓練數據的占比僅為0.13%,即使使用高質量中文數據集進行微調,中文表現也是慘不忍睹,而且慢得離譜。
除非重新構建數據集中的語料配比,加大中文數據從頭進行預訓練,否則很難得到大幅提升。而基于大規模中文語料進行預訓練,基本和自研大模型無異,從實用的角度來看,LLaMA2并不能滿足中文環境的應用需求。
Baichuan2的開源,無疑將徹底改變這種兩難的局面。不論小扎愿不愿意承認,LLaMA在中文世界的時代都已經結束了。
Baichuan系列開源模型正在引領開源社區走向中文開源大模型時代,百川智能率先在通用人工智能的道路上留下了屬于中國人的聲音。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
