

 新火種
2023-10-23
新火種
2023-10-23 


全都不及格!斯坦福100頁論文給大模型透明度排名,GPT
來源:火訊財(cái)經(jīng)
文章轉(zhuǎn)載來源:AIcore
原文來源:量子位
 圖片來源:由無界 AI生成
圖片來源:由無界 AI生成試問百模大戰(zhàn)的當(dāng)下,誰家大模型的透明度最高?
(例如模型是如何構(gòu)建的、如何工作、用戶如何使用它們的相關(guān)信息。)
現(xiàn)在,這個(gè)問題終于有解了。
因?yàn)樗固垢4髮W(xué)HAI等研究機(jī)構(gòu)最新共同發(fā)布了一項(xiàng)研究——
專門設(shè)計(jì)了一個(gè)名為基礎(chǔ)模型透明度指標(biāo)(The Foundation Model Transparency Index)的評分系統(tǒng)。
它從100個(gè)維度對國外10家主流的大模型做了排名,并在透明度這一層面上做了全面的評估。

結(jié)果可謂是大跌眼鏡!
若是以60分作為及格線,那么“參賽”的大模型們可以說是全軍覆沒,沒有一個(gè)及格的……
來感受下這個(gè)feel:
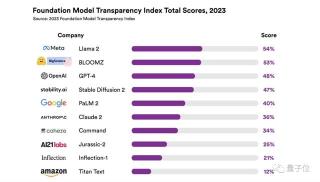
排名第一的Llama 2,分?jǐn)?shù)僅為54;緊隨其后的便是BLOOMZ,得分53。
而GPT-4分?jǐn)?shù)僅僅為48,排名第三;來自亞馬遜的Titan Text成績墊底,僅取得12分

。
不僅如此,在斯坦福HAI官方的博客中,負(fù)責(zé)人Rishi Bommasani直言不諱地把OpenAI單拎出來說到:
基礎(chǔ)模型領(lǐng)域的公司變得越來越不透明。
例如名字帶“open”的OpenAI曾明確表示,與GPT-4相關(guān)的大多數(shù)信息將不會(huì)公開。
總而言之,團(tuán)隊(duì)認(rèn)為大模型發(fā)展到現(xiàn)階段,它們的透明度是一個(gè)非常重要的關(guān)鍵點(diǎn),直接與是否可信掛鉤。
而且更深層次的,他們認(rèn)為這也從側(cè)面反映了人工智能行業(yè)從根本上缺乏透明度。
100多頁論文研究模型透明度
那么這個(gè)排名到底是怎么來的?
在成績公布的同時(shí),團(tuán)隊(duì)也把一篇厚達(dá)100多頁的論文曬了出來。

正如我們剛才提到的,這次排名一共涉及到了100個(gè)指標(biāo)維度。
若是“歸攏歸攏”著來看,可以將這些指標(biāo)大致分為三大類,分別是:
上游(Upstream):指構(gòu)建基礎(chǔ)模型所涉及的成分和過程,例如計(jì)算資源、數(shù)據(jù)等;模型(Model):指基礎(chǔ)模型的屬性和功能,例如體系結(jié)構(gòu)、能力和風(fēng)險(xiǎn)等;下游(Downstream):基礎(chǔ)模型是如何分布和使用的,例如對用戶的影響、更新內(nèi)容、控制策略等。將10大模型此次的成績,按照上面的三大維度來看,得分細(xì)節(jié)如下:
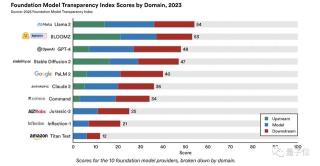
從結(jié)果上來看,“上游”類指標(biāo)的得分差異較為明顯;例如BLOOMZ的“上游”類指標(biāo)在整體得分中的占比較高。
而像Jurassic-2、Inflection-1和Titan Text,這三個(gè)模型的“上游”類指標(biāo)得分直接為0。
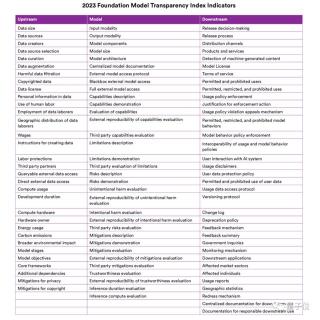
如果將“上游”、“模型”和“下游”視為三個(gè)“頂級域”,那么團(tuán)隊(duì)在它們基礎(chǔ)之上,還分了更精細(xì)、更深入的13個(gè)“子域”:
數(shù)據(jù)(Data)、勞動(dòng)力(Labor)、計(jì)算(Compute);方法(Methods)、模型基礎(chǔ)(Model Basicis)、模型訪問(Model Access)、功能(Capabilities);風(fēng)險(xiǎn)(Risks)、緩解措施(Mitigations)、分布(Distributions)、使用策略(Usage Policy)、反饋(Feedback)、影響(Impact)。13個(gè)“子域”劃分下的細(xì)節(jié)得分情況如下:

至于完整的100個(gè)指標(biāo)維度,可以參考下面這張圖表:
當(dāng)然,對于大模型領(lǐng)域最具熱度話題之一的“開源閉源之爭”,也在此次的研究中有所涉足。
團(tuán)隊(duì)將廣泛可下載的模型標(biāo)記為開源模型,“參賽選手”中有三位屬于此列,分別是Llama 2、BLOOMZ和Stable Diffusion 2。
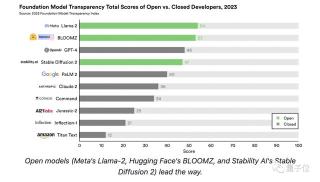
從排名結(jié)果中顯而易見地可以看出,開源模型的得分普遍遙遙領(lǐng)先,唯有GPT-4的得分比Stable Diffusion 2高出了1分。
對此,研究人員也做出了解釋:
這種差異很大程度上是由于閉源模型的開發(fā)人員在“上游”問題上缺乏透明度造成的,比如用于構(gòu)建模型的數(shù)據(jù)、勞動(dòng)力和計(jì)算。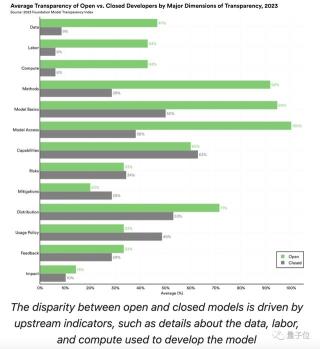
此次模型透明度排名的更多細(xì)節(jié)內(nèi)容,可參考文末的論文。
透明度為什么重要?
針對這個(gè)問題,斯坦福HAI在官方博客中也做出了相應(yīng)說明。
例如在負(fù)責(zé)人Rishi Bommasani看來:
缺乏透明度,長期以來一直是數(shù)字技術(shù)消費(fèi)者面臨的一個(gè)問題。
在當(dāng)下的互聯(lián)網(wǎng)中充斥著諸多這樣的問題,例如欺騙性的廣告和定價(jià)、欺騙用戶在不知情的情況下進(jìn)行網(wǎng)購等等。
MIT博士Shayne Longpre認(rèn)為,隨著大模型越發(fā)的火熱并且在各行各業(yè)中迅速落地,科學(xué)家們有必要了解它們是如何設(shè)計(jì)的,尤其是“上游”的那些指標(biāo)。
對于產(chǎn)業(yè)界來說,亦是如此,決策者們在面對“用哪個(gè)大模型、怎么用”等問題時(shí),都需要建立在模型透明度的基礎(chǔ)之上。

那么你對于這次大模型的透明度排名有怎樣的看法呢?歡迎在評論區(qū)留言交流~
論文地址:https://crfm.stanford.edu/fmti/fmti.pdf?
參考鏈接:
[1]https://hai.stanford.edu/news/introducing-foundation-model-transparency-index
[2]https://github.com/stanford-crfm/fmti
[3]https://www.theverge.com/2023/10/18/23922973/stanford-ai-foundation-model-transparency-index
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
