

 新火種
2023-09-11
新火種
2023-09-11 


圖解 72 個(gè)機(jī)器學(xué)習(xí)基礎(chǔ)知識(shí)點(diǎn)

來(lái)源:尤而小屋 R語(yǔ)言統(tǒng)計(jì)與繪圖本文約5500字,建議閱讀11分鐘本文梳理了機(jī)器學(xué)習(xí)最常見(jiàn)的知識(shí)要點(diǎn)。圖解機(jī)器學(xué)習(xí)算法系列 以圖解的生動(dòng)方式,闡述機(jī)器學(xué)習(xí)核心知識(shí) & 重要模型,并通過(guò)代碼講通應(yīng)用細(xì)節(jié)。

1. 機(jī)器學(xué)習(xí)概述
1)什么是機(jī)器學(xué)習(xí)
人工智能(Artificial intelligence)是研究、開(kāi)發(fā)用于模擬、延伸和擴(kuò)展人的智能的理論、方法、技術(shù)及應(yīng)用系統(tǒng)的一門新的技術(shù)科學(xué)。它是一個(gè)籠統(tǒng)而寬泛的概念,人工智能的最終目標(biāo)是使計(jì)算機(jī)能夠模擬人的思維方式和行為。
大概在上世紀(jì)50年代,人工智能開(kāi)始興起,但是受限于數(shù)據(jù)和硬件設(shè)備等限制,當(dāng)時(shí)發(fā)展緩慢。
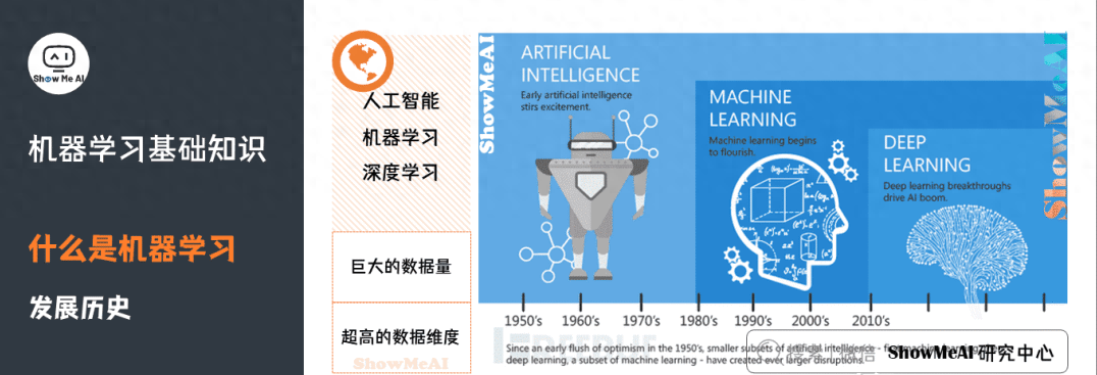
機(jī)器學(xué)習(xí)(Machine learning)是人工智能的子集,是實(shí)現(xiàn)人工智能的一種途徑,但并不是唯一的途徑。它是一門專門研究計(jì)算機(jī)怎樣模擬或?qū)崿F(xiàn)人類的學(xué)習(xí)行為,以獲取新的知識(shí)或技能,重新組織已有的知識(shí)結(jié)構(gòu)使之不斷改善自身的性能的學(xué)科。大概在上世紀(jì)80年代開(kāi)始蓬勃發(fā)展,誕生了一大批數(shù)學(xué)統(tǒng)計(jì)相關(guān)的機(jī)器學(xué)習(xí)模型。
深度學(xué)習(xí)(Deep learning)是機(jī)器學(xué)習(xí)的子集,靈感來(lái)自人腦,由人工神經(jīng)網(wǎng)絡(luò)(ANN)組成,它模仿人腦中存在的相似結(jié)構(gòu)。在深度學(xué)習(xí)中,學(xué)習(xí)是通過(guò)相互關(guān)聯(lián)的「神經(jīng)元」的一個(gè)深層的、多層的「網(wǎng)絡(luò)」來(lái)進(jìn)行的。「深度」一詞通常指的是神經(jīng)網(wǎng)絡(luò)中隱藏層的數(shù)量。大概在2012年以后爆炸式增長(zhǎng),廣泛應(yīng)用在很多的場(chǎng)景中。
讓我們看看國(guó)外知名學(xué)者對(duì)機(jī)器學(xué)習(xí)的定義:
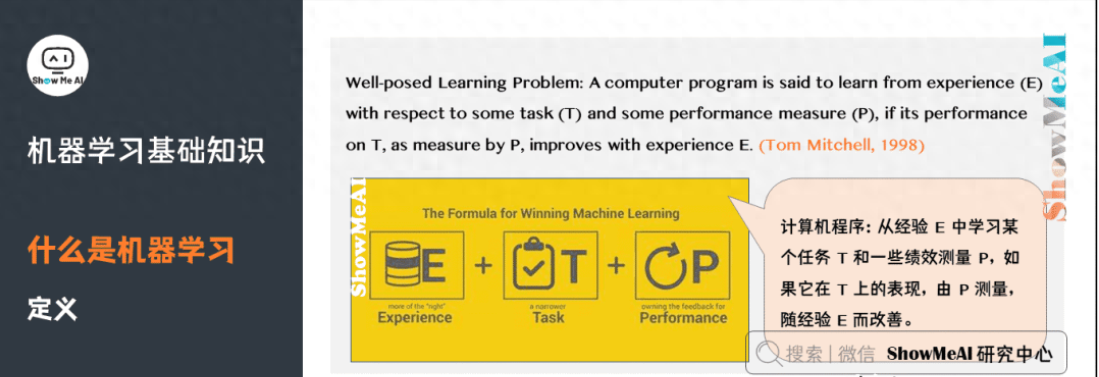
機(jī)器學(xué)習(xí)研究的是計(jì)算機(jī)怎樣模擬人類的學(xué)習(xí)行為,以獲取新的知識(shí)或技能,并重新組織已有的知識(shí)結(jié)構(gòu),使之不斷改善自身。
從實(shí)踐的意義上來(lái)說(shuō),機(jī)器學(xué)習(xí)是在大數(shù)據(jù)的支撐下,通過(guò)各種算法讓機(jī)器對(duì)數(shù)據(jù)進(jìn)行深層次的統(tǒng)計(jì)分析以進(jìn)行「自學(xué)」,使得人工智能系統(tǒng)獲得了歸納推理和決策能力。
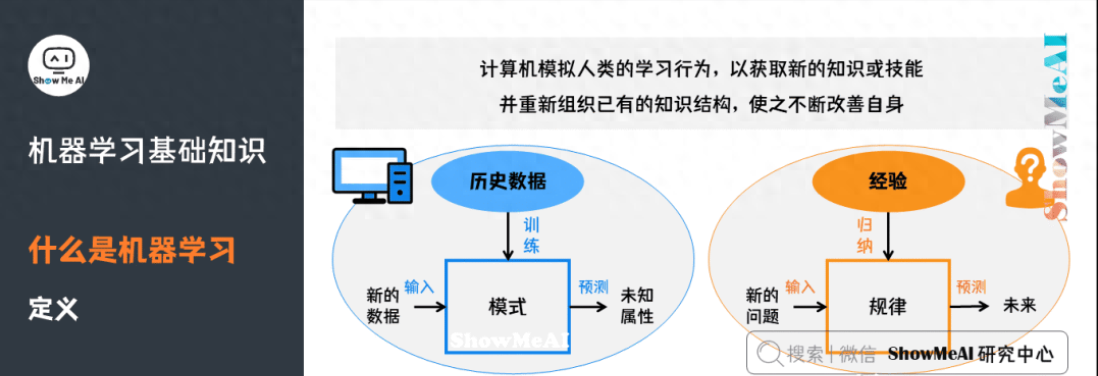
通過(guò)經(jīng)典的 垃圾郵件過(guò)濾 應(yīng)用,我們?cè)賮?lái)理解下機(jī)器學(xué)習(xí)的原理,以及定義中的T、E、P分別指代什么:

2)機(jī)器學(xué)習(xí)三要素
機(jī)器學(xué)習(xí)三要素包括數(shù)據(jù)、模型、算法。這三要素之間的關(guān)系,可以用下面這幅圖來(lái)表示:
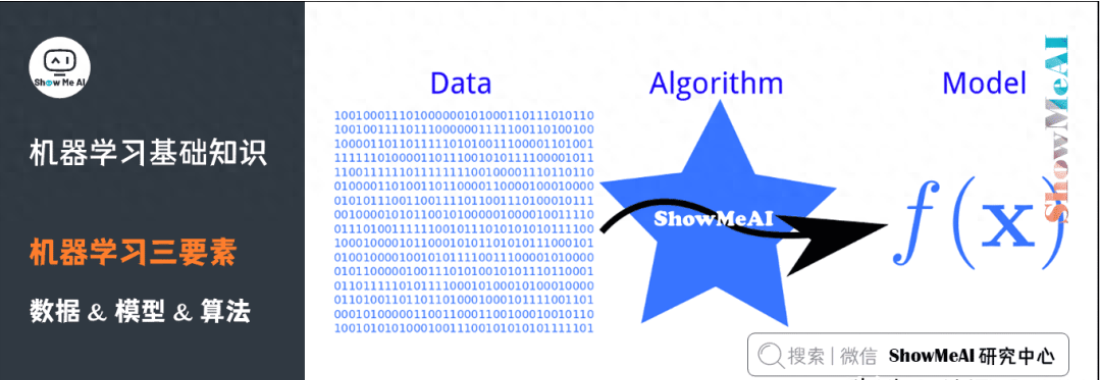
(1)數(shù)據(jù)
數(shù)據(jù)驅(qū)動(dòng):數(shù)據(jù)驅(qū)動(dòng)指的是我們基于客觀的量化數(shù)據(jù),通過(guò)主動(dòng)數(shù)據(jù)的采集分析以支持決策。與之相對(duì)的是經(jīng)驗(yàn)驅(qū)動(dòng),比如我們常說(shuō)的「拍腦袋」。

(2)模型&算法
模型:在AI數(shù)據(jù)驅(qū)動(dòng)的范疇內(nèi),模型指的是基于數(shù)據(jù)X做決策Y的假設(shè)函數(shù),可以有不同的形態(tài),計(jì)算型和規(guī)則型等。
算法:指學(xué)習(xí)模型的具體計(jì)算方法。統(tǒng)計(jì)學(xué)習(xí)基于訓(xùn)練數(shù)據(jù)集,根據(jù)學(xué)習(xí)策略,從假設(shè)空間中選擇最優(yōu)模型,最后需要考慮用什么樣的計(jì)算方法求解最優(yōu)模型。通常是一個(gè)最優(yōu)化的問(wèn)題。

3)機(jī)器學(xué)習(xí)發(fā)展歷程
人工智能一詞最早出現(xiàn)于1956年,用于探索一些問(wèn)題的有效解決方案。1960年,美國(guó)國(guó)防部借助「神經(jīng)網(wǎng)絡(luò)」這一概念,訓(xùn)練計(jì)算機(jī)模仿人類的推理過(guò)程。
2010年之前,谷歌、微軟等科技巨頭改進(jìn)了機(jī)器學(xué)習(xí)算法,將查詢的準(zhǔn)確度提升到了新的高度。而后,隨著數(shù)據(jù)量的增加、先進(jìn)的算法、計(jì)算和存儲(chǔ)容量的提高,機(jī)器學(xué)習(xí)得到了更進(jìn)一步的發(fā)展。
4)機(jī)器學(xué)習(xí)核心技術(shù)
分類:應(yīng)用以分類數(shù)據(jù)進(jìn)行模型訓(xùn)練,根據(jù)模型對(duì)新樣本進(jìn)行精準(zhǔn)分類與預(yù)測(cè)。
聚類:從海量數(shù)據(jù)中識(shí)別數(shù)據(jù)的相似性與差異性,并按照最大共同點(diǎn)聚合為多個(gè)類別。
異常檢測(cè):對(duì)數(shù)據(jù)點(diǎn)的分布規(guī)律進(jìn)行分析,識(shí)別與正常數(shù)據(jù)及差異較大的離群點(diǎn)。
回歸:根據(jù)對(duì)已知屬性值數(shù)據(jù)的訓(xùn)練,為模型尋找最佳擬合參數(shù),基于模型預(yù)測(cè)新樣本的輸出值。
5)機(jī)器學(xué)習(xí)基本流程
機(jī)器學(xué)習(xí)工作流(WorkFlow)包含數(shù)據(jù)預(yù)處理(Processing)、模型學(xué)習(xí)(Learning)、模型評(píng)估(Evaluation)、新樣本預(yù)測(cè)(Prediction)幾個(gè)步驟。
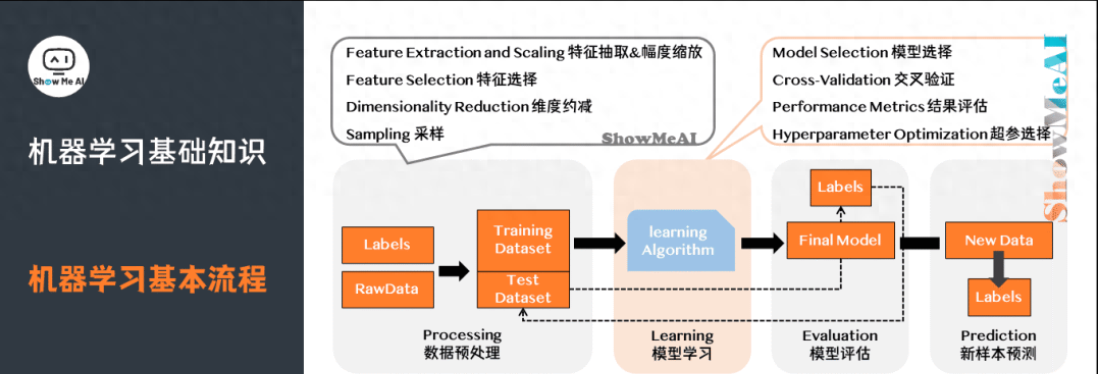
數(shù)據(jù)預(yù)處理:輸入(未處理的數(shù)據(jù) + 標(biāo)簽)→處理過(guò)程(特征處理+幅度縮放、特征選擇、維度約減、采樣)→輸出(測(cè)試集 + 訓(xùn)練集)。
模型學(xué)習(xí):模型選擇、交叉驗(yàn)證、結(jié)果評(píng)估、超參選擇。
模型評(píng)估:了解模型對(duì)于數(shù)據(jù)集測(cè)試的得分。
新樣本預(yù)測(cè):預(yù)測(cè)測(cè)試集。
6)機(jī)器學(xué)習(xí)應(yīng)用場(chǎng)景
作為一套數(shù)據(jù)驅(qū)動(dòng)的方法,機(jī)器學(xué)習(xí)已廣泛應(yīng)用于數(shù)據(jù)挖掘、計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理、生物特征識(shí)別、搜索引擎、醫(yī)學(xué)診斷、檢測(cè)信用卡欺詐、證券市場(chǎng)分析、DNA序列測(cè)序、語(yǔ)音和手寫識(shí)別和機(jī)器人等領(lǐng)域。

智能醫(yī)療:智能假肢、外骨骼、醫(yī)療保健機(jī)器人、手術(shù)機(jī)器人、智能健康管理等。
人臉識(shí)別:門禁系統(tǒng)、考勤系統(tǒng)、人臉識(shí)別防盜門、電子護(hù)照及身份證,還可以利用人臉識(shí)別系統(tǒng)和網(wǎng)絡(luò),在全國(guó)范圍內(nèi)搜捕逃犯。
機(jī)器人的控制領(lǐng)域:工業(yè)機(jī)器人、機(jī)械臂、多足機(jī)器人、掃地機(jī)器人、無(wú)人機(jī)等。
2.機(jī)器學(xué)習(xí)基本名詞
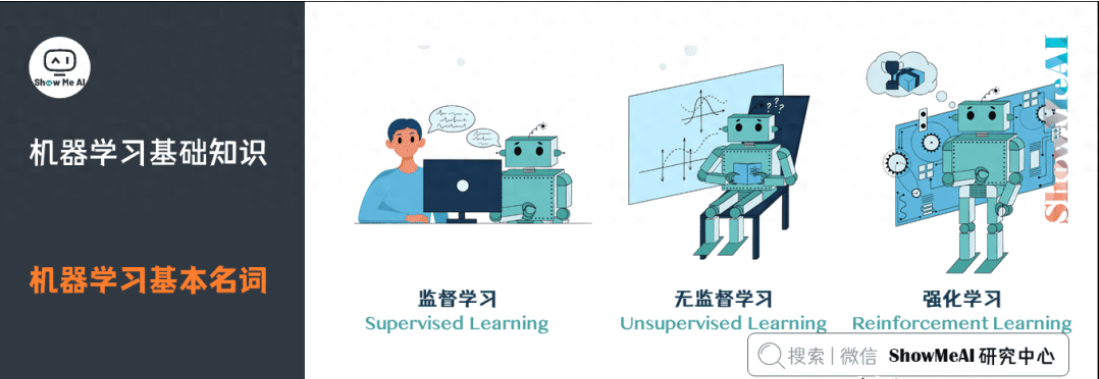
監(jiān)督學(xué)習(xí)(Supervised Learning):訓(xùn)練集有標(biāo)記信息,學(xué)習(xí)方式有分類和回歸。
無(wú)監(jiān)督學(xué)習(xí)(Unsupervised Learning):訓(xùn)練集沒(méi)有標(biāo)記信息,學(xué)習(xí)方式有聚類和降維。
強(qiáng)化學(xué)習(xí)(Reinforcement Learning):有延遲和稀疏的反饋標(biāo)簽的學(xué)習(xí)方式。
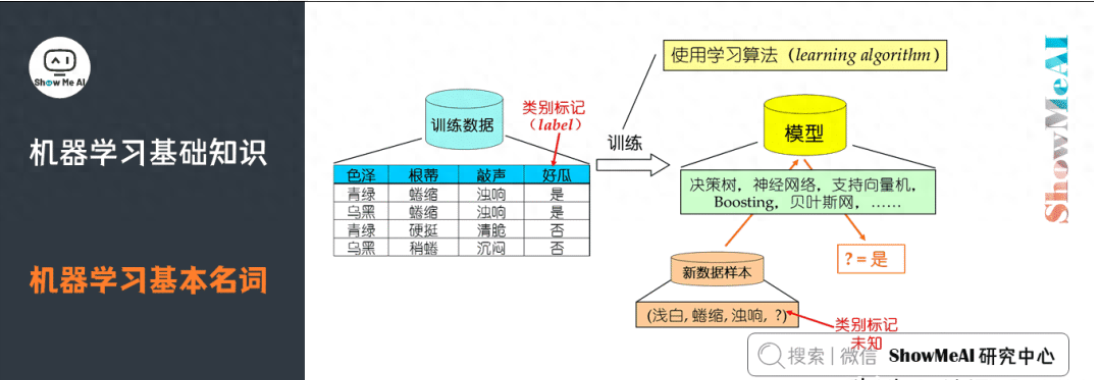
示例/樣本:上面一條數(shù)據(jù)集中的一條數(shù)據(jù)。
屬性/特征:「色澤」「根蒂」等。
屬性空間/樣本空間/輸入空間X:由全部屬性張成的空間。
特征向量:空間中每個(gè)點(diǎn)對(duì)應(yīng)的一個(gè)坐標(biāo)向量。
標(biāo)記:關(guān)于示例結(jié)果的信息,如((色澤=青綠,根蒂=蜷縮,敲聲=濁響),好瓜),其中「好瓜」稱為標(biāo)記。
分類:若要預(yù)測(cè)的是離散值,如「好瓜」,「壞瓜」,此類學(xué)習(xí)任務(wù)稱為分類。
假設(shè):學(xué)得模型對(duì)應(yīng)了關(guān)于數(shù)據(jù)的某種潛在規(guī)律。
真相:潛在規(guī)律自身。
學(xué)習(xí)過(guò)程:是為了找出或逼近真相。
泛化能力:學(xué)得模型適用于新樣本的能力。一般來(lái)說(shuō),訓(xùn)練樣本越大,越有可能通過(guò)學(xué)習(xí)來(lái)獲得具有強(qiáng)泛化能力的模型。
3.機(jī)器學(xué)習(xí)算法分類
1)機(jī)器學(xué)習(xí)算法依托的問(wèn)題場(chǎng)景
機(jī)器學(xué)習(xí)在近30多年已發(fā)展為一門多領(lǐng)域交叉學(xué)科,涉及概率論、統(tǒng)計(jì)學(xué)、逼近論、凸分析、計(jì)算復(fù)雜性理論等多門學(xué)科。機(jī)器學(xué)習(xí)理論主要是設(shè)計(jì)和分析一些讓計(jì)算機(jī)可以自動(dòng)「學(xué)習(xí)」的算法。
機(jī)器學(xué)習(xí)算法從數(shù)據(jù)中自動(dòng)分析獲得規(guī)律,并利用規(guī)律對(duì)未知數(shù)據(jù)進(jìn)行預(yù)測(cè)。
機(jī)器學(xué)習(xí)理論

機(jī)器學(xué)習(xí)最主要的類別有:監(jiān)督學(xué)習(xí)、無(wú)監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)。

監(jiān)督學(xué)習(xí):從給定的訓(xùn)練數(shù)據(jù)集中學(xué)習(xí)出一個(gè)函數(shù),當(dāng)新的數(shù)據(jù)到來(lái)時(shí),可以根據(jù)這個(gè)函數(shù)預(yù)測(cè)結(jié)果。監(jiān)督學(xué)習(xí)的訓(xùn)練集要求是包括輸入和輸出,也可以說(shuō)是特征和目標(biāo)。訓(xùn)練集中的目標(biāo)是由人標(biāo)注的。常見(jiàn)的監(jiān)督學(xué)習(xí)算法包括回歸分析和統(tǒng)計(jì)分類。
更多監(jiān)督學(xué)習(xí)的算法模型總結(jié),可以查看ShowMeAI的文章 AI知識(shí)技能速查 | 機(jī)器學(xué)習(xí)-監(jiān)督學(xué)習(xí)(公眾號(hào)不能跳轉(zhuǎn),本文鏈接見(jiàn)文末)。
無(wú)監(jiān)督學(xué)習(xí):與監(jiān)督學(xué)習(xí)相比,訓(xùn)練集沒(méi)有人為標(biāo)注的結(jié)果。常見(jiàn)的無(wú)監(jiān)督學(xué)習(xí)算法有生成對(duì)抗網(wǎng)絡(luò)(GAN)、聚類。
更多無(wú)監(jiān)督學(xué)習(xí)的算法模型總結(jié)可以查看ShowMeAI的文章 AI知識(shí)技能速查 | 機(jī)器學(xué)習(xí)-無(wú)監(jiān)督學(xué)習(xí)。
強(qiáng)化學(xué)習(xí):通過(guò)觀察來(lái)學(xué)習(xí)做成如何的動(dòng)作。每個(gè)動(dòng)作都會(huì)對(duì)環(huán)境有所影響,學(xué)習(xí)對(duì)象根據(jù)觀察到的周圍環(huán)境的反饋來(lái)做出判斷。
2)分類問(wèn)題
分類問(wèn)題是機(jī)器學(xué)習(xí)非常重要的一個(gè)組成部分。它的目標(biāo)是根據(jù)已知樣本的某些特征,判斷一個(gè)新的樣本屬于哪種已知的樣本類。分類問(wèn)題可以細(xì)分如下:
二分類問(wèn)題:表示分類任務(wù)中有兩個(gè)類別新的樣本屬于哪種已知的樣本類。
多類分類(Multiclass classification)問(wèn)題:表示分類任務(wù)中有多類別。
多標(biāo)簽分類(Multilabel classification)問(wèn)題:給每個(gè)樣本一系列的目標(biāo)標(biāo)簽。
了解更多機(jī)器學(xué)習(xí)分類算法:KNN算法、邏輯回歸算法、樸素貝葉斯算法、決策樹(shù)模型、隨機(jī)森林分類模型、GBDT模型、XGBoost模型、支持向量機(jī)模型等。(公眾號(hào)不能跳轉(zhuǎn),本文鏈接見(jiàn)文末)
3)回歸問(wèn)題
了解更多機(jī)器學(xué)習(xí)回歸算法:決策樹(shù)模型、隨機(jī)森林分類模型、GBDT模型、回歸樹(shù)模型、支持向量機(jī)模型等。
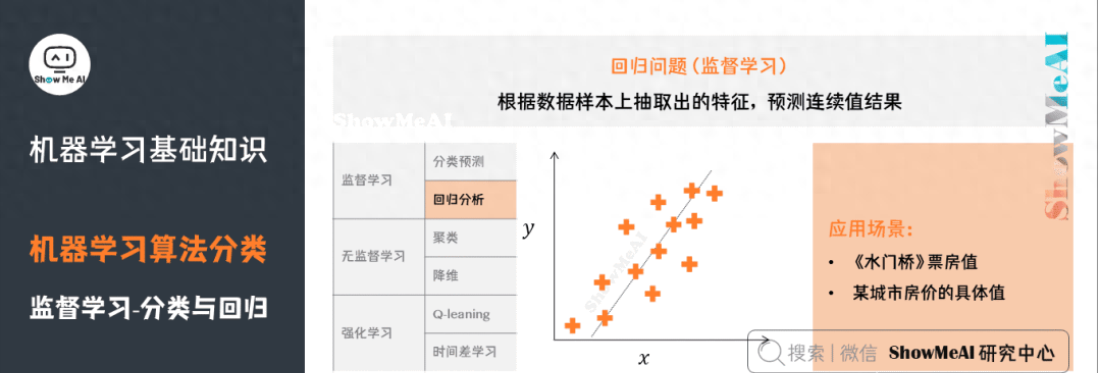
4)聚類問(wèn)題
了解更多機(jī)器學(xué)習(xí)聚類算法:聚類算法。
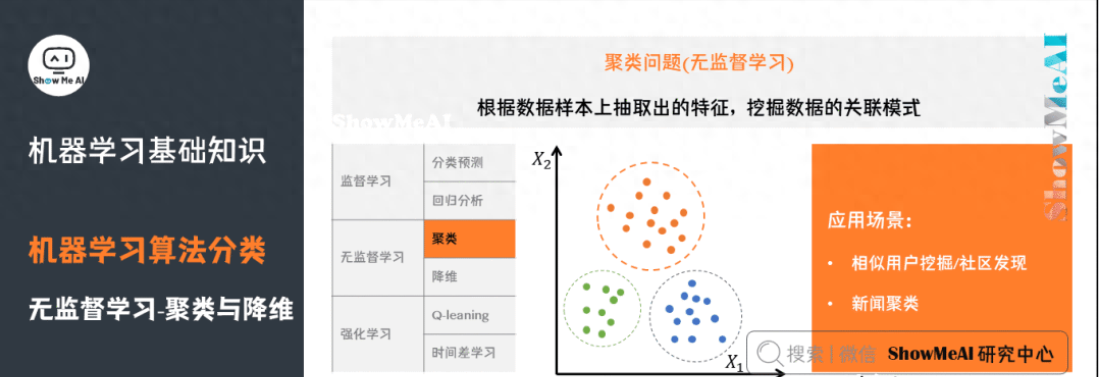
5)降維問(wèn)題
了解更多機(jī)器學(xué)習(xí)降維算法:PCA降維算法。

4.機(jī)器學(xué)習(xí)模型評(píng)估與選擇
1)機(jī)器學(xué)習(xí)與數(shù)據(jù)擬合
機(jī)器學(xué)習(xí)最典型的監(jiān)督學(xué)習(xí)為分類與回歸問(wèn)題。分類問(wèn)題中,我們學(xué)習(xí)出來(lái)一條「決策邊界」完成數(shù)據(jù)區(qū)分;在回歸問(wèn)題中,我們學(xué)習(xí)出擬合樣本分布的曲線。
2)訓(xùn)練集與數(shù)據(jù)集
我們以房?jī)r(jià)預(yù)估為例,講述一下涉及的概念。
訓(xùn)練集(Training Set):幫助訓(xùn)練模型,簡(jiǎn)單的說(shuō)就是通過(guò)訓(xùn)練集的數(shù)據(jù)讓確定擬合曲線的參數(shù)。
測(cè)試集(Test Set):為了測(cè)試已經(jīng)訓(xùn)練好的模型的精確度。
當(dāng)然,test set這并不能保證模型的正確性,只是說(shuō)相似的數(shù)據(jù)用此模型會(huì)得出相似的結(jié)果。因?yàn)樵谟?xùn)練模型的時(shí)候,參數(shù)全是根據(jù)現(xiàn)有訓(xùn)練集里的數(shù)據(jù)進(jìn)行修正、擬合,有可能會(huì)出現(xiàn)過(guò)擬合的情況,即這個(gè)參數(shù)僅對(duì)訓(xùn)練集里的數(shù)據(jù)擬合比較準(zhǔn)確,這個(gè)時(shí)候再有一個(gè)數(shù)據(jù)需要利用模型預(yù)測(cè)結(jié)果,準(zhǔn)確率可能就會(huì)很差。
3)經(jīng)驗(yàn)誤差
在訓(xùn)練集的數(shù)據(jù)上進(jìn)行學(xué)習(xí)。模型在訓(xùn)練集上的誤差稱為「經(jīng)驗(yàn)誤差」(Empirical Error)。但是經(jīng)驗(yàn)誤差并不是越小越好,因?yàn)槲覀兿M谛碌臎](méi)有見(jiàn)過(guò)的數(shù)據(jù)上,也能有好的預(yù)估結(jié)果。
4)過(guò)擬合
過(guò)擬合,指的是模型在訓(xùn)練集上表現(xiàn)的很好,但是在交叉驗(yàn)證集合測(cè)試集上表現(xiàn)一般,也就是說(shuō)模型對(duì)未知樣本的預(yù)測(cè)表現(xiàn)一般,泛化(Generalization)能力較差。
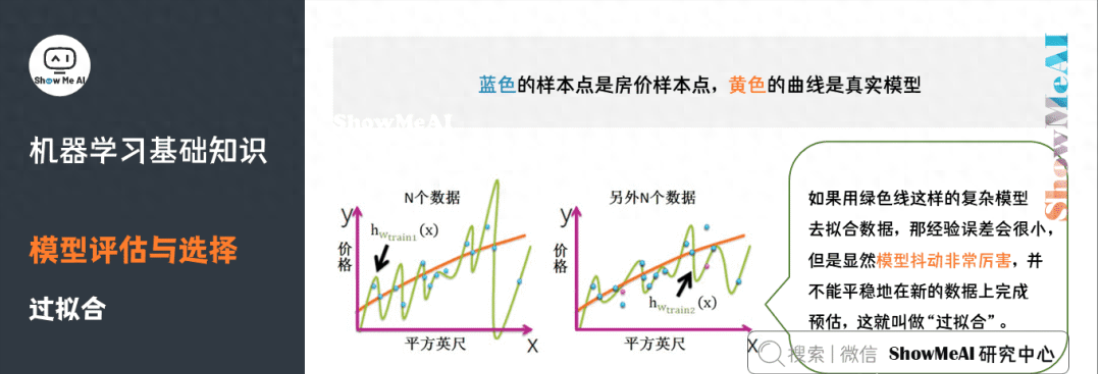
如何防止過(guò)擬合呢?一般的方法有Early Stopping、數(shù)據(jù)集擴(kuò)增(Data Augmentation)、正則化、Dropout等。
正則化:指的是在目標(biāo)函數(shù)后面添加一個(gè)正則化項(xiàng),一般有L1正則化與L2正則化。L1正則是基于L1范數(shù),即在目標(biāo)函數(shù)后面加上參數(shù)的L1范數(shù)和項(xiàng),即參數(shù)絕對(duì)值和與參數(shù)的積項(xiàng)。
數(shù)據(jù)集擴(kuò)增:即需要得到更多的符合要求的數(shù)據(jù),即和已有的數(shù)據(jù)是獨(dú)立同分布的,或者近似獨(dú)立同分布的。一般方法有:從數(shù)據(jù)源頭采集更多數(shù)據(jù)、復(fù)制原有數(shù)據(jù)并加上隨機(jī)噪聲、重采樣、根據(jù)當(dāng)前數(shù)據(jù)集估計(jì)數(shù)據(jù)分布參數(shù),使用該分布產(chǎn)生更多數(shù)據(jù)等。
DropOut:通過(guò)修改神經(jīng)網(wǎng)絡(luò)本身結(jié)構(gòu)來(lái)實(shí)現(xiàn)的。
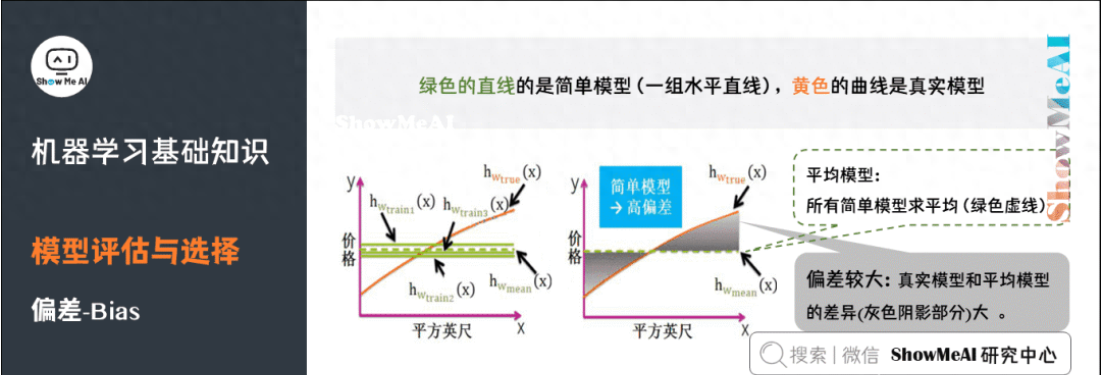
5)偏差
偏差(Bias),它通常指的是模型擬合的偏差程度。給定無(wú)數(shù)套訓(xùn)練集而期望擬合出來(lái)的模型就是平均模型。偏差就是真實(shí)模型和平均模型的差異。
簡(jiǎn)單模型是一組直線,平均之后得到的平均模型是一條直的虛線,與真實(shí)模型曲線的差別較大(灰色陰影部分較大)。因此,簡(jiǎn)單模型通常高偏差。
復(fù)雜模型是一組起伏很大波浪線,平均之后最大值和最小組都會(huì)相互抵消,和真實(shí)模型的曲線差別較小,因此復(fù)雜模型通常低偏差(見(jiàn)黃色曲線和綠色虛線幾乎重合)。
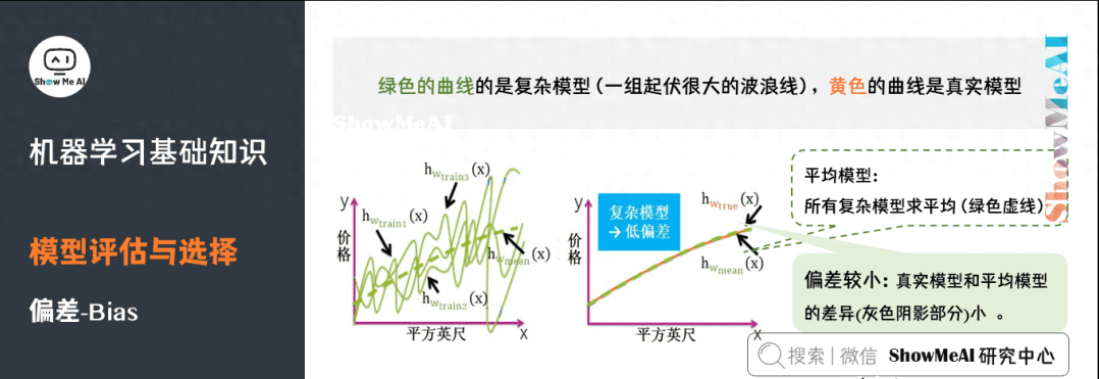
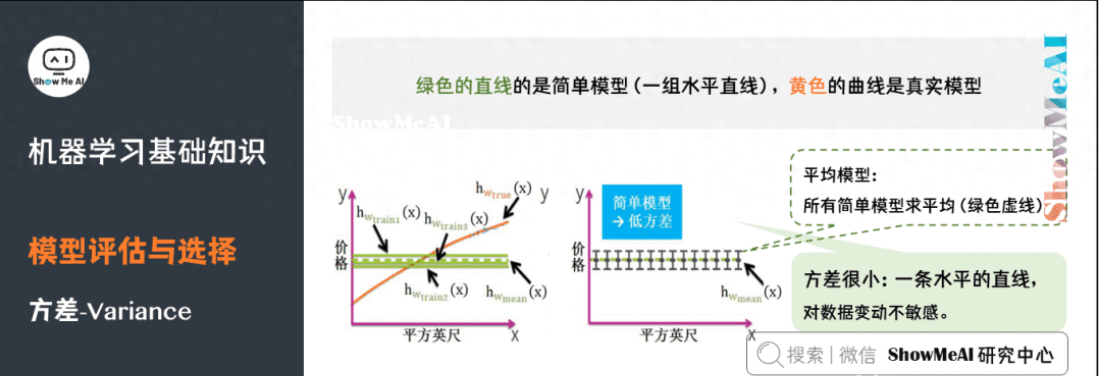
6)方差
方差(Variance),它通常指的是模型的平穩(wěn)程度(簡(jiǎn)單程度)。簡(jiǎn)單模型的對(duì)應(yīng)的函數(shù)如出一轍,都是水平直線,而且平均模型的函數(shù)也是一條水平直線,因此簡(jiǎn)單模型的方差很小,并且對(duì)數(shù)據(jù)的變動(dòng)不敏感。
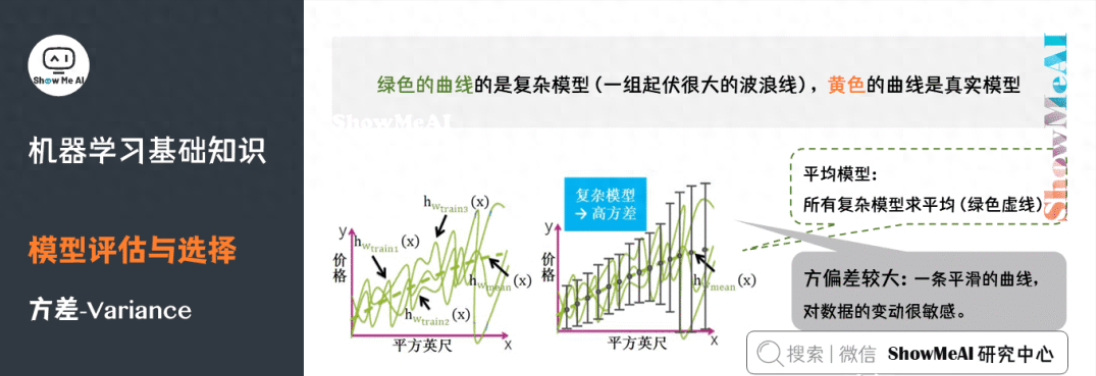
復(fù)雜模型的對(duì)應(yīng)的函數(shù)千奇百怪,毫無(wú)任何規(guī)則,但平均模型的函數(shù)也是一條平滑的曲線,因此復(fù)雜模型的方差很大,并且對(duì)數(shù)據(jù)的變動(dòng)很敏感。
7)偏差與方差的平衡
8)性能度量指標(biāo)
性能度量是衡量模型泛化能力的數(shù)值評(píng)價(jià)標(biāo)準(zhǔn),反映了當(dāng)前問(wèn)題(任務(wù)需求)。使用不同的性能度量可能會(huì)導(dǎo)致不同的評(píng)判結(jié)果。更詳細(xì)的內(nèi)容可見(jiàn) 模型評(píng)估方法與準(zhǔn)則(鏈接見(jiàn)文末)。
(1)回歸問(wèn)題
關(guān)于模型「好壞」的判斷,不僅取決于算法和數(shù)據(jù),還取決于當(dāng)前任務(wù)需求。回歸問(wèn)題常用的性能度量指標(biāo)有:平均絕對(duì)誤差、均方誤差、均方根誤差、R平方等。
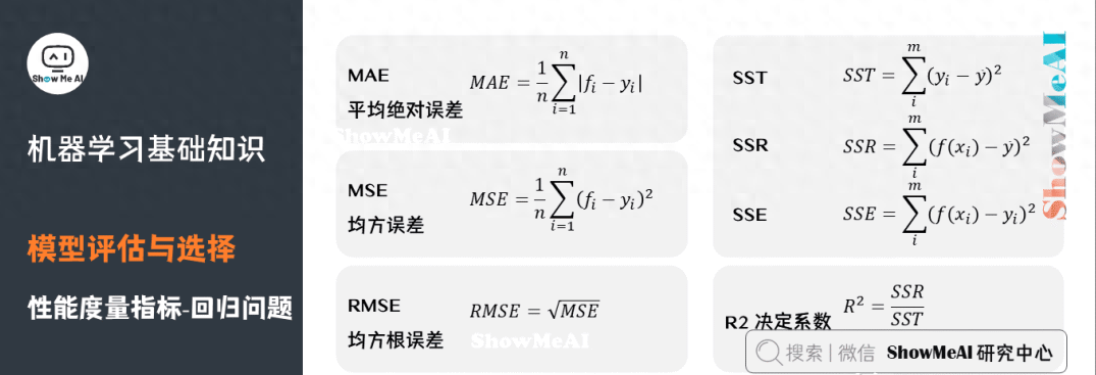
平均絕對(duì)誤差(Mean Absolute Error,MAE),又叫平均絕對(duì)離差,是所有標(biāo)簽值與回歸模型預(yù)測(cè)值的偏差的絕對(duì)值的平均。
平均絕對(duì)百分誤差(Mean Absolute Percentage Error,MAPE)是對(duì)MAE的一種改進(jìn),考慮了絕對(duì)誤差相對(duì)真實(shí)值的比例。
均方誤差(Mean Square Error,MSE)相對(duì)于平均絕對(duì)誤差而言,均方誤差求的是所有標(biāo)簽值與回歸模型預(yù)測(cè)值的偏差的平方的平均。
均方根誤差(Root-Mean-Square Error,RMSE),也稱標(biāo)準(zhǔn)誤差,是在均方誤差的基礎(chǔ)上進(jìn)行開(kāi)方運(yùn)算。RMSE會(huì)被用來(lái)衡量觀測(cè)值同真值之間的偏差。
R平方,決定系數(shù),反映因變量的全部變異能通過(guò)目前的回歸模型被模型中的自變量解釋的比例。比例越接近于1,表示當(dāng)前的回歸模型對(duì)數(shù)據(jù)的解釋越好,越能精確描述數(shù)據(jù)的真實(shí)分布。
(2)分類問(wèn)題
分類問(wèn)題常用的性能度量指標(biāo)包括錯(cuò)誤率(Error Rate)、精確率(Accuracy)、查準(zhǔn)率(Precision)、查全率(Recall)、F1、ROC曲線、AUC曲線和R平方等。更詳細(xì)的內(nèi)容可見(jiàn) 模型評(píng)估方法與準(zhǔn)則(鏈接見(jiàn)文末)。
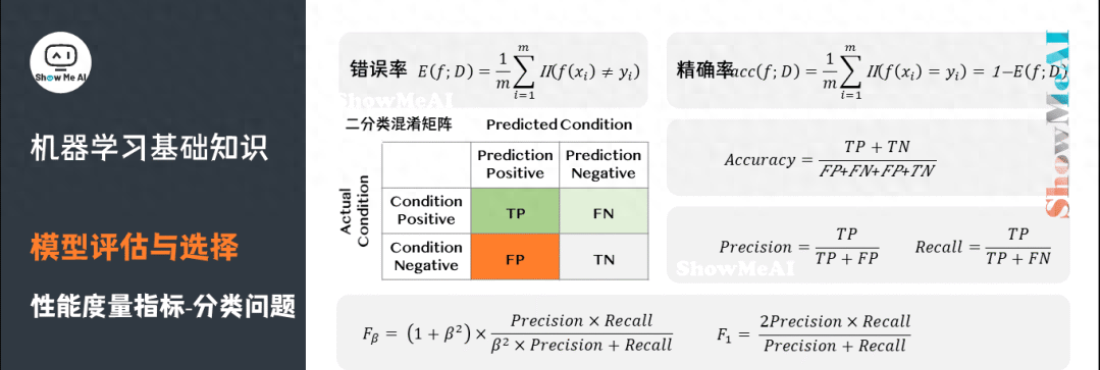
錯(cuò)誤率:分類錯(cuò)誤的樣本數(shù)占樣本總數(shù)的比例。
精確率:分類正確的樣本數(shù)占樣本總數(shù)的比例。
查準(zhǔn)率(也稱準(zhǔn)確率),即在檢索后返回的結(jié)果中,真正正確的個(gè)數(shù)占你認(rèn)為是正確的結(jié)果的比例。
查全率(也稱召回率),即在檢索結(jié)果中真正正確的個(gè)數(shù),占整個(gè)數(shù)據(jù)集(檢索到的和未檢索到的)中真正正確個(gè)數(shù)的比例。
F1是一個(gè)綜合考慮查準(zhǔn)率與查全率的度量,其基于查準(zhǔn)率與查全率的調(diào)和平均定義:即:F1度量的一般形式-Fβ,能讓我們表達(dá)出對(duì)查準(zhǔn)率、查全率的不同偏好。
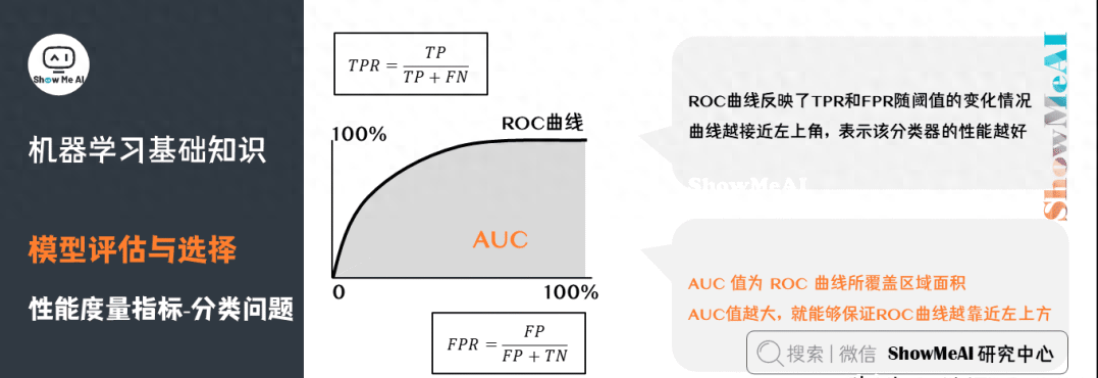
ROC曲線(Receiver Operating Characteristic Curve)全稱是「受試者工作特性曲線」。綜合考慮了概率預(yù)測(cè)排序的質(zhì)量,體現(xiàn)了學(xué)習(xí)器在不同任務(wù)下的「期望泛化性能」的好壞。ROC曲線的縱軸是「真正例率」(TPR),橫軸是「假正例率」(FPR)。
AUC(Area Under ROC Curve)是ROC曲線下面積,代表了樣本預(yù)測(cè)的排序質(zhì)量。
從一個(gè)比較高的角度來(lái)認(rèn)識(shí)AUC:仍然以異常用戶的識(shí)別為例,高的AUC值意味著,模型在能夠盡可能多地識(shí)別異常用戶的情況下,仍然對(duì)正常用戶有著一個(gè)較低的誤判率(不會(huì)因?yàn)闉榱俗R(shí)別異常用戶,而將大量的正常用戶給誤判為異常。
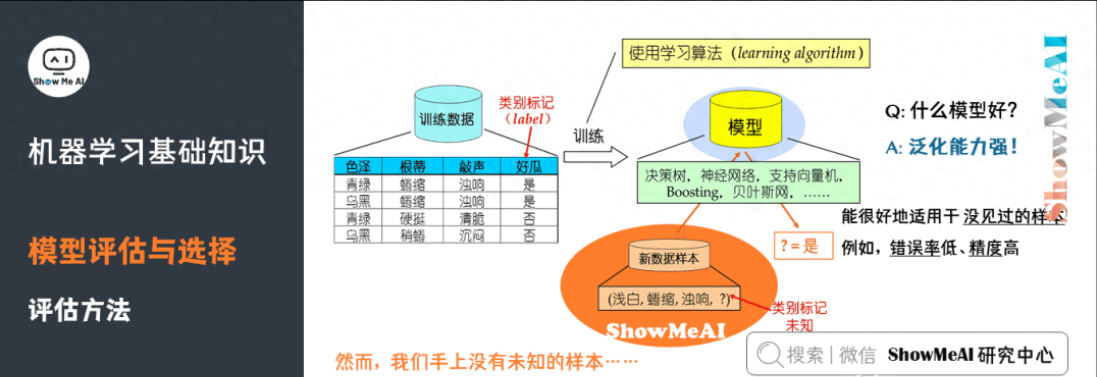
9)評(píng)估方法
我們手上沒(méi)有未知的樣本,如何可靠地評(píng)估?關(guān)鍵是要獲得可靠的「測(cè)試集數(shù)據(jù)」(Test Set),即測(cè)試集(用于評(píng)估)應(yīng)該與訓(xùn)練集(用于模型學(xué)習(xí))「互斥」。
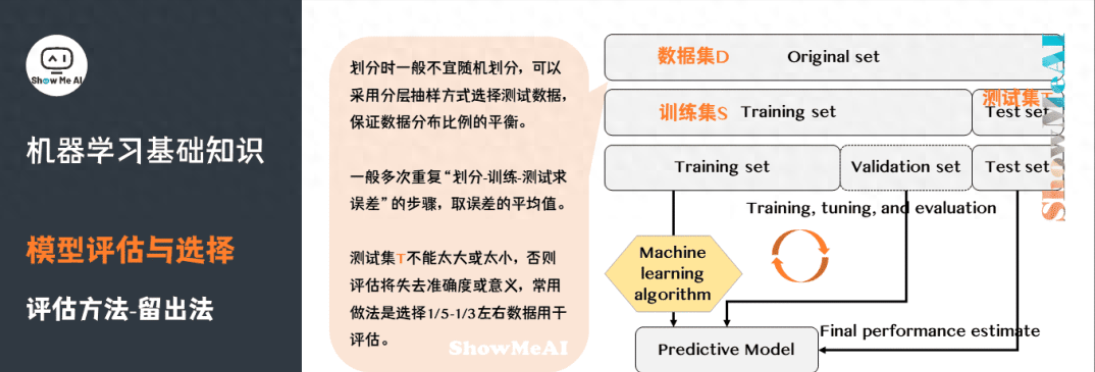
常見(jiàn)的評(píng)估方法有:留出法(Hold-out)、交叉驗(yàn)證法( Cross Validation)、自助法(Bootstrap)。更詳細(xì)的內(nèi)容可見(jiàn) 模型評(píng)估方法與準(zhǔn)則(鏈接見(jiàn)文末)。
留出法(Hold-out)是機(jī)器學(xué)習(xí)中最常見(jiàn)的評(píng)估方法之一,它會(huì)從訓(xùn)練數(shù)據(jù)中保留出驗(yàn)證樣本集,這部分?jǐn)?shù)據(jù)不用于訓(xùn)練,而用于模型評(píng)估。
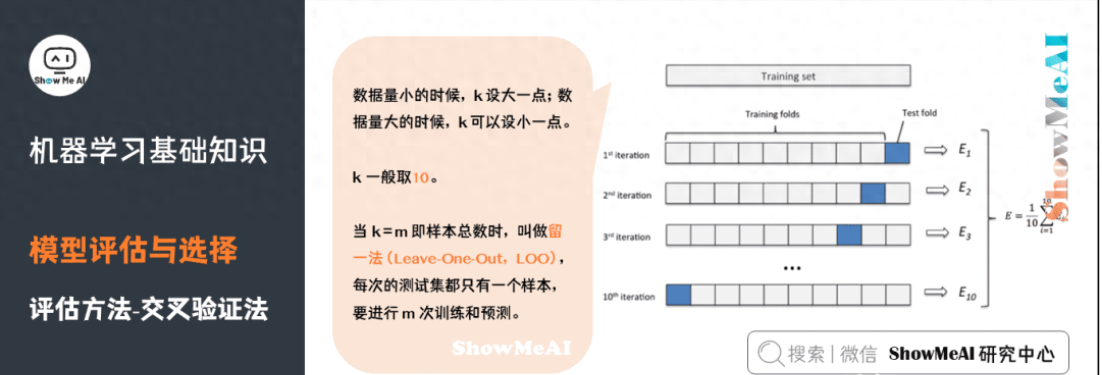
機(jī)器學(xué)習(xí)中,另外一種比較常見(jiàn)的評(píng)估方法是交叉驗(yàn)證法(Cross Validation)。k 折交叉驗(yàn)證對(duì) k 個(gè)不同分組訓(xùn)練的結(jié)果進(jìn)行平均來(lái)減少方差,因此模型的性能對(duì)數(shù)據(jù)的劃分就不那么敏感,對(duì)數(shù)據(jù)的使用也會(huì)更充分,模型評(píng)估結(jié)果更加穩(wěn)定。
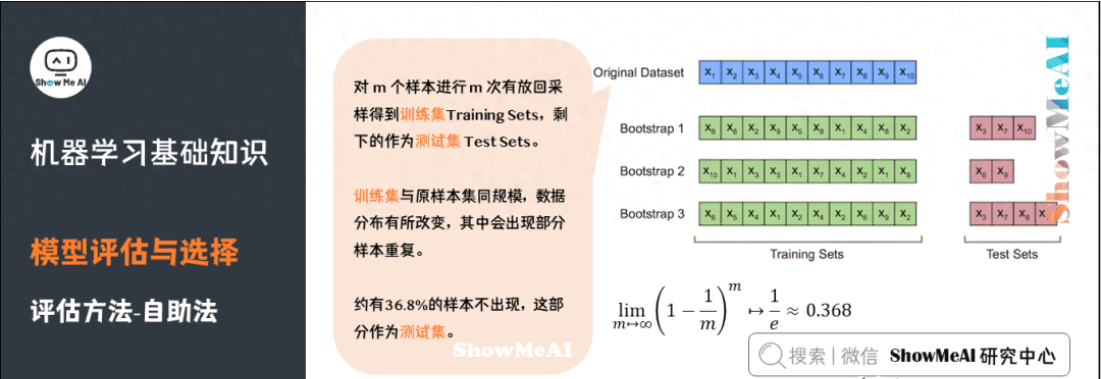
自助法(Bootstrap)是一種用小樣本估計(jì)總體值的一種非參數(shù)方法,在進(jìn)化和生態(tài)學(xué)研究中應(yīng)用十分廣泛。
Bootstrap通過(guò)有放回抽樣生成大量的偽樣本,通過(guò)對(duì)偽樣本進(jìn)行計(jì)算,獲得統(tǒng)計(jì)量的分布,從而估計(jì)數(shù)據(jù)的整體分布。
10)模型調(diào)優(yōu)與選擇準(zhǔn)則
我們希望找到對(duì)當(dāng)前問(wèn)題表達(dá)能力好,且模型復(fù)雜度較低的模型:
表達(dá)力好的模型,可以較好地對(duì)訓(xùn)練數(shù)據(jù)中的規(guī)律和模式進(jìn)行學(xué)習(xí);復(fù)雜度低的模型,方差較小,不容易過(guò)擬合,有較好的泛化表達(dá)。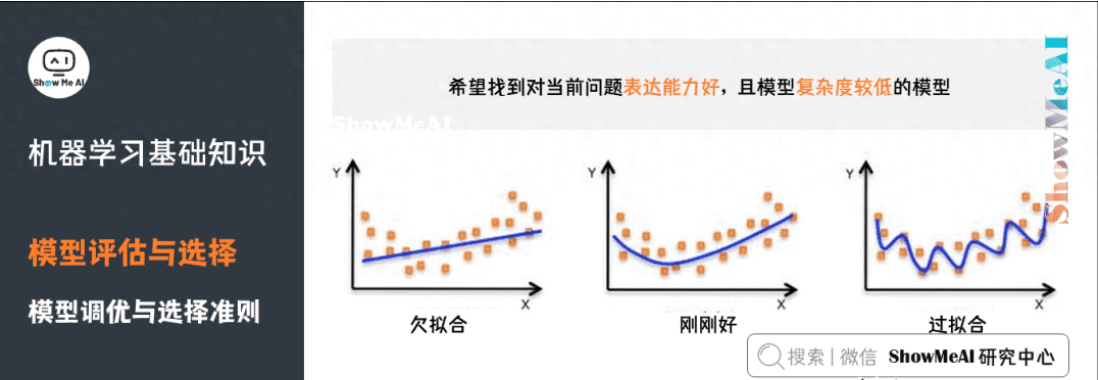
11)如何選擇最優(yōu)的模型
(1)驗(yàn)證集評(píng)估選擇
切分?jǐn)?shù)據(jù)為訓(xùn)練集和驗(yàn)證集。對(duì)于準(zhǔn)備好的候選超參數(shù),在訓(xùn)練集上進(jìn)行模型,在驗(yàn)證集上評(píng)估。
(2)網(wǎng)格搜索/隨機(jī)搜索交叉驗(yàn)證
通過(guò)網(wǎng)格搜索/隨機(jī)搜索產(chǎn)出候選的超參數(shù)組。對(duì)參數(shù)組的每一組超參數(shù),使用交叉驗(yàn)證評(píng)估效果。選出效果最好的超參數(shù)。
(3)貝葉斯優(yōu)化
基于貝葉斯優(yōu)化的超參數(shù)調(diào)優(yōu)。
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
