

 新火種
2023-10-21
新火種
2023-10-21 


Transformer王者歸來!無需修改任何模塊,時序預測全面領先
原文來源:新智元

圖片來源:由無界 AI生成
近年來,Transformer在自然語言處理以及計算機視覺任務中取得了不斷突破,成為深度學習領域的基礎模型。
受此啟發(fā),眾多Transformer模型變體在時間序列領域中被提出。
然而,最近越來越多的研究發(fā)現(xiàn),使用簡單的基于線性層搭建的預測模型,就能取得比各類魔改Transformer更好的效果。

最近,針對有關Transformer在時序預測領域有效性的質(zhì)疑,清華大學軟件學院機器學習實驗室和螞蟻集團學者合作發(fā)布了一篇時間序列預測工作,在Reddit等論壇上引發(fā)熱烈討論。
其中,作者提出的iTransformer,考慮多維時間序列的數(shù)據(jù)特性,未修改任何Transformer模塊,而是打破常規(guī)模型結(jié)構,在復雜時序預測任務中取得了全面領先,試圖解決Transformer建模時序數(shù)據(jù)的痛點。

論文地址:https://arxiv.org/abs/2310.06625
代碼實現(xiàn):https://github.com/thuml/Time-Series-Library
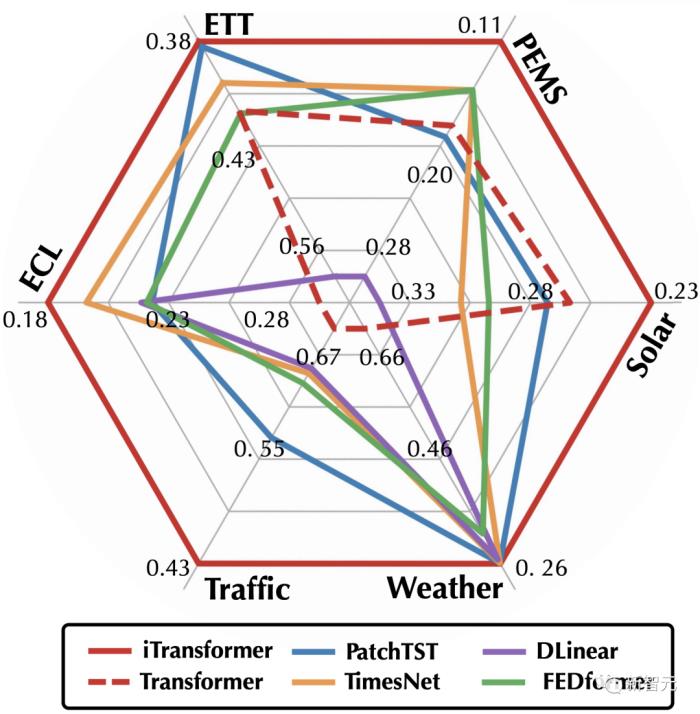
在iTransformer的加持下,Transformer完成了在時序預測任務上的全面反超。
問題背景
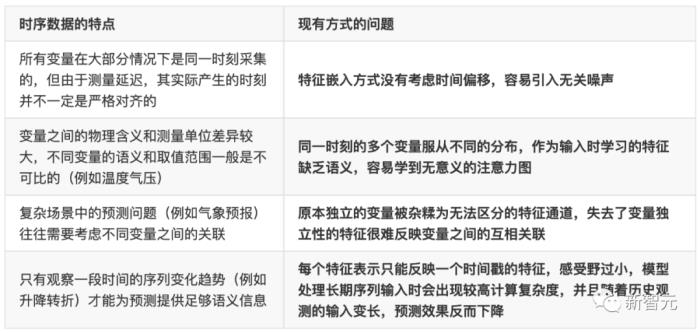
現(xiàn)實世界的時序數(shù)據(jù)往往是多維的,除了時間維之外,還包括變量維度。
每個變量可以代表不同的觀測物理量,例如氣象預報中使用的多個氣象指標(風速,溫度,濕度,氣壓等),也可以代表不同的觀測主體,例如發(fā)電廠不同設備的每小時發(fā)電量等。
一般而言,不同的變量具有完全不同的物理含義,即使語義相同,其測量單位也可能完全不同。
以往基于Transformer的預測模型通常先將同一時刻下的多個變量嵌入到高維特征表示(Temporal Token),使用前饋網(wǎng)絡(Feed-forward Network)編碼每個時刻的特征,并使用注意力模塊(Attention)學習不同時刻之間的相互關聯(lián)。
然而,這種方式可能會存在如下問題:
設計思路
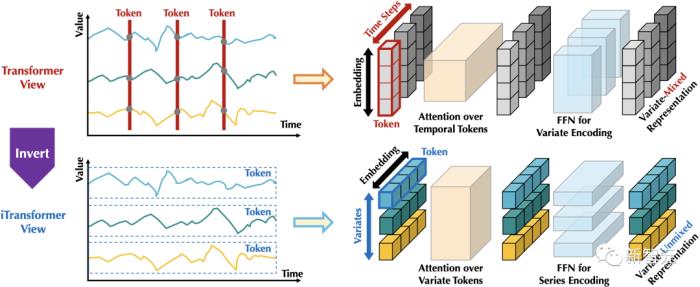
不同于自然語言中的每個詞(Token)具有較強的獨立語義信息,在同為序列的時序數(shù)據(jù)上,現(xiàn)有Transformer視角下看到的每個「詞」(Temporal Token)往往缺乏語義性,并且面臨時間戳非對齊與感受野過小等問題。
也就是說,傳統(tǒng)Transformer的在時間序列上的建模能力被極大程度地弱化了。
為此,作者提出了一種全新的倒置(Inverted)視角。
如下圖,通過倒置Transformer原本的模塊,iTransformer先將同一變量的整條序列映射成高維特征表示(Variate Token),得到的特征向量以變量為描述的主體,獨立地刻畫了其反映的歷史過程。
此后,注意力模塊可天然地建模變量之間的相關性(Mulitivariate Correlation),前饋網(wǎng)絡則在時間維上逐層編碼歷史觀測的特征,并且將學到的特征映射為未來的預測結(jié)果。
相比之下,以往沒有在時序數(shù)據(jù)上深入探究的層歸一化(LayerNorm),也將在消除變量之間分布差異上發(fā)揮至關重要的作用。
?iTransformer
整體結(jié)構
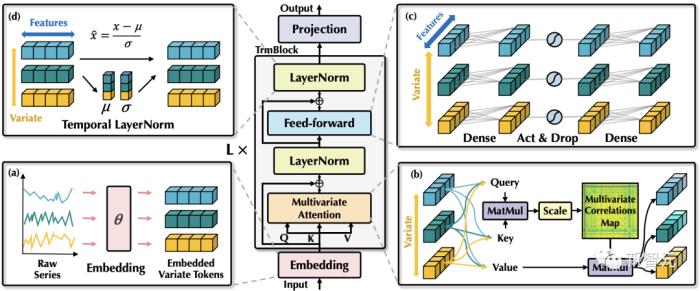
不同于以往Transformer預測模型使用的較為復雜的編碼器-解碼器結(jié)構,iTransformer僅包含編碼器,包括嵌入層(Embedding),投影層(Projector)和??個可堆疊的Transformer模塊(TrmBlock)。
建模變量的特征表示
對于一個時間長度為??、變量數(shù)為??的多維時間序列??,文章使用??表示同一時刻的所有變量,以及??表示同一變量的整條歷史觀測序列。
考慮到??比??具有更強的語義以及相對一致的測量單位,不同于以往對??進行特征嵌入的方式,該方法使用嵌入層對每個??獨立地進行特征映射,獲得??個變量的特征表示??,其中??蘊含了變量在過去時間內(nèi)的時序變化。
該特征表示將在各層Transformer模塊中,首先通過自注意力機制進行變量之間的信息交互,使用層歸一化統(tǒng)一不同變量的特征分布,以及在前饋網(wǎng)絡中進行全連接式的特征編碼。最終通過投影層映射為預測結(jié)果。
基于上述流程,整個模型的實現(xiàn)方式非常簡單,計算過程可表示為:
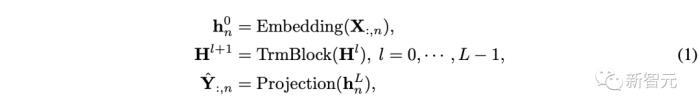
其中??即為每個變量對應的預測結(jié)果,嵌入層和投影層均基于多層感知機(MLP)實現(xiàn)。
值得注意的是,因為時間點之間的順序已經(jīng)隱含在神經(jīng)元的排列順序中,模型不需要引入Transformer中的位置編碼(Position Embedding)。
模塊分析
調(diào)轉(zhuǎn)了Transformer模塊處理時序數(shù)據(jù)的維度后,這篇工作重新審視了各模塊在iTransformer中的職責。
1. 層歸一化:層歸一化的提出最初是為了提高深度網(wǎng)絡的訓練的穩(wěn)定性與收斂性。
在以往Transformer中,該模塊將同一時刻的的多個變量進行歸一化,使每個變量雜糅無法區(qū)分。一旦收集到的數(shù)據(jù)沒有按時間對齊,該操作還將引入非因果或延遲過程之間的交互噪聲。
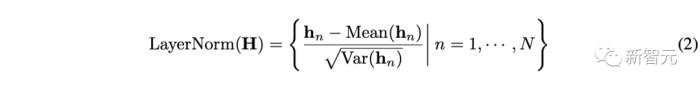
而在倒置版本中(公式如上),層歸一化應用于每個變量的特征表示(Variate Token),讓所有變量的特征通道都處于相對統(tǒng)一的分布下。
這種歸一化的思想在處理時間序列非平穩(wěn)問題時已經(jīng)被廣泛證明是有效的,只是在iTransformer中可以自然而然的通過層歸一化實現(xiàn)。
此外,由于所有變量的特征表示都被歸一化到正態(tài)分布,由變量取值范圍不同造成的差異可以減弱。
相反,在此前的結(jié)構中,所有時間戳的特征表示(Temporal Token)將被統(tǒng)一標準化,導致模型實際看到的是過平滑的時間序列。
2. 前饋網(wǎng)絡:Transformer利用前饋網(wǎng)絡編碼詞向量。
此前模型中形成「詞」向量的是同一時間采集的多個變量,他們的生成時間可能并不一致,并且反映一個時間步的「詞」很難提供足夠的語義。
在倒置版本中,形成「詞」向量的是同一變量的整條序列,基于多層感知機的萬能表示定理,其具備足夠大的模型容量來提取在歷史觀測和未來預測中共享的時間特征,并使用特征外推為預測結(jié)果。
另一個使用前饋網(wǎng)絡建模時間維的依據(jù)來自最近的研究,研究發(fā)現(xiàn)線性層擅長學習任何時間序列都具備的時間特征。
對此,作者提出了一種合理的解釋:線性層的神經(jīng)元可以學習到如何提取任意時間序列的內(nèi)在屬性,如幅值,周期性,甚至頻率譜(傅立葉變換實質(zhì)是在原始序列上的全連接映射)。
因此相較以往Transformer使用注意力機制建模時序依賴的做法,使用前饋網(wǎng)絡更有可能完成在未見過的序列上的泛化。
3. 自注意力:自注意力模塊在該模型中用于建模不同變量的相關性,這種相關性在有物理知識驅(qū)動的復雜預測場景中(例如氣象預報)是極其重要的。
作者發(fā)現(xiàn)自注意力圖(Attention Map)的每個位置滿足如下公式:
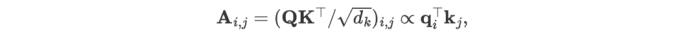
其中??對應任意兩個變量的Query和Key向量,作者認為整個注意力圖可以在一定程度上揭示變量的相關性,并且在后續(xù)基于注意力圖的加權操作中,高度相關的變量將在與其Value向量的交互中獲得更大的權重,因此這種設計對多維時序數(shù)據(jù)建模更為自然和可解釋。
綜上所述,在iTransformer中,層歸一化,前饋網(wǎng)絡以及自注意力模塊考慮了多維時序數(shù)據(jù)本身的特點,三者系統(tǒng)性互相配合,適應不同維度的建模需求,起到1+1+1 > 3的效果。
實驗分析
作者在六大多維時序預測基準上進行了廣泛的實驗,同時在支付寶交易平臺的線上服務負載預測任務場景的數(shù)據(jù)(Market)中進行了預測。
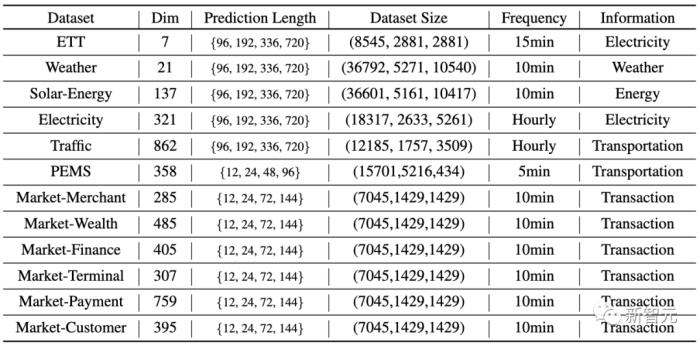
實驗部分對比了10種不同的預測模型,包含領域代表性Transformer模型:PatchTST(2023)、Crossformer(2023)、FEDformer(2022)、Stationary(2022)、Autoformer(2021)、Informer(2021);線性預測模型:TiDE(2023)、DLinear(2023);TCN系模型:TimesNet(2023)、SCINet(2022)。
此外,文章分析了模塊倒置給眾多Transformer變體帶來的增益,包括通用的效果提升,泛化到未知變量以及更加充分地利用歷史觀測等。
時序預測
如開篇雷達圖所示,iTransformer在六大測試基準中均達到了SOTA,并在Market數(shù)據(jù)的28/30個場景取得最優(yōu)效果(詳見論文附錄)。
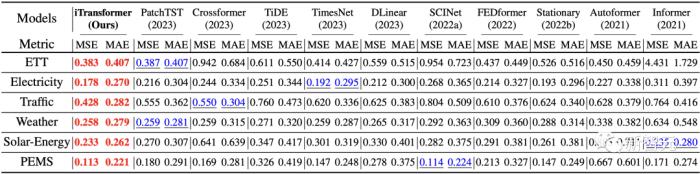
在長時預測以及多維時間預測這一充滿挑戰(zhàn)的場景中,iTransformer全面地超過了近幾年的預測模型。
iTransformer框架的通用性
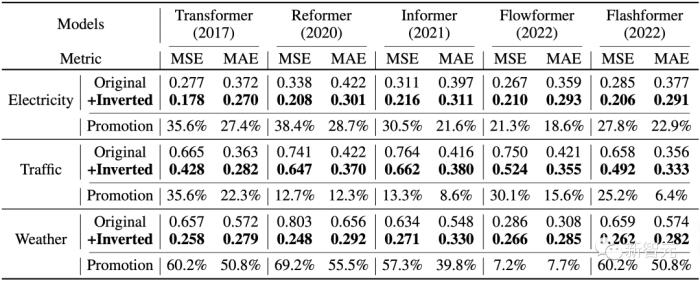
在取得最佳效果的同時,作者在Reformer、Informer、Flowformer、Flashformer等Transformer變體模型上進行了倒置前后的對比實驗,證明了倒置是更加符合時序數(shù)據(jù)特點的結(jié)構框架。
1. 提升預測效果
通過引入所提出的框架,這些模型在預測效果上均取得了大幅度的提升,證明了iTransformer核心思想的通用性,以及受益于高效注意力研究進展的可行性。
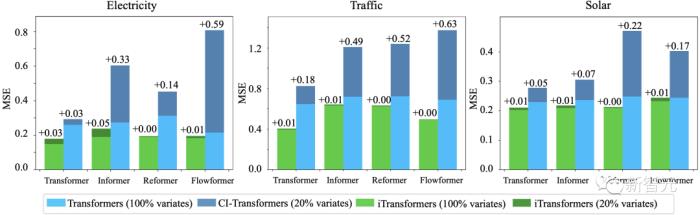
2. 泛化到未知變量
通過倒置,模型在推理時可以輸入不同于訓練時的變量數(shù),文中將其與一種泛化策略——通道獨立(Channel Independence)進行了對比,結(jié)果表明該框架在僅使用20%的變量時依然能夠盡可能減少泛化誤差。
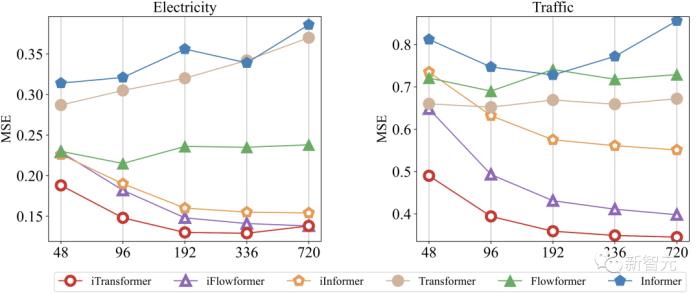
3. 使用更長歷史觀測
以往Transformer系模型的預測效果不一定隨著歷史觀測的變長而提升,作者發(fā)現(xiàn)使用該框架后,模型在歷史觀測增加的情況下展現(xiàn)出了驚人的預測誤差減小趨勢,在一定程度上驗證了模塊倒置的合理性。
模型分析
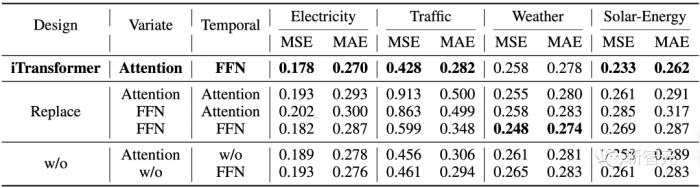
1. 模型消融實驗
作者進行了消融實驗驗證iTransformer模塊排布的合理性。
結(jié)果表明在變量維使用自注意力,在時間維上使用線性層的建模方式在絕大部分數(shù)據(jù)集上都取得了最優(yōu)效果。
2. 特征表示分析
為了驗證前饋網(wǎng)絡能夠更好地提取序列特征的觀點,作者基于CKA(Centered Kernel Alignment)相似度進行特征表示分析。CKA相似度越低,代表模型底層-頂層之間的特征差異越大。
值得注意的是,此前研究表明,時序預測作為一種細粒度特征學習任務,往往偏好更高的CKA相似度。
作者對倒置前后的模型分別計算底層-頂層CKA,得到了如下的結(jié)果,印證了iTransformer學習到了更好的序列特征,從而達到了更好的預測效果。
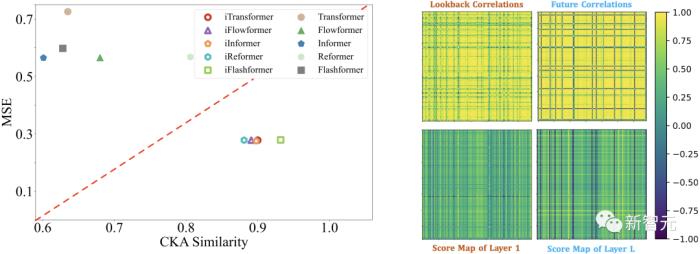
3. 變量相關性分析
如上圖所示,作用在變量維的注意力機制在學習到的注意力圖中展現(xiàn)出更加強的可解釋性。通過對Solar-Energy數(shù)據(jù)集的樣例進行了可視化,有如下觀察:
在淺層注意模塊,學習到的注意力圖與歷史序列的變量相關性更加相似。當深層注意模塊,學習到的注意力圖與待預測序列的變量相關性更加相似。這說明注意力模塊學到了更加可解釋的變量相關性,并且在前饋網(wǎng)絡中進行了對歷史觀測的時序特征編碼,并能夠逐漸解碼為待預測序列。
總結(jié)
作者受多維時間序列的本身的數(shù)據(jù)特性啟發(fā),反思了現(xiàn)有Transformer在建模時序數(shù)據(jù)的問題,提出了一個通用的時序預測框架iTransformer。
iTransformer框架創(chuàng)新地引入倒置的視角觀察時間序列,使得Transformer模塊各司其職,針對性完成時序數(shù)據(jù)兩個維度的建模難題,展現(xiàn)出優(yōu)秀的性能和通用性。
面對Transformer在時序預測領域是否有效的質(zhì)疑,作者的這一發(fā)現(xiàn)可能啟發(fā)后續(xù)相關研究,使Transformer重新回到時間序列預測的主流位置,為時序數(shù)據(jù)領域的基礎模型研究提供新的思路。
參考資料:
https://arxiv.org/abs/2310.06625
Tags:
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
