

 新火種
2023-09-09
新火種
2023-09-09 


創(chuàng)新工場(chǎng)王嘉平開(kāi)講:low-level的computer vision
顏萌 整理編輯量子位 出品 | 公眾號(hào) QbitAI

近日,在DeeCamp創(chuàng)新工場(chǎng)深度學(xué)習(xí)訓(xùn)練營(yíng)期間,創(chuàng)新工場(chǎng)AI工程院副院長(zhǎng)王嘉平開(kāi)講《low-level的計(jì)算機(jī)視覺(jué)》一課。
量子位把課程全部?jī)?nèi)容整理如下:
今天要和大家一起聊一聊的是low-level的computer vision。
當(dāng)下這個(gè)時(shí)代,high-level vision已經(jīng)有了長(zhǎng)足的進(jìn)展,在包括face recognition, 自動(dòng)駕駛等的領(lǐng)域提到的次數(shù)也越來(lái)越多。
那我為什么要講low-level vision呢?我們知道在high-level vision task的中,machine learning很強(qiáng)大,只要給它一些數(shù)據(jù),足夠的資料,它就可以學(xué)出來(lái)。但我們更需要關(guān)心一下數(shù)據(jù)是怎么來(lái)的,數(shù)據(jù)本身有些什么樣的問(wèn)題。這些都和low-level vision有關(guān)。如果了解了low-level vision,做 high-level vision的時(shí)候有非常大的幫助。
我舉一個(gè)例子。
很久以前在做OCR的時(shí)候, 我們要在image中把圖像識(shí)別出來(lái),而machine learning task拿到的數(shù)據(jù)不是無(wú)限的,只cover了一部分,這當(dāng)中隱含了一些不想要的數(shù)據(jù)的變化,比如OCR上的光照的變化,漸變和一些distortion,而且跟這個(gè)字具體是哪個(gè)字無(wú)關(guān)。
但是如果你不去掉這些變化,直接往machine learning model里面丟,如果數(shù)據(jù)足夠的多,當(dāng)然model可以把這些無(wú)關(guān)的變化和有關(guān)的變化分開(kāi),但事實(shí)上沒(méi)有那么多的數(shù)據(jù)。如果你學(xué)了low-level vision,你就可以想是否能預(yù)先把這些variation去掉,再送到machine learning 里面去,會(huì)使后面的machine learning更高效,依賴(lài)于更少的數(shù)據(jù)。
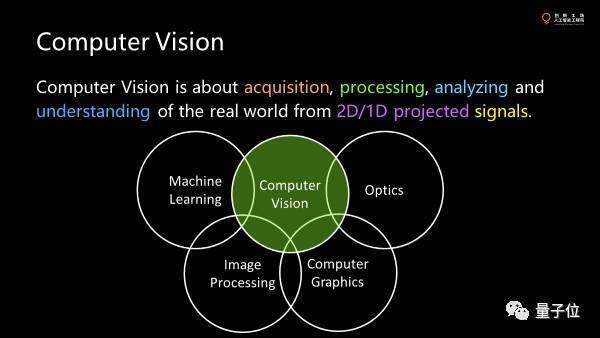
CV涉及很多方面,從信號(hào)的獲取,處理分析到最后的understanding,和很多學(xué)科都有關(guān)系,像machine learning,optics,computer graphics,并這關(guān)乎我們對(duì)于真實(shí)世界的理解,但由于傳感器的限制,我們這樣的理解通常來(lái)自二維或者一維的投影,而不是完整的三維的數(shù)據(jù)。
所以這件事情基本上是整個(gè)CV,尤其是3D CV最大的挑戰(zhàn)。

首先對(duì)于CV,計(jì)算機(jī)看到了什么?
對(duì)于這張圖來(lái)說(shuō),雖然已經(jīng)是三維空間的投影,但也不是三維空間本身,我們只看到了一個(gè)側(cè)面。很多物體被遮擋了,很多信息被丟失了。

對(duì)一張圖像來(lái)講,我們量化了每個(gè)方向上接受的光子的通量,并且離散化,拿到了一個(gè)包含很多值的數(shù)據(jù)集。每個(gè)值代表了傳感器上一小塊面積所接收到的單位時(shí)間里的光通量。光強(qiáng)越大,值就越大。這就是計(jì)算機(jī)看到的圖像。
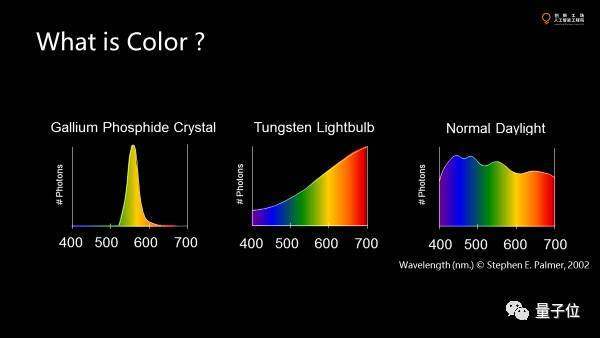
我們先講一個(gè)pixel上的value是怎么來(lái)的。要提到的是,它上面可能是luminance,也可能是luminance per channel。我們現(xiàn)在看到RGB,也就是3個(gè)channel。
channel代表顏色。而顏色沒(méi)有單位,因?yàn)轭伾皇俏锢砹浚侵饔^的量,本質(zhì)上是我們的傳感器也就是眼睛看到不同的光譜時(shí)在感光器上激發(fā)的量,真正的背后的物理量是光譜,也就是在不同頻段上能量的分布。
人之所以感覺(jué)到顏色,是人類(lèi)視覺(jué)系統(tǒng)用這三個(gè)積函數(shù)去積分了所接受的光譜,最后形成了三個(gè)感光細(xì)胞所拿到的系數(shù),然后映射到RGB的色彩空間。
色彩既然是主觀的,不同的生物也不一樣,這和生物在整個(gè)生態(tài)系統(tǒng)所處的位置是有關(guān)系的,是生物進(jìn)化導(dǎo)致的。
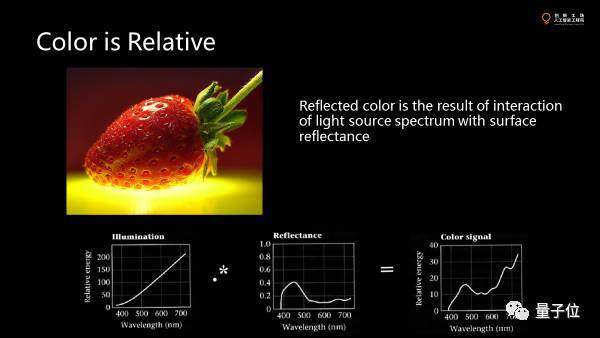
顏色不是絕對(duì)的。
除了直接去觀察光源,大部分顏色是光源的顏色和物體表面所反射的系數(shù)乘積得到的顏色,是疊加反射系數(shù)的顏色最終看到的。這就意味著我們看到的不是物體本真的反射光譜的分布,而是它跟光源交互的結(jié)果。所以在現(xiàn)實(shí)中不同的物體反射出的差別很大。

描述各種反射特性的物理量叫BRDF。
首先是反射系數(shù),多少量的光強(qiáng)達(dá)到這個(gè)表面上有多少量的光強(qiáng)被反射出去了,并且這個(gè)光強(qiáng)和入射角度和出射角度都是有關(guān)系的,進(jìn)去一個(gè)球面的角度,出去一個(gè)球面的角度,所以總共它是一個(gè)四維的函數(shù)。
這個(gè)在圖形學(xué)里面被非常heavy的study。因?yàn)槲覀円谟?jì)算機(jī)里重現(xiàn)真實(shí)世界中物體的外觀,這個(gè)函數(shù)就決定了這個(gè)物體的外觀是什么樣子的。我們做一個(gè)matching,做stereo,從不同的角度看物體,試圖去找到對(duì)應(yīng)的點(diǎn)。
這里的挑戰(zhàn)是假設(shè)這個(gè)函數(shù)是一個(gè)常量,就意味著對(duì)這個(gè)特定的點(diǎn),不論從哪個(gè)角度,顏色一樣。真實(shí)世界不是這樣的。
真實(shí)的世界中,這個(gè)BRDF并不是一個(gè)常量。即使是同一個(gè)點(diǎn)不同視角去看顏色也是不一樣的。

早年的vision里面,會(huì)假設(shè)一個(gè)所謂的lambertian surface。
反射是由于物體表面粗糙的微元面導(dǎo)致的,光打上去后會(huì)朝不同的方向去發(fā)散反射。假設(shè)光強(qiáng)在各個(gè)方向的反射是均勻的,這個(gè)就叫diffuse reflection。
粉筆和石膏就和這個(gè)十分接近。diffuse reflection意味著什么呢?早年的stereo算法都假設(shè)對(duì)特定的點(diǎn)從不同角度去看都是一樣的,我們就可以用不同角度圖片上的feature點(diǎn)去做對(duì)應(yīng),推演其三維空間的位置。但是實(shí)際問(wèn)題是specular reflection。

光源反射不均勻,通常會(huì)在鏡面方向上多一點(diǎn),然后形成沿著鏡面光源散射的specular peak。
如果這個(gè)specular peak很瘦,就會(huì)形成一個(gè)很亮的點(diǎn)。極限情況下它可能是一個(gè)沖擊函數(shù),這個(gè)時(shí)候物體看起來(lái)就像一面鏡子。有點(diǎn)時(shí)候又會(huì)寬一點(diǎn),比如啞光的材料。
這個(gè)會(huì)帶來(lái)很多困難。因?yàn)閙ultiple view的時(shí)候顏色會(huì)發(fā)生變化,尤其specular很強(qiáng)的時(shí)候,就會(huì)導(dǎo)致stereo,matching等很難做,很多算法也會(huì)受到影響。
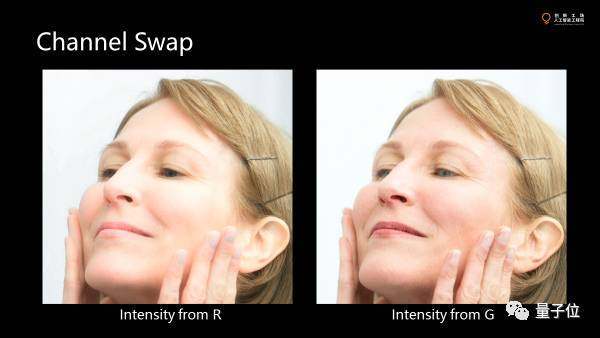
這是一個(gè)簡(jiǎn)單的磨皮算法。大概三四行代碼就可以實(shí)現(xiàn)。
大家怎么看一個(gè)磨皮算法的效果?就看在去掉臉上皺紋的同時(shí),眉毛和頭發(fā)有沒(méi)有留下。磨皮算法本質(zhì)上要把空間中一些細(xì)節(jié)去掉,但對(duì)于計(jì)算機(jī)來(lái)講,很難區(qū)別紋路,是皺紋還是毛發(fā)。
這里的兩張圖,左邊的圖里把所看到的亮度的變化的G和B去掉,只用R來(lái)構(gòu)造亮度的變化。當(dāng)然只把亮度替換掉,把顏色留下。另外一張則把G留下。
由于不同波長(zhǎng)的光在皮膚里散射的不同,散射強(qiáng)的紅色就會(huì)把皮膚的褶皺給blur掉,但毛發(fā)不受影響。綠色就基本沒(méi)有做什么blur,留下了皮膚上各種粗糙的東西。
有種說(shuō)法是尼康相機(jī)適合拍人像,原因是什么呢?人類(lèi)構(gòu)造圖像有三條三原色的曲線。相機(jī)為了接近人類(lèi)的視覺(jué),構(gòu)造出人類(lèi)最后可以看到的圖像,同樣也有類(lèi)似的三條曲線,尼康的傳感器里構(gòu)造RGB系統(tǒng)時(shí)分量系統(tǒng)往綠色和藍(lán)色的分量少一點(diǎn)。當(dāng)系統(tǒng)把很高維的分量投射到三維里面去的時(shí)候,背后的光路是不一樣的,雖然投影后顏色是一樣的。佳能往高能量的光譜多一些。因此尼康拍人像的時(shí)候,細(xì)節(jié)更多來(lái)自紅色的通道,所以皮膚就會(huì)看起來(lái)很好。當(dāng)然這個(gè)差異不是非常的大。
說(shuō)完光譜的事情,我們現(xiàn)在假設(shè)所有的事情在一個(gè)通道上發(fā)生。
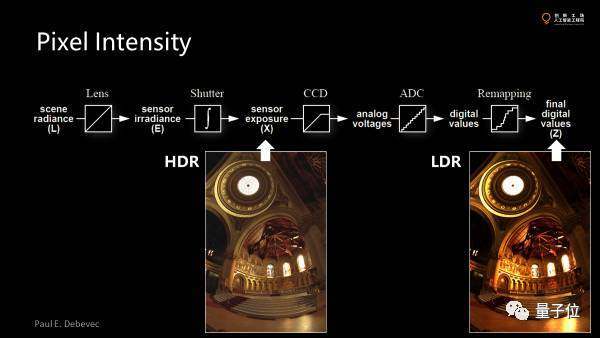
對(duì)于現(xiàn)有的大部分傳感器,光進(jìn)來(lái)后經(jīng)過(guò)一系列的處理最終變成圖像上面pixel上的value,這里有幾個(gè)步驟。
首先經(jīng)過(guò)一個(gè)鏡頭并處理后,有一個(gè)exposure。因?yàn)閭鞲衅鞑皇钦娴哪靡粋€(gè)snapshot,其實(shí)是積分了一段時(shí)間才能測(cè)量到光的強(qiáng)度。然后經(jīng)過(guò)模式轉(zhuǎn)換器,把光通量模擬量轉(zhuǎn)換成一個(gè)數(shù)據(jù)量。最后還有一些post-processing。
為了盡可能多得看清細(xì)節(jié),亮部暗部都要有一些。但我們發(fā)現(xiàn)最終的圖像有些部分飽和掉了看不清楚了。
那么在vision的采集系統(tǒng)里都有哪些坑?
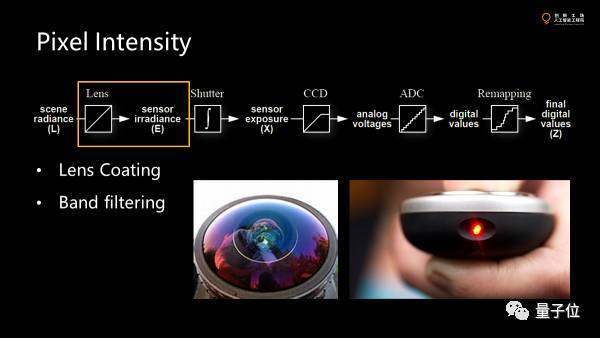
首先,過(guò)鏡頭的時(shí)候會(huì)濾掉一部分波長(zhǎng)的光,因?yàn)榇蟛糠窒到y(tǒng)不是為vision understanding設(shè)計(jì)的,是為拍照設(shè)計(jì)的。為了得到更好的成像的質(zhì)量就會(huì)濾掉一些對(duì)于構(gòu)造圖片沒(méi)有用的光。紫光一般被反射出去了。
這是一個(gè)増透膜,使得更多的光進(jìn)入鏡頭,可以提高照片質(zhì)量。
大部分CCD和相機(jī)其實(shí)對(duì)紅外光都是很敏感的,我們可以拿遙控器對(duì)著手機(jī)看是很亮的,所以幾乎所有的鏡頭都會(huì)對(duì)紅外光有一個(gè)過(guò)濾。如果不過(guò)濾,幾乎是一片白。
這部分做了一個(gè)filter mask,把我們不想看的紫外紅外干掉。剩下可見(jiàn)光透過(guò)鏡頭。

接著是曝光。
最后,sensor上面讀到的數(shù)據(jù)等于曝光時(shí)間乘以光通量。因?yàn)閭鞲衅鞯拿舾卸仁怯邢薜模M(jìn)光量很小的時(shí)候?yàn)榱税颜掌某鰜?lái)就需要比較長(zhǎng)的曝光時(shí)間,那么為了完整地獲取圖像的一幀,就需要幀率不能超過(guò)曝光時(shí)間分之一。
自動(dòng)獲取圖像模塊把曝光時(shí)間調(diào)大,一旦調(diào)大到幀率分之一還大,幀率就會(huì)降下來(lái)。
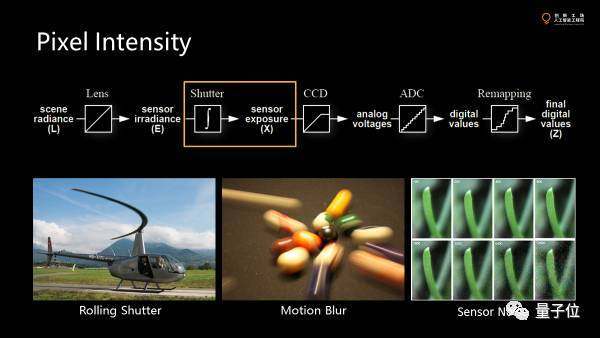
這里的第一個(gè)問(wèn)題是rolling shutter。
大家看到這里直升機(jī)的螺旋槳拍下來(lái)不是直的。因?yàn)楫?dāng)我們的成像的時(shí)候,圖像上的像素不是在同時(shí)獲得的,最上面的pixel可能是0.0001秒,第二行是0.0002秒。整張圖像是掃描獲得的,而物體運(yùn)動(dòng)足夠快的時(shí)候,不同行獲得的信息不一致,但掃描的過(guò)程是連續(xù)的,所以最后的圖片就變成這樣一個(gè)連續(xù)的扭曲了。
第二個(gè)是motion blur。
同樣拍運(yùn)動(dòng)物體。為了測(cè)量不同pixel上的進(jìn)光量,就需要一個(gè)一段時(shí)間的積分。如果在那段很短的時(shí)間內(nèi)有很多的snapshot,我們把它們疊加到一起。如果物體運(yùn)動(dòng)得夠快,哪怕10毫秒可以造成圖像很大的不同。在exposure的瞬間,物體已經(jīng)跑了一段距離了,那么最后拿到的是積分的結(jié)果。比如識(shí)別路牌,motion blur 對(duì)此就很不利。
為了減少這兩種問(wèn)題,最好的方法是減少曝光時(shí)間,這意味著在成像過(guò)程中,會(huì)有更少的光子來(lái)。假設(shè)傳感器的敏感度不變。不同的照片在不同的iso上拍的。
由于成像系數(shù)在前面計(jì)算,不涉及量化的問(wèn)題。如果把曝光減少,不調(diào)iso,圖像就會(huì)變暗。而當(dāng)曝光時(shí)間很小,猛調(diào)傳感器系數(shù)時(shí),就會(huì)出現(xiàn)噪音。因?yàn)閭鞲衅鞅緛?lái)就有熱噪聲。所以曝光時(shí)間是一個(gè)矛盾的事情,太大了會(huì)blur,太小了有噪聲。

我們?cè)僬f(shuō)到CCD上面,傳感器上會(huì)發(fā)生兩件事。
第一是飽和。光是線性的,為了拍出暗部,把亮的部分砍掉。意味著我們可以確定亮度范圍,把超出的部分砍掉,然后去做量化。
這里會(huì)有幾個(gè)問(wèn)題。
我們?yōu)榱四玫桨挡康募?xì)節(jié),就會(huì)丟掉亮部的細(xì)節(jié)。如果為了留下亮部的細(xì)節(jié),要使整張圖片都沒(méi)有飽和。亮度除以一萬(wàn)倍,最亮才能fit到量化空間里,但暗部的細(xì)節(jié)就沒(méi)有了。
本質(zhì)上說(shuō)圖片量化精度不夠,而沒(méi)有那么多量化點(diǎn)。我們會(huì)人為選擇的量化范圍。要不留下亮度的細(xì)節(jié),要不留下暗部的。線性量化的時(shí)候,有時(shí)候量化精度不夠,比如gif圖像通常量化的層級(jí)不夠。我們有時(shí)可以過(guò)渡。
這些都是因?yàn)槲覀兊膫鞲衅骱吞幚黼娐返南拗啤R话愕膱D像是8位。有些人要拿raw,就意味著拿CCD原始的東西。有的CCD里面的raw是10個(gè)bit或者12個(gè)bit一個(gè)變量,這樣量化要好些。
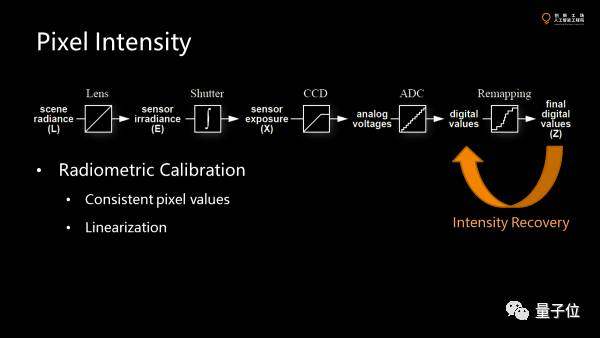
最后是對(duì)模式轉(zhuǎn)換器做最后的變化。
前面全部是線性變化。這一步是非線性的變化,比如白平衡,色彩的矯正,伽瑪矯正。
這里面的伽瑪通常是值的1.2次方或1.5次方,這個(gè)可以近似人眼對(duì)光強(qiáng)的反應(yīng):人眼的反應(yīng)不是線性的,這意味著暗部的量化精度高于亮部。
大部分手機(jī)或單反拿到的圖像,引入非線性意味著什么呢?
比如我們要做人臉識(shí)別,要去掉或者歸一化光照。假設(shè)pixel的值是線性。其實(shí)不是,都被處理過(guò)。真正做歸一化,先要做intensity recovery,通過(guò)拍攝不同亮度的照片反求這個(gè)函數(shù)。
因?yàn)槭菃握{(diào)的函數(shù),所以可以反過(guò)來(lái)算原來(lái)的線性空間的值。嚴(yán)格的做法是把值線性化,叫radiometric calibration。這是很多做vision task的第一步,但是很多被忽略了。
這個(gè)是可以保證我們拿到的pixel 是線性化之后的值。如果做線性變換,同比增加亮度,拿到的值不是2:1。線性化之后以后比例才能一致,才能準(zhǔn)確地把光照條件帶來(lái)的variation去掉。

在這個(gè)過(guò)程中我們可能會(huì)丟失很多信息。尤其一個(gè)場(chǎng)景一旦飽和掉,不同pixel的值就都一樣了。
為了改善這件事,有個(gè)東西叫HDR,用最后從傳感器拿到的圖像重構(gòu)光進(jìn)入傳感器前的場(chǎng)景。HDR其實(shí)是高動(dòng)態(tài)范圍的圖像,最大值和最小值的差距很大。
重構(gòu)原理是因?yàn)榕恼罩涣粝略O(shè)定的亮度范圍,只有這一段會(huì)被量化。那么我們不斷改變曝光量,得到這個(gè)序列當(dāng)中各個(gè)亮度范圍的細(xì)節(jié),再把圖像疊到一起。假設(shè)曝光時(shí)位置不變,那么每個(gè)pixel就可以對(duì)起來(lái)。
我們把沒(méi)有飽和的像素都選出來(lái),做平均——這個(gè)首先要在線性化以后的值上做,把原來(lái)的值線性化——疊加完后拿到HDR圖像,每個(gè)通道上的值都是一個(gè)浮點(diǎn)數(shù),這樣就可以表達(dá)很大的動(dòng)態(tài)范圍。

然而我們的vision不是孤立地看一個(gè),要看很多像素。這些像素有固定的結(jié)構(gòu)和pattern,local feature在很多vision task里面都要用到。
vision代表著圖像中物體的piece,它雖然對(duì)物體的feature沒(méi)有理解,但它企圖去抓feature,這就是認(rèn)定圖像有一致的localization,不管在什么位置,不管物體的位置和朝向,這個(gè)特定的feature點(diǎn)都跟著物體走。
feature找到后,要去encode這個(gè)feature,這個(gè)的對(duì)slam或stereo非常有用。
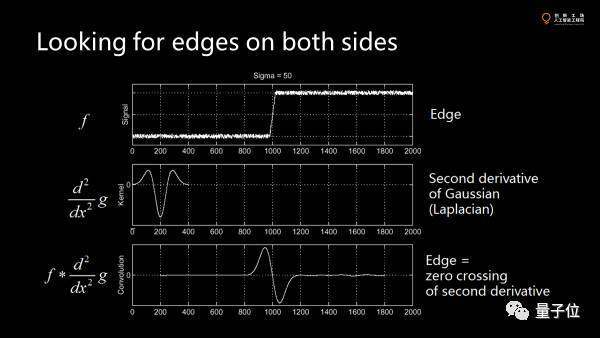
我們?cè)倩貧w邊緣檢測(cè)。邊緣檢測(cè)就是在圖像中找到比較顯著的不連續(xù)的邊界。
在一維里,用高斯函數(shù)的二階導(dǎo)卷積圖像里得到一些小波浪,這些小波浪會(huì)跟著圖像走,這就是有l(wèi)ocalization特性。然而對(duì)一個(gè)pattern,要用兩個(gè)邊界去刻畫(huà)。我們不僅需要知道feature的位置,還要知道大小。
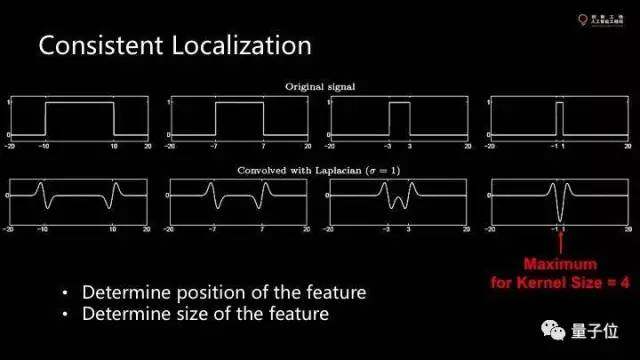
這個(gè)函數(shù)的積分信號(hào)和卷積和不是我想要的。信號(hào)的size當(dāng)和卷積和的kernel size差不多的時(shí)候,我們可以得到一個(gè)local minimum,這個(gè)點(diǎn)就是我們想要的。
這個(gè)點(diǎn)可以告訴我們feature的位置和大小。實(shí)際上遍歷各種不同大小的kernel去卷積,我們把它拓展到二維,就是一維函數(shù)沿軸旋轉(zhuǎn)一下。
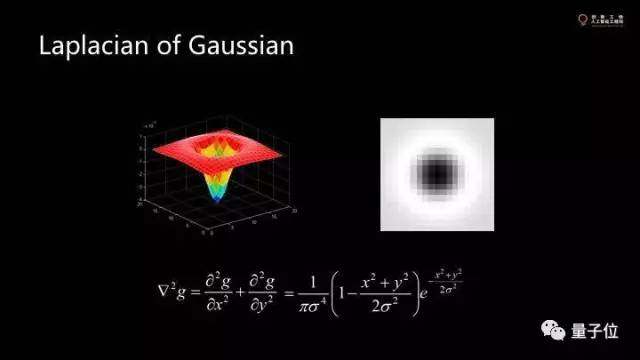
二維函數(shù)的本身是高斯和的二次求導(dǎo)。這個(gè)函數(shù)能夠在不同的寬度間拿到不同的值,使得不同的層互相比,到處找local minimum。最后拿到的數(shù)據(jù)中,每個(gè)圓圈的中心表示feature在哪里,每個(gè)圓圈的大小表示feature有多大。
最關(guān)鍵的在于如果我把這個(gè)圖像挪動(dòng),縮小,轉(zhuǎn)動(dòng),這些feature點(diǎn)也會(huì)跟著走。還有就是卷積的圖像不只是一張。這些feature點(diǎn)是在不同的層上找的。因此找minimal不是在x,y上找,而是在x,y,z上找,然后投影。

所以當(dāng)我們很好的抓到這些位置之后,那么首先要確定feature的位置,當(dāng)feature點(diǎn)位置確定,要確定來(lái)自同一個(gè)函數(shù),意味著我們要有一個(gè)尺度的衡量,我們不僅要知道一個(gè)feature點(diǎn)的大小和位置,我們還要在知道內(nèi)容是什么。
基于算法找到feature后,用一個(gè)向量表示feature的內(nèi)容,并抵御縮放帶來(lái)的影響。這個(gè)feature里物體的遠(yuǎn)近出來(lái)的值差不多。x,y的移動(dòng)已經(jīng)歸一化。z軸也歸一化掉。
這個(gè)大量被使用在3D重構(gòu)。本質(zhì)思想是線條朝向記下來(lái),計(jì)算梯度,用朝向刻畫(huà)內(nèi)容,再用8個(gè)bit去刻畫(huà)。由于相機(jī)的圖像是在不同的位置拍攝的,假如沒(méi)有運(yùn)動(dòng)的很快,就會(huì)是有重疊的,但拍的時(shí)候由于在動(dòng),不能簡(jiǎn)單的疊加,要一對(duì)一對(duì)的解圖像間的關(guān)系并拼起來(lái)。
抓到feature點(diǎn)后就來(lái)找對(duì)應(yīng)。對(duì)應(yīng)里可能會(huì)有很多的錯(cuò)誤。求解的就是把所有的對(duì)應(yīng)關(guān)系聯(lián)立上面大方程。每一個(gè)點(diǎn)做一個(gè)變換。這個(gè)變化是一個(gè)3×3的矩陣。只要超過(guò)9個(gè)方程,矩陣就可以求解。

不正確的對(duì)應(yīng)關(guān)系不能包含在線性系統(tǒng)里面,不然結(jié)果會(huì)偏掉,假設(shè)正確的對(duì)應(yīng)遠(yuǎn)大于錯(cuò)誤的,隨便找?guī)讉€(gè)對(duì)應(yīng)關(guān)系。求解t,大部分正確但有偏差的。反向驗(yàn)證對(duì)應(yīng)關(guān)系,跟transformation是否一致,過(guò)于不一致就丟掉。
拍攝的時(shí)候光照的參數(shù)有點(diǎn)不一樣,細(xì)節(jié)一致,絕對(duì)亮度稍微有點(diǎn)不一樣。這就已經(jīng)不是vision的事情了,是graphics的問(wèn)題。有個(gè)泊松image的方法,梯度留下,絕對(duì)亮度丟掉。點(diǎn)與點(diǎn)之間的相對(duì)梯度關(guān)系連起來(lái)求泊松方程,解出image。這樣解完以后邊界就會(huì)消失了。
摒棄了絕對(duì)亮度,利用梯度的亮度重新生成。
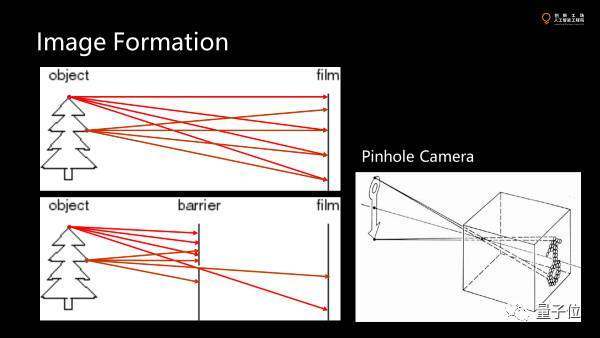
那么三維空間的投影是怎么發(fā)生的,成像是怎么成的呢?
現(xiàn)實(shí)中每個(gè)物體對(duì)所有方向都在發(fā)光,放一個(gè)膠片或傳感器上每一個(gè)點(diǎn)上的光照強(qiáng)度都來(lái)自于目標(biāo)物體所有點(diǎn)的光強(qiáng)。要成像就要使得傳感器上受到的光照來(lái)自物體的一個(gè)特定的點(diǎn)。
可以在光圈留一個(gè)很小的洞,唯一找到小孔反向求焦到真實(shí)世界的一個(gè)點(diǎn)。這就是小孔成像,也是最經(jīng)典的pinhole camera的模型。
之所以能成像,要使得這一個(gè)點(diǎn)被照的內(nèi)容,來(lái)自于盡量少的目標(biāo)物體的點(diǎn),小孔越小,光錐越小,點(diǎn)只貢獻(xiàn)到接收面上的很小一個(gè)點(diǎn)。小于一個(gè)像素就可以成很清晰的像。
但當(dāng)孔很小的時(shí)候,跑到傳感器上的光很少,圖像會(huì)很暗。理論上可以無(wú)限增長(zhǎng)曝光時(shí)間,不斷積分,但并不實(shí)際。
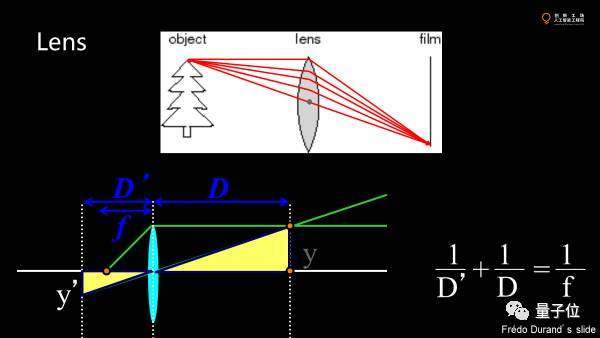
如果可以改變光的方向,聚到一個(gè)地方去,圖像就可以清晰且不會(huì)太暗。于是人們發(fā)明了鏡頭,使點(diǎn)偏離光軸方向發(fā)生偏轉(zhuǎn),形成聚焦。物距和焦距定了,像就定了。

但傳感器是平的,只能捕獲一個(gè)方向的像素。實(shí)際物體時(shí)三維的,有一些點(diǎn)的最佳成像位置不同。有一些點(diǎn)會(huì)正好落在傳感器上。這就是景深。
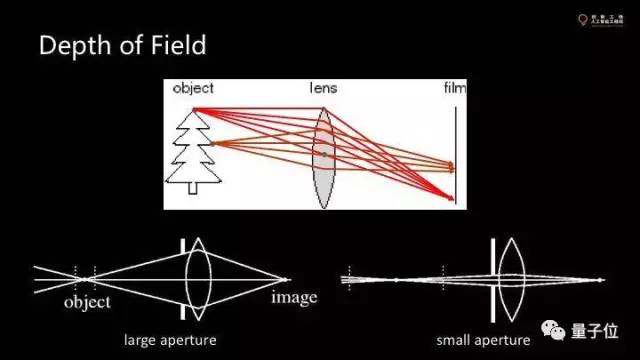
只要在景深的范圍內(nèi)成像就是比較清晰。其他點(diǎn)一定存在blur,只要小于一個(gè)像素,就仍舊是清晰的。有時(shí)候因?yàn)榫嚯x的不同,真正的焦點(diǎn)會(huì)相差了一點(diǎn)點(diǎn)比如0.1毫米,這在圖像上會(huì)造成多大范圍的模糊,還由光圈決定。
光圈小,blur的半徑會(huì)小一點(diǎn),前后都清晰,但進(jìn)光量會(huì)小。光圈大,鏡頭得大。意味著相機(jī)會(huì)大。而傳感器大,單元面積大,接收更多的光子。如果焦距越短,張角越大,就像監(jiān)控的廣角相機(jī),一般大家不想要這種效果。
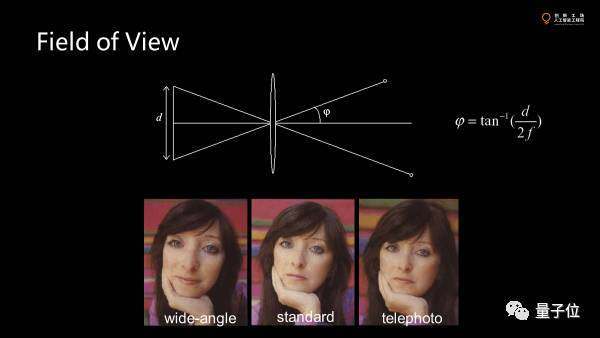
視角變大就會(huì)引入徑向的畸變。徑向畸變一個(gè)是因?yàn)殓R頭的不完美,另一個(gè)是視場(chǎng)角,太大會(huì)形成突出的球面的效應(yīng)。球面映射到平面總會(huì)有扭曲。

畸變可以建模,扭回來(lái)。但是范圍就會(huì)奇怪,意味著就會(huì)裁掉一些東西,浪費(fèi)一些像素。


為了更方便地去描述3D場(chǎng)景是怎么樣被投射到二維的,機(jī)器視覺(jué)里引入了一個(gè)叫齊次坐標(biāo)的東西。
因?yàn)槭褂贸ê缶筒皇蔷€性系統(tǒng),所以我們給它升維,這樣做的好處是升過(guò)維的向量可以和后面所有這些transformation可以formulate到一起去,變成一個(gè)線性的東西,最后成像的時(shí)候計(jì)算圖像空間點(diǎn)的位置,在最后除一下就行。
圖像距離越遠(yuǎn)就會(huì)越接近光軸,那么這個(gè)除法先不做,最后成像后再做,前面計(jì)算過(guò)程中就可以回避非線性的問(wèn)題。
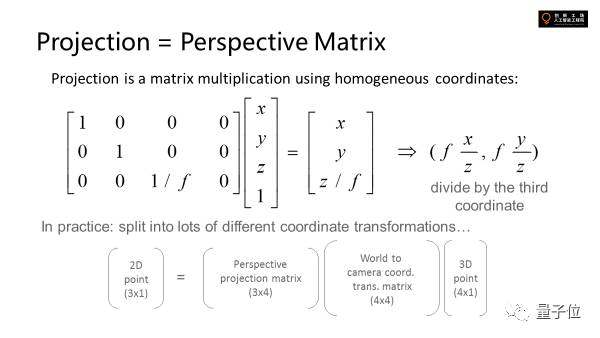
這些在數(shù)學(xué)中的公式就是perceptive matrix,四維投射成三維的矩陣乘法。真實(shí)世界中空間中有一個(gè)三維的點(diǎn),有一個(gè)world坐標(biāo)到image坐標(biāo)的轉(zhuǎn)換過(guò)程。
比如世界坐標(biāo)系先建好,所有的點(diǎn)都定義進(jìn)去,這時(shí)候相機(jī)可以放在特定位置,會(huì)有一個(gè)矩陣來(lái)描述,把世界坐標(biāo)系轉(zhuǎn)化為相機(jī)坐標(biāo)系,再乘perspective matrix,再相機(jī)坐標(biāo)系轉(zhuǎn)換到圖像坐標(biāo)系。
這就是三維成像的基礎(chǔ)。
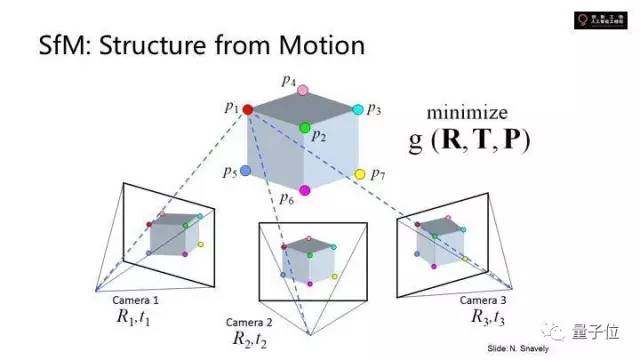
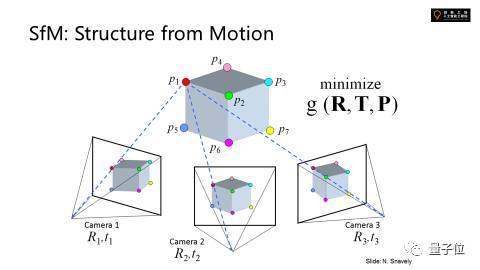
這是處理大規(guī)模三維重建的方法。空間中的點(diǎn)拿到的圖像乘了一個(gè)空間變換矩陣。現(xiàn)在相機(jī)和點(diǎn)的位置不知道,同樣一個(gè)物體被幾個(gè)相機(jī)拍了,聯(lián)立可以求得物體上的點(diǎn)和相機(jī)的位置。這個(gè)就是它的目標(biāo)函數(shù)。
假設(shè)旋轉(zhuǎn)矩陣為已經(jīng)知道了,translation和perspective都知道了,對(duì)應(yīng)空間中的所有的feature點(diǎn),點(diǎn)在圖像上的正確位置是知道的。
要猜測(cè)求出空間中的位置,minimize這個(gè)錯(cuò)誤。可以拿到相機(jī)的位置。這是非常大規(guī)模的,要優(yōu)化幾百萬(wàn)個(gè)點(diǎn)的位置,幾千張照片對(duì)應(yīng)幾千個(gè)不同的相機(jī)的位置,還要同時(shí)優(yōu)化相機(jī)的位置,最終做一起minimize。


比如去互聯(lián)網(wǎng)上搜集某個(gè)景點(diǎn)游客拍攝的圖片。做joint optimization。做local featurization會(huì)發(fā)現(xiàn)各有一堆的feature點(diǎn),任何兩張feature點(diǎn)可以構(gòu)造幾千個(gè)點(diǎn),算出空間的位置。
如果聯(lián)立照片中三維點(diǎn)的位置就能重現(xiàn)一個(gè)點(diǎn)云出來(lái),用點(diǎn)云刻畫(huà)三維場(chǎng)景中點(diǎn)的位置。但因?yàn)橹皇且粋€(gè)點(diǎn)云,不是完整地構(gòu)造幾何的表面。
同時(shí)對(duì)于那么多圖像,可以算出每一張是哪個(gè)位置拍的,google的街景就是這樣,這些點(diǎn)云可以自己算出來(lái)是哪個(gè)位置拍的并精確到pixel level的位置。這樣就可以讓你很好的在照片與照片間游走。就重建這個(gè)三維。

回想一下,這里用到的技術(shù)。每個(gè)點(diǎn)成像怎么來(lái)的,根據(jù)這個(gè)定義local feature ,找到兩個(gè)點(diǎn)的對(duì)應(yīng)關(guān)系并進(jìn)行transformation。
所有的變化是在image space里面變換的。這里的不同位置是有視差的,求解不是圖像空間的變換,是三維空間的變換。兩兩去做會(huì)發(fā)生最后的點(diǎn)云和重構(gòu)的點(diǎn)云接不起來(lái)。因?yàn)閭鬟f會(huì)積累誤差。
如果距離很遠(yuǎn)的話我們就要去重構(gòu)一個(gè)大范圍的物體差別在于不同的圖像重疊部分有多大,如果很大,那么drafting也會(huì)很大。
那如果每次都重疊很小,transformation是通過(guò)鏈條積累起來(lái)的。這個(gè)就需要大量的feature點(diǎn)聯(lián)合。
總結(jié)

high-level vision task的時(shí)候,成像是一個(gè)imperfect的,而且有一個(gè)假設(shè),不是我們想獲得什么數(shù)據(jù)。同時(shí)獲得的數(shù)據(jù)是不是有問(wèn)題的。告訴我們圖像的變化是怎么來(lái)的,是不是我們想要的。如果可以預(yù)先知道,提前去掉,使得數(shù)據(jù)的使用率大大提高。一旦high-level里數(shù)據(jù)不夠,出現(xiàn)誤差,不能收斂,我們就需要去看看數(shù)據(jù)怎么來(lái)的,回頭看看low-level vision怎么來(lái)的。做machine learning等的時(shí)候,有時(shí)候去死調(diào)你的算法參數(shù)不如獲得更多的信息更好的數(shù)據(jù)有用,根據(jù)場(chǎng)景設(shè)計(jì)你的傳感器系統(tǒng),camera放在什么位置,什么光源。這個(gè)對(duì)high-level understanding能不能做好很重要。
問(wèn)答環(huán)節(jié):
1. 點(diǎn)云生成后下一步是什么呢?
基本的思想是兩個(gè)方面的信息,告訴你每個(gè)點(diǎn)的位置直接連線,不一定可靠。每個(gè)點(diǎn)周?chē)泻芏帱c(diǎn)。先構(gòu)建一個(gè)graph,和周?chē)?lián)系起來(lái),但不能保證重構(gòu)起來(lái)的是合法的流形。此時(shí)就有一堆幾何處理的算法砍掉不正常的邊和點(diǎn)。
當(dāng)圖像足夠多的時(shí)候還可以知道每個(gè)點(diǎn)的法向量。
如果對(duì)同一個(gè)點(diǎn),拍的照片能發(fā)現(xiàn)不同光照的亮度,根據(jù)拍攝時(shí)間和朝向估算光源的位置。在圖像空間中重構(gòu)法向量,不但給位置也給法向量。一旦有法向量就知道和graph哪些邊是不能連的,可以更好的構(gòu)造面。
2. VR里vision是否需要更多算法去提高渲染質(zhì)量?
不是vision的事情,更多是graphics的事情。
為了得到高質(zhì)量渲染的圖像,對(duì)物體的material要有很好的描述,比如BRDF能在計(jì)算機(jī)里渲染出和照片一樣逼真的畫(huà)。
第二個(gè)是光照。除了photography上的應(yīng)用,在computer graphics里也很有意義。早期看到的graphics渲染的東西很artificial,很大問(wèn)題是點(diǎn)光源化。
現(xiàn)實(shí)中不存在絕對(duì)的點(diǎn)光源,光還會(huì)間接照射這個(gè)物體,本身是全局的光照計(jì)算照射系統(tǒng)。用HDR圖像刻畫(huà)整個(gè)場(chǎng)景對(duì)它的光照,不是一個(gè)點(diǎn)去照射,而是一個(gè)球面積分,這樣渲染的質(zhì)量會(huì)更接近真實(shí)的世界。VR現(xiàn)在機(jī)能沒(méi)有那么強(qiáng)。
3. 三維空間的表面反射比較強(qiáng)部分,怎么重建三維?
最基本的方法是找到不同視角對(duì)應(yīng)的點(diǎn),反算在空間的位置。但一旦對(duì)應(yīng)關(guān)系不能被建立,就不能通過(guò)找對(duì)應(yīng)重構(gòu)。
這里用photometric stereo,對(duì)物體打個(gè)側(cè)面的光。打很多側(cè)面的光,如果有物體表面反射一定假設(shè),就能求出每個(gè)表面的法向量。只要改變光源的位置就能求出空間中每一個(gè)法向量是多少了。
有了法向量,積分就可以求出物體的曲面,位置。另外一套算法是把場(chǎng)景弄成一片一片,每一片都可以求到一塊集合。先用法向量來(lái)做。
比如說(shuō)有的物體表面反射光強(qiáng)和奇怪,不能找對(duì)應(yīng)。那么把圖片單獨(dú)做,把面上的法向量求出來(lái),和視角無(wú)關(guān)。我們就可以回到原來(lái)的路,找對(duì)應(yīng),不是用RGB color找對(duì)應(yīng),而是用法向量構(gòu)成的feature來(lái)做。
4. 機(jī)器學(xué)習(xí)中識(shí)別RGB ,如何用光度的方法如何把法向量丟進(jìn)去學(xué)?
比如卷積神經(jīng)網(wǎng)絡(luò),后面幾層都一樣。關(guān)鍵是前面幾層。現(xiàn)在前面的卷積的kernel,灰度圖像除了5×5之外,只有一個(gè)5×5的卷積網(wǎng)絡(luò)。如果后面是RGB后面就需要有三個(gè)。但因?yàn)橄蛄渴莕ormalize過(guò)的單位向量,所以只要2個(gè)5×*5的就夠了。
我只關(guān)心每個(gè)pixel上有幾個(gè)維度,每個(gè)維度內(nèi)容是什么我不關(guān)心,只不過(guò)每個(gè)維度的value不一樣。本質(zhì)還是刻畫(huà)圖像的原本的特征,但是一個(gè)是RGB的體現(xiàn),一個(gè)是法向量的體現(xiàn)。比如一個(gè)RGB的kernel,每個(gè)點(diǎn)上面,除了RGB還有D,不做更好的優(yōu)化,可以直接丟到CNN里面,但是對(duì)前面卷積的5×5需要換成5×5來(lái)對(duì)應(yīng)于每一個(gè)channel,這個(gè)實(shí)現(xiàn)就夠了。
有時(shí)候我們還是要care一下range不一樣。數(shù)據(jù)可以直接丟,也可以做一個(gè)歸一化,但歸一化可以讓全連接網(wǎng)絡(luò)去學(xué)也不難,但是你開(kāi)始不要直接丟進(jìn)去學(xué)。前期已經(jīng)知道模型的時(shí)期就不要丟進(jìn)去學(xué)。要準(zhǔn)備的數(shù)據(jù)也會(huì)變少,過(guò)程也會(huì)變簡(jiǎn)單。
5. 法向量可以丟進(jìn)去,我們?cè)跇?biāo)法向量的時(shí)候很難標(biāo)定條件怎么辦?
法向量是算出來(lái)的,光源也是算出來(lái)的。假設(shè)光源遠(yuǎn),就可以放一個(gè)球,預(yù)先知道球的法向量,反算光源的位置。如果點(diǎn)光源近,就可以放四個(gè)球,預(yù)先知道四個(gè)球的法向量,通過(guò)光求的最亮點(diǎn)反求出方向和距離,就可以知道每個(gè)法向量是多少。
—— 完 ——
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴(lài)本文觀點(diǎn)而產(chǎn)生的任何金錢(qián)損失負(fù)任何責(zé)任。
