

 新火種
2025-02-26
新火種
2025-02-26 


大模型推理更可能是概率模式匹配?北大團(tuán)隊從蒙特卡洛語言樹的新視角解讀GPT,思維鏈原理也有新的理解
文章轉(zhuǎn)載于量子位(QbitAI)
思維鏈(CoT)為什么能夠提升大模型的表現(xiàn)?大模型又為什么會出現(xiàn)幻覺?
北大課題組的研究人員,發(fā)現(xiàn)了一個分析問題的新視角,將語言數(shù)據(jù)集和GPT模型展開為蒙特卡洛語言樹。
具體來說,數(shù)據(jù)集和模型分別被展開成了Data-Tree 和GPT-Tree 。

結(jié)果,他們發(fā)現(xiàn),現(xiàn)有的模型擬合訓(xùn)練數(shù)據(jù)的本質(zhì)是在尋求一種更有效的數(shù)據(jù)樹近似方法(即)。
進(jìn)一步地,研究人員認(rèn)為,大模型中的推理過程,更可能是概率模式匹配,而不是形式推理。
1
將數(shù)據(jù)和模型拆解為蒙特卡洛樹
在預(yù)訓(xùn)練過程中,大模型通常學(xué)習(xí)的是如何預(yù)測下一個token(也就是將每個token的似然進(jìn)行最大化),從而對大規(guī)模數(shù)據(jù)進(jìn)行無損壓縮。

其中, 是優(yōu)化上述似然得到的模型參數(shù)。
作者發(fā)現(xiàn),任何語言數(shù)據(jù)集都可以用蒙特卡洛語言樹(簡稱“Data-Tree”)完美地表示,參數(shù)化為。
具體來說,作者采樣第一個token作為根節(jié)點(例如“For”),枚舉其下一個token作為葉子節(jié)點(例如“the”或“example”),并計算條件頻率()作為邊。
重復(fù)這一過程,就可以得到被語言數(shù)據(jù)集扁平化的“Data-Tree”。形式上,Data-Tree滿足以下條件:

其中,代表頻率函數(shù), 代表第個token。作者從理論上證明了Data-Tree的是上述最大似然的最優(yōu)解。換句話說,最大化似然得到的模型參數(shù)最終都在不斷靠近。
類似的,作者提出任意的類GPT模型也可以展開成另一顆蒙特卡洛語言樹(簡稱“GPT-Tree”),參數(shù)化為。
為了構(gòu)建GPT-Tree,作者也從token空間采樣第一個token 并將其輸入到GPT,然后記錄其第二個token 以及其概率分布│。
接著,作者枚舉所有的第二個token,并將輸入到GPT并得到第三個token 。
重復(fù)這一過程,就可以得到GPT展開后的“GPT-Tree”。
1
蒙特卡洛樹視角下的新發(fā)現(xiàn)
在將數(shù)據(jù)和模型展開后,作者有了新的發(fā)現(xiàn),并用新的視角解釋了一些模型現(xiàn)象。
下圖是對GPT-X系列模型和Data-Tree的樹形可視化結(jié)果,其中每列代表不同token,每行代表不同的模型,最后一行代表Data-Tree。

GPT模型逐漸收斂于數(shù)據(jù)樹
作者發(fā)現(xiàn),在同一數(shù)據(jù)集(the Pile)上訓(xùn)練的不同語言模型(GPT-neo-X系列模型)在GPT-Tree可視化中具有顯著的結(jié)構(gòu)相似性。

通過對這一結(jié)果進(jìn)行進(jìn)一步量化,作者發(fā)現(xiàn),GPT模型越大,越接近 Data-Tree,超過87%的GPT輸出token可以被Data-Tree召回。
這些結(jié)果表明,現(xiàn)有的語言模型本質(zhì)上尋求一種更有效的方法來近似數(shù)據(jù)樹,這可能證實了LLM的推理過程更可能是概率模式匹配而不是形式推理。
理解token-bias現(xiàn)象和模型幻覺
Token-bias現(xiàn)象首次發(fā)現(xiàn)于賓夕法尼亞大學(xué)Bowen Jiang等人的研究(arXiv:2406.11050),并被蘋果公司的Iman Mirzadeh等人進(jìn)行了進(jìn)一步的研究(arXiv:2410.05229)。
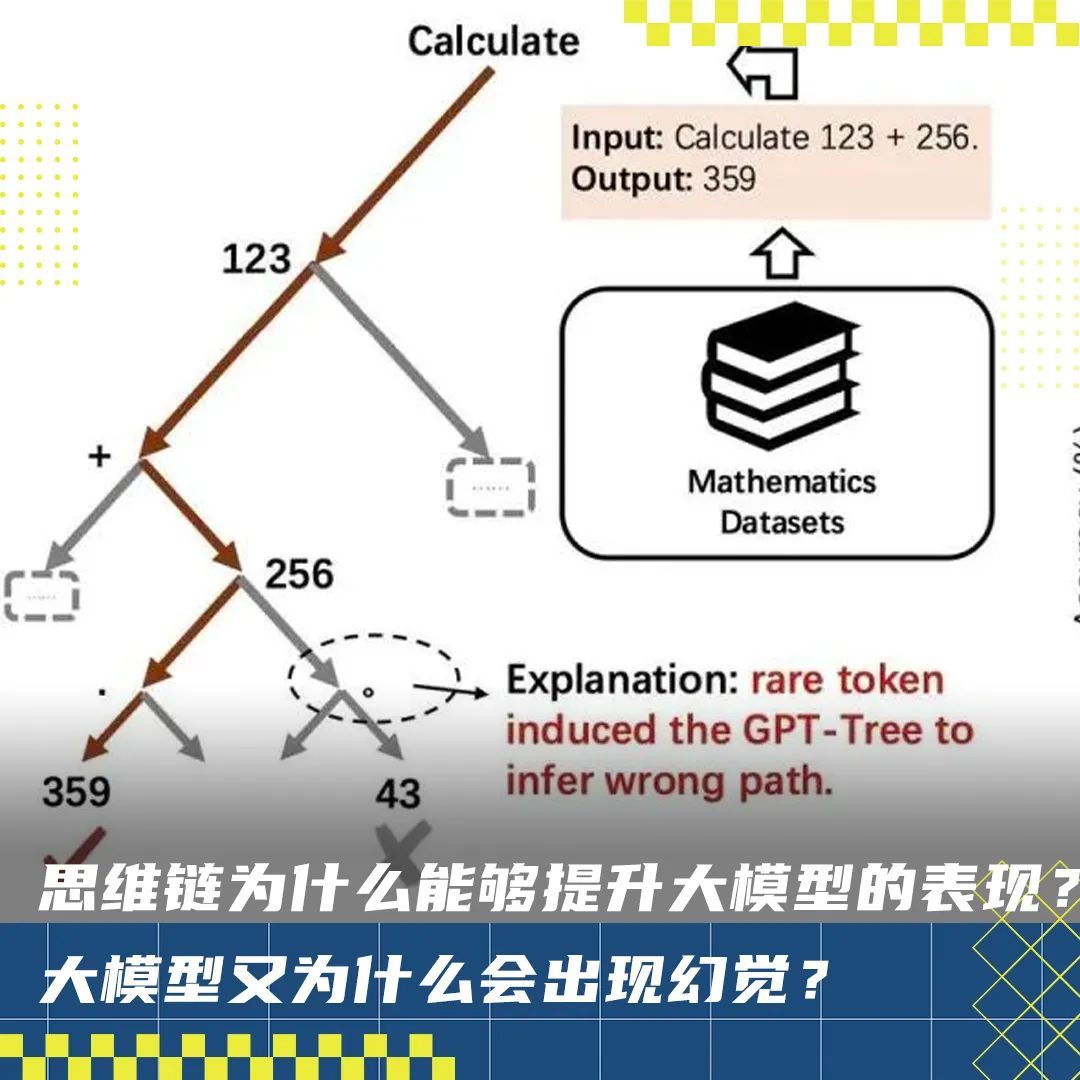
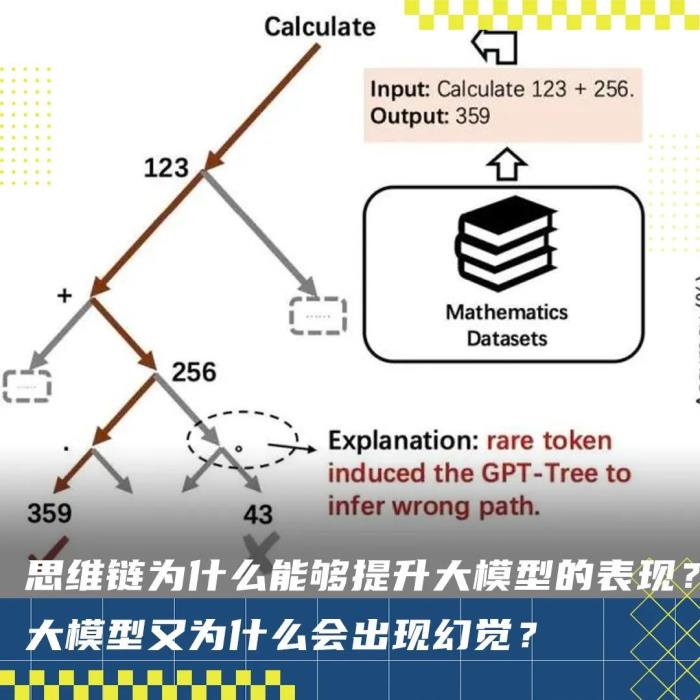
例如對于一個簡單的數(shù)學(xué)計算問題,“Calculate 123 + 256.”,將最后一個 token“.”擾動成“。”,模型就會錯誤地回答為“43”。
作者認(rèn)為,token-bias是由于一些罕見的token誘導(dǎo)GPT-Tree推斷錯誤的路徑。
作者通過評估21076對QA測試對中不同模型的原始(藍(lán)色條)和擾動(橙色條)精度進(jìn)一步量化了這一現(xiàn)象。
擾動最后一個token后,所有模型的準(zhǔn)確性都顯著下降。

而至于模型幻覺,作者認(rèn)為這是由數(shù)據(jù)樹的共現(xiàn)偏差造成。
如下圖所示,訓(xùn)練數(shù)據(jù)表現(xiàn)出多倫多和加拿大這兩個術(shù)語的高頻共現(xiàn),導(dǎo)致模型嚴(yán)重傾向于這些語料庫,從而錯將多倫多認(rèn)為是加拿大首都。

理解思維鏈的有效性
在蒙特卡洛樹的視角下,思維鏈的有效性也有了新的解釋。
對于一些復(fù)雜的問題,輸入X和輸出Y之間存在明顯的 Gap,使得GPT模型難以直接從X中輸出Y。
從GPT-tree的視角來看,輸入X位于父節(jié)點,輸出Y位于比較深的葉節(jié)點。
思維鏈的原理就是試圖彌補這一缺口,即試圖尋找路徑Z來幫助GPT模型更好的連接X和Y。

Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
