

 新火種
2025-02-18
新火種
2025-02-18 


大模型爆火,文心一言起大早,趕晚集?

2月13日,百度宣布4月1日起文心一言將全面免費。
2月14日,百度宣布文心下一代模型4.5系列6月30日起開源。

受相關消息影響,截至2月13日港股收盤,百度集團股價當日累計上漲5.74%,報收94港元/股。要知道百度是國內最早的大模型,此前,文心一言采取基礎版免費、專業版收費的模式,專業版定價59.9元/月,連續包月優惠價49.9元/月。
而現在國內的大模型們,通義千問、Kimi、豆包、騰訊混元、deepseek如雨后春筍,文心一言起了個大早,趕上這晚集了嗎?
01
曾是大模型賽道的先行者
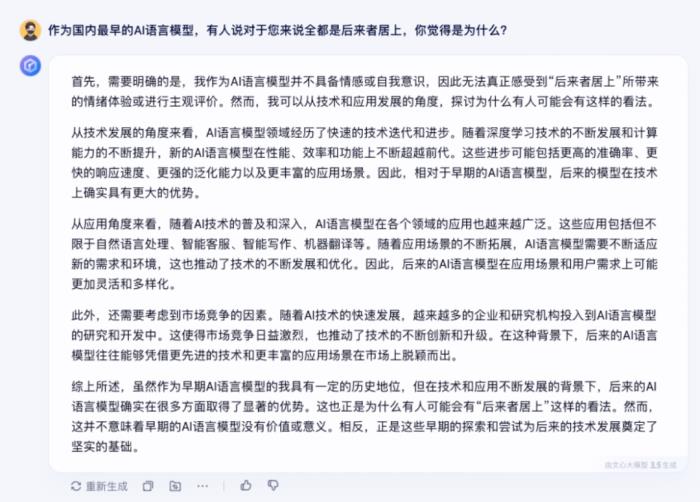
文心一言:作為國內最早的AI語言模型,有人說對于您來說全都是后來者居上,你覺得是為什么?
ChatGPT爆火后,大模型對個人生產力的提升,以及在各行業的巨大商業價值愈加清晰。2023年2月,就在百度公開宣布要推出“文心一言”之際,百度搜索、智能云到自動駕駛等各產品方面的合作方隨即明確需要這樣的產品,很快,超過600家合作伙伴宣布加入文心一言生態,期待盡早用上最新最先進的大語言模型。
2023年3月16日,百度新一代大語言模型文心一言正式啟動邀測。8月31日,文心一言率先向全社會全面開放。開放首日,文心一言共計回復網友超3342萬個問題。12月28日,百度首席技術官王海峰在第十屆WAVE SUMMIT深度學習開發者大會上宣布文心一言用戶規模已突破1億。
當時的李彥宏說:文心一言將改變云計算游戲規則。
百度高管誠實表示文心一言還不夠成熟之時,百度股價應聲而落:李彥宏誠實指出,自己體驗時并不完美,這類大語言模型還遠未到發展完善的階段;百度首席技術官王海峰也提到模型目前“訓練不夠充分”。
2025年的今天,文心一言好像也沒有突破以上“不完美”,于是我向他提了這個問題。文心一言回答了我很多,其中它總結說“雖然作為早期AI語言模型的我具有一定的歷史地位,但在技術和應用不斷發展的背景下,后來的A語言模型確實在很多方面取得了顯著的優勢。”
02
很早卻很后
盡管“起大早”,但“文心一言”是否真的領先?
百度深耕AI領域十余年,從底層的高端芯片昆侖芯,到飛槳深度學習框架,再到文心預訓練大模型,到搜索、智能云、自動駕駛、小度等應用,形成了全球范圍內少有的在“芯片-框架-模型-應用”的IT四層技術棧架構,并且各個層面都有領先業界的自研技術和產品。
從優勢來看,文心一言背靠百度強大數據和技術積累,擁有海量中文語料庫,在中文理解方面具有一定優勢。剛才提到它擁有超過600家合作伙伴,百度根式積極布局應用生態,與多家企業合作,推動產品落地。
算力芯片,是至關重要的。2021年6月,百度智能芯片及架構部門完成獨立融資,成立昆侖芯(北京)科技有限公司,首輪估值約130億元,百度芯片首席架構師歐陽劍出任昆侖芯公司CEO。在此之前一年,百度已經試產了第一代云端通用人工智能計算處理器“昆侖1”芯片,這在當時國內唯一一款經歷過互聯網大規模核心算法考驗的云端AI芯片。在芯片部門獨立融資兩個月后,百度就宣布第二代昆侖芯片“昆侖2”正式量產。
不難看出,百度在AI領域的布局極為宏大,野心勃勃。“文心一言”不過是基于百度文心大模型展開研發進程中的一個微小環節。從百度文心官網呈現的內容便能窺知一二,在文心大模型的整體規劃里,對話功能僅僅占據了極小的一部分。不妨設想一下,倘若沒有ChatGPT突如其來地在全球范圍內掀起巨大波瀾,引發廣泛關注,也許“文心一言”還會在項目排期表上沉寂許久,許久都難有問世的機會。
反觀DeepSeek,成功好像不是偶然。
從最直觀的下載量來看,DeepSeek在140個市場的應用商店下載排行榜上居首位,短短18天,下載量達到1600萬次,超過ChatGPT同期表現。
DeepSeek - R1模型訓練使用了約2000個英偉達專用芯片,能充分利用英偉達芯片強大的并行計算能力和CUDA生態系統,實現高效的深度學習計算。在硬件適配方面,DeepSeek也在積極探索與國產硬件的結合,如昇騰、海光等芯片,稀疏計算等技術使其在國產硬件上也能有較好的性能表現,降低了對特定國外芯片的依賴。
由于其創新的架構設計和訓練策略,DeepSeek在推理等任務中對芯片的需求相對靈活,訓練時僅需百卡級規模。
除了DeepSeek,可靈、即夢、豆包這些平臺可能采用輕量化模型或定制化架構,注重交互體驗和特定場景的優化(如創意生成、對話交互)。總的來看,DeepSeek 適合復雜任務和技術場景。文心一言在中文處理和文化理解上表現突出。可靈、即夢、豆包更適合創意生成和輕量級交互。
03
百度,能趕上晚集嗎?
追求短期商業化,忽視技術深度研發,是網友在文心一言宣布開源之前對它的評價。
文心一言的不足確實很明顯,在技術層面與領先模型相比,在邏輯推理、創造性文本生成等方面存在差距。在應用層面,實際應用場景有限,用戶體驗有待提升,缺乏現象級應用案例。在生態層面,開源生態建設滯后,開發者社區活躍度不高。
而百度文心一言宣布將于4月1日零時起取消收費限制,向所有用戶開放其最新模型及全部高級功能,這一決策標志著國產大模型服務正式進入普惠化階段。
文心一言還同步上線了深度搜索功能。這項新功能具備更強大的思考規劃能力和工具調用能力,能夠為用戶提供專家級的內容回復,并可以處理多場景任務,實現多模態的輸入與輸出。目前,用戶可以在文心一言官網率先體驗這一功能,移動端App的相關功能也將很快推出。
這一舉措不僅體現了文心大模型在技術迭代和成本優化方面取得的突破,更展現出百度在AI領域的戰略布局和市場競爭決心。隨著免費開放政策的實施,AI技術的應用門檻將進一步降低,這對推動人工智能技術的普及和創新發展具有重要意義。
李彥宏本是大模型閉源的支持者。在2024世界人工智能大會等場合,他多次表達了對閉源大模型的支持觀點。
從性能和成本角度來看,李彥宏認為同樣參數規模下,開源模型能力不如閉源,開源模型若想追平閉源,需要更大參數規模,這意味著推理成本更高、反應速度更慢。而閉源模型通常由專業團隊針對特定用途優化,與專門硬件緊密集成,可實現規模經濟,推理成本更低。
盡管他認為開源大模型在學術研究、教學領域等特定場景下有存在的價值,但在激烈的商業競爭環境中,需要讓業務效率比同行更高、成本比同行更低,這時商業化的閉源模型是最能打的。
李彥宏曾表示,閉源才有真正的商業模式,才能聚集人才和算力,優秀人才會更傾向于選擇閉源模型的團隊,因為閉源可以提供更好的資源和發展空間。
DeepSeek等的崛起給文心一言帶來一定壓力,而開源可吸引更多開發者和用戶,提升百度在市場中的競爭力。另一方面,隨著技術發展,大模型推理成本大幅下降,百度有條件進行開源,推動技術更廣泛應用。
AI是否也將走向價格戰?文心一言同步宣布免費的還有OpenAI。北京時間2月13日凌晨3點,OpenAI首席執行官Sam Altman也公布了GPT-4.5/5將很快陸續發布,免費版ChatGPT將在標準智能設置下無限制使用GPT-5進行對話。據悉,OpenAI很快發布GPT-4.5,就是傳說中的獵戶座模型(Orion),也是最后一個非思維鏈模型。接著會整合GPT和O系列兩大模型打造一個全新的系統,能自動選擇思考和非思考功能,適用于多種任務。奧爾特曼稱,這將是OpenAI最后一個“非思維鏈模型”。與o3及OpenAI其他推理模型不同,非思維鏈模型在數學和物理等領域往往不太可靠。
推動兩大閉源模型的DeepSeek是這么看文心一言的翻盤的:

百度系股票應聲大漲,對企業級用戶大面積部署可謂利好,但能否成為李彥宏口中的超級應用?讓我們拭目以待。
原文標題:大模型爆火,文心一言起大早,趕晚集?
Tags:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
