

 新火種
2025-02-12
新火種
2025-02-12 


DeepSeek又有重大突破?一款未公開大模型展現驚人能力
DeepSeek再一次發布了強大的開源大模型。
1月20日,國內大模型公司深度求索(DeepSeek)在其公眾號公布了新一代開源大模型DeepSeek-R1,該模型號稱在數學、代碼、自然語言推理等任務上,性能比肩美國OpenAI公司最新的o1大模型正式版。
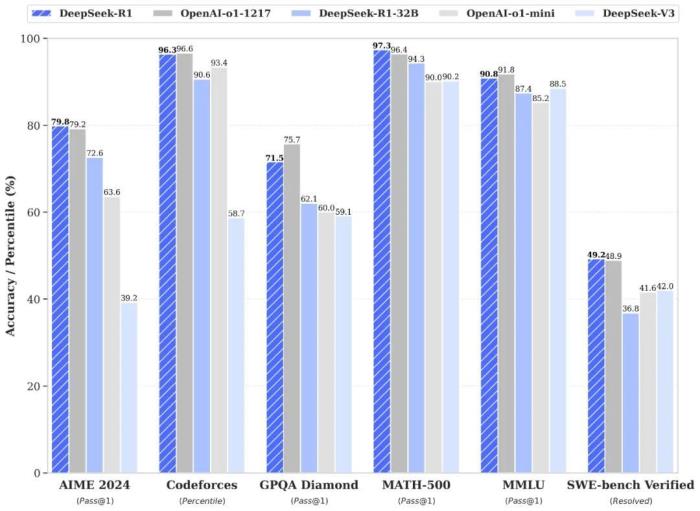
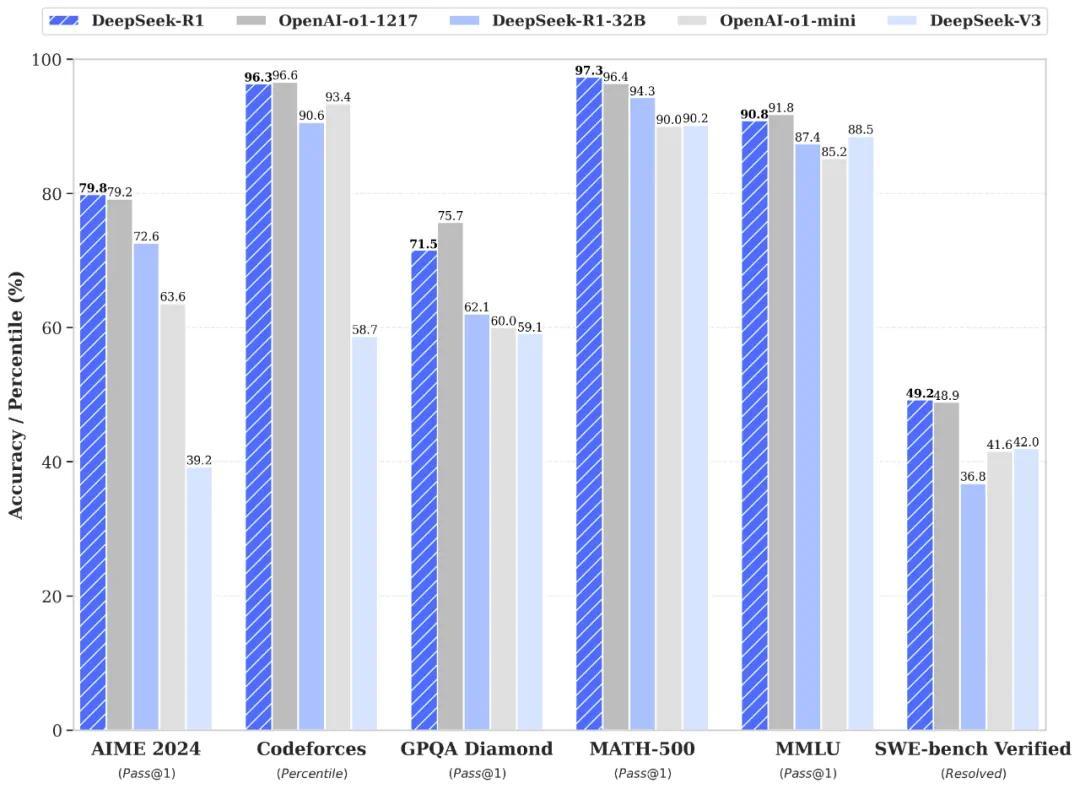
根據數據,DeepSeek-R1在算法類代碼場景(Codeforces)和知識類測試(GPQA、MMLU)中的得分略低于OpenAI o1,但在工程類代碼場景(SWE-Bench Verified)、美國數學競賽(AIME 2024, MATH)項目上,均超過了OpenAI o1 。
其中,與深度求索上月發布的大模型DeepSeek-V3相比,DeepSeek-R1在AIME 2024和Codeforces中的得分提升了近一倍,而其余項均有不同程度的提升。
深度求索還更新了用戶協議,明確模型開源License將統一使用標準的MIT許可,同時還允許用戶利用模型輸出、通過模型蒸餾等方式訓練其他模型。按照深度求索數據顯示,在以DeepSeek-R1基礎上進行“蒸餾”的6個小模型中,32B和70B模型在多項能力上都實現了對標OpenAI的o1-mini 的效果。
面對這個令人矚目的成績,深度求索則解釋稱,DeepSeek-R1 后訓練階段中大規模使用了強化學習(RL)技術,在僅有極少人工標注數據的情況下,極大提升了模型推理能力。這意味著該模型幾乎跳過了監督微調(SFT)步驟,就實現了推理能力自我提升。

DeepSeek-R1-Zero自然而然地學會用更多的思考時間來解決推理任務。深度求索
通常情況下,強化學習的好處是可以通過與外界評價反饋,不斷讓模型自我優化,生成更符合人類偏好的內容。而監督微調則是指在預訓練使用人工標注的數據進行干預,可以讓生成的內容更準確且符合預期,這也是當年ChatGPT成功的關鍵。但從成本上來說,強化學習雖然需要大量人類反饋,且訓練復雜計算成本高,但監督微調則非常依賴高質量的人工標注數據。
值得注意的是,目前深度求索向用戶提供的僅有DeepSeek-R1版本,而在其公開測試結果中卻透露了另一個大模型 —— DeepSeek-R1-Zero。該模型完全通過大規模使用強化學習替代了監督微調,但也導致了一些問題,因此未對外公開。
更重要的是,工作人員發現,在DeepSeek-R1-Zero自我學習的過程,隨著時間的增加,該模型“涌現”出了復雜的行為,如自我反思、評估先前步驟、自發尋找替代方案的情況,還包括一次“尤里卡時刻”(“aha moment)。

“尤里卡時刻”指人類突然理解一個以前無法理解的問題或概念的某個時刻。
深度求索透露,這次“尤里卡”發生在DeepSeek-R1-Zero的的中間版本期間。當時工作人員驚奇地發現,在一道數學題中,該模型學會了使用擬人化的語氣進行自我反思,并主動為問題分配了更多地時間進行重新思考。
深度求索稱,工作人員并沒有教DeepSeek-R1-Zero如何解決問題,只是提供了正確的激勵,它就能自主發展出先進的問題解決策略。“這次尤里卡也提醒我們,強化學習有可能為人工智能解鎖新的智能水平,為以后發展出更自主和適應性的模型鋪平道路。”
不過,雖然DeepSeek-R1-Zero展示出了強大的推理能力,但自身也出現了一些語言混亂及可讀性的問題,因此深度求索通過引入數千條高質量的冷啟動數據和多段強化學習來解決這些問題,并獲得了上文中對外正式公布的DeepSeek-R1大模型。
目前,DeepSeek-R1 API 服務定價為每百萬輸入 tokens 1 元(緩存命中)/ 4 元(緩存未命中),每百萬輸出 tokens 16 元。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
