

 新火種
2023-09-08
新火種
2023-09-08 


不吃蘑菇,不撿金幣,我用強化學習跑通29關馬里奧,刷新最佳戰績
機器之心報道
編輯:張倩、蛋醬

看了用強化學習訓練的馬里奧,我才知道原來這個游戲的后幾關長這樣。

《超級馬里奧兄弟》是任天堂公司開發并于 1985 年出品的著名橫版過關游戲,最早在紅白機上推出,有多款后續作品,迄今多個版本總銷量已突破 5 億套。
這款游戲承載了一代人的回憶,你還記不記得你玩到過第幾關?
其實,除了我們這些玩家之外,強化學習研究者也對這款游戲情有獨鐘。
最近,有人用 PPO 強化學習算法訓練了一個超級馬里奧智能體,已經打通了 29 關(總共 32 關),相關代碼也已開源。

PPO 算法的全稱是 Proximal Policy Optimization(近端策略優化),是 OpenAI 在 2017 年發布的一種強化學習算法。該算法的實現和調參十分簡單,在強化學習中的表現優于當時所有頂尖算法的水平,因此被 OpenAI 作為強化學習研究中的首選算法。
使用 PPO 訓練的 OpenAI Five 是第一款在電競游戲中擊敗人類世界冠軍的 AI。2018 年 8 月,OpenAI Five 與 Ti8Dota2 世界冠軍 OG 戰隊展開了一場巔峰對決,最終 OpenAI Five 以 2:0 的比分輕松戰勝世界冠軍 OG。
此前,作者曾經使用 A3C 算法訓練過用于通關超級馬里奧兄弟的智能體。盡管智能體可以又快又好地完成游戲,但整體水平是有限的。無論經過多少次微調和測試,使用 A3C 訓練的智能體只能完成到第 9 關。同時作者也使用過 A2C 和 Rainbow 等算法進行訓練,前者并未實現性能的明顯提升,后者更適用于隨機環境、游戲,比如乒乓球或太空侵略者。
還有三關沒有過是怎么回事?作者解釋說,4-4、7-4 和 8-4 關的地圖都包含了一些謎題,智能體需要選擇正確的路徑才能繼續前進。如果選錯了路徑,就得重新把走過的路再走一遍,陷入死循環。所以智能體沒能通過這三關。
近端策略優化算法
策略梯度法(Policy gradient methods)是近年來使用深度神經網絡進行控制的突破基礎,不管是視頻游戲、3D 移動還是圍棋控制,都是基于策略梯度法。但是通過策略梯度法獲得優秀的結果是十分困難的,因為它對步長大小的選擇非常敏感。如果迭代步長太小,那么訓練進展會非常慢,但如果迭代步長太大,那么信號將受到噪聲的強烈干擾,因此我們會看到性能的急劇降低。同時這種策略梯度法有非常低的樣本效率,它需要數百萬(或數十億)的時間步驟來學習一個簡單的任務。
2017 年,Open AI 的研究者為強化學習提出了一種新型策略梯度法,它可以通過與環境的交互而在抽樣數據中轉換,還能使用隨機梯度下降優化一個「surrogate」目標函數。標準策略梯度法為每一個數據樣本執行一個梯度更新,因此研究者提出了一種新的目標函數,它可以在多個 epoch 中實現小批量(minibatch)更新。這種方法就是近端策略優化(PPO)算法。
該算法從置信域策略優化(TRPO)算法獲得了許多啟發,但它更加地易于實現、廣泛和有更好的樣本復雜度(經驗性)。經過在一組基準任務上的測試,包括模擬機器人移動和 Atari 游戲,PPO 算法展示出了比其他在線策略梯度法更優秀的性能,該算法總體上在樣本復雜度、簡單性和實際時間(wall-time.)中有非常好的均衡。
近端策略優化可以讓我們在復雜和具有挑戰性的環境中訓練 AI 策略
如上所示,其中智能體嘗試抵達粉紅色的目標點,因此它需要學習怎樣走路、跑動和轉向等。同時該智能體不僅需要學會怎樣從小球的打擊中保持平衡(利用自身的動量),在被撞倒后還需要學會如何從草地上站起來。
PPO 方法有兩種主要的變體: PPO-Penalty 和 PPO-Clip。
PPO-Penalty 近似求解一個類似 TRPO 的被 KL - 散度約束的更新,但懲罰目標函數中的 KL - 散度,而不是使其成為優化問題的硬約束, 并在訓練過程中自動調整懲罰系數,從而適當地調整其大小。
PPO-Clip 在目標中沒有 KL 散度項,也沒有約束。取而代之的是在目標函數上進行專門裁剪 (clip), 以消除新策略遠離舊策略的激勵 (incentives)。
關于該算法的更多信息可以參考原論文。

網友:馬里奧的奔跑,是我放蕩不羈的青春
項目作者用 Pytorch 實現的《超級馬里奧》demo 在 reddit 上引起了上千人圍觀,作者也現身評論區答疑解惑。
有人說,「他跑得那么快、那么不管不顧,看得我捏了一把汗。」

這種六親不認的步伐甚至讓某些人想起了自己放蕩不羈的青春。
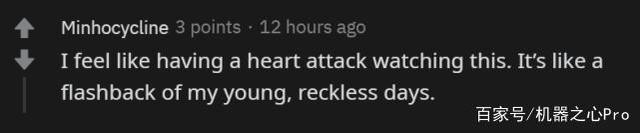
「跑這么快,你撿錢和蘑菇了嗎?」這個馬里奧的迷之操作讓人覺得有點困惑。甚至有人調侃說,「這應該是史上最『節儉』的馬里奧了。」
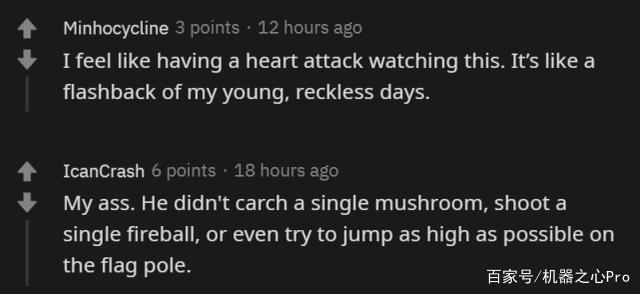
當然,也有人問技術方面的問題,比如說:「是不是為每一關都訓練了一個單獨的智能體?有沒有嘗試過訓練一個智能體打通所有關?」
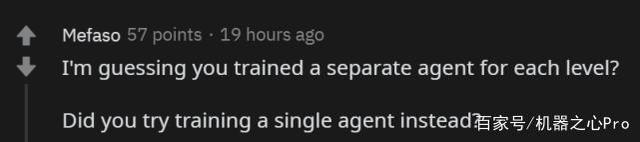
作者表示,確實每關都是單獨訓練的,中間也嘗試過訓練一個智能體智能體跑所有關,但沒成功。

評論區還存在其他的質疑,比如過擬合問題。
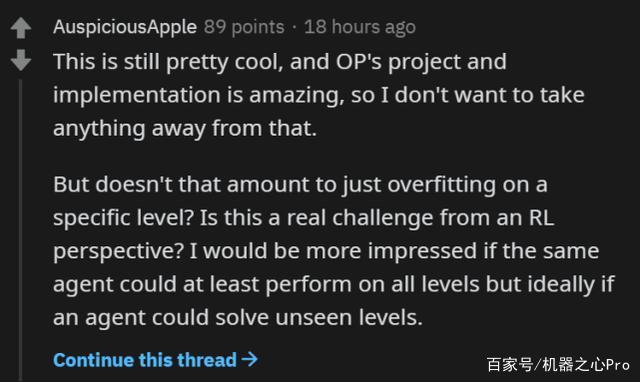
但無論如何,有一點是值得欣慰的:這個實現借助強化學習之手,讓我們看到了二十關以后的樣子。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
