

 新火種
2025-01-16
新火種
2025-01-16 


阿里云通義開源最強過程獎勵PRM模型7B尺寸比GPT-4o更能發(fā)現(xiàn)推理錯誤
1月16日消息,今日,阿里云通義開源全新的數(shù)學推理過程獎勵模型Qwen2.5-Math-PRM,72B及7B尺寸模型性能均大幅超越同類開源過程獎勵模型。
據(jù)悉,在識別推理錯誤步驟能力上,Qwen2.5-Math-PRM以7B的小尺寸超越了GPT-4o。同時,通義團隊還開源了首個步驟級的評估標準 ProcessBench,此項評估標準填補了大模型推理過程錯誤評估的空白。
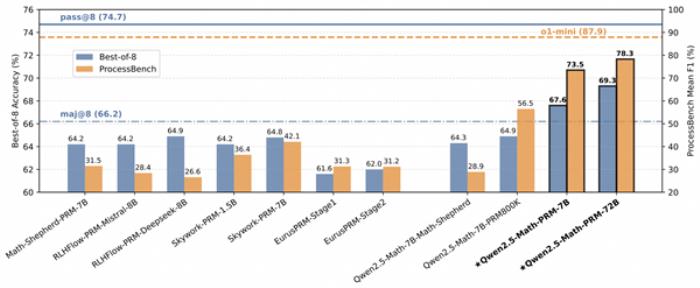
據(jù)了解,為更好衡量模型識別數(shù)學推理中錯誤步驟的能力,通義團隊提出的全新評估標準ProcessBench。該基準由3400個數(shù)學問題測試案例組成,其中還包含奧賽難度的題目,每個案例都有人類專家標注的逐步推理過程,可綜合全面評估模型識別錯誤步驟能力。這一評估標準也已開源。
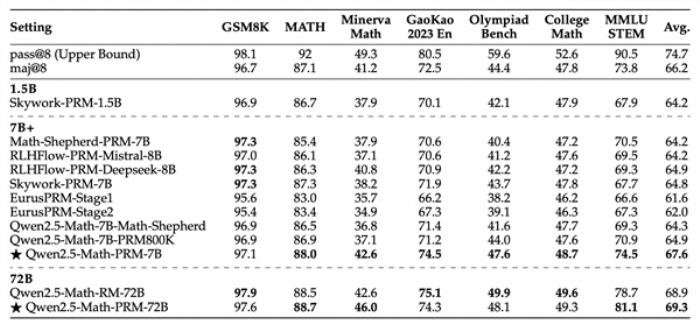
此外,在ProcessBench上對錯誤步驟的識別能力的評估中,72B及7B尺寸的Qwen2.5-Math-PRM均顯示出顯著的優(yōu)勢,7B版本的PRM模型不但超越同尺寸開源PRM模型,甚至超越了閉源GPT-4o-0806。這證明了過程獎勵模型(PRM)能夠顯著提高推理的可靠性,為未來開發(fā)推理過程監(jiān)督技術開辟了新的途徑。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
