

 新火種
2025-01-16
新火種
2025-01-16 


MiniMax震撼開源,突破傳統(tǒng)Transformer架構(gòu),4560億參數(shù),支持400萬長上下文
「2025 年,我們可能會看到第一批 AI Agent 加入勞動力大軍,并對公司的生產(chǎn)力產(chǎn)生實質(zhì)性的影響。」——OpenAI CEO Sam Altman
「2025 年,每個公司都將擁有 AI 軟件工程師 Agent,它們會編寫大量代碼。」——Meta CEO Mark Zuckerberg
「未來,每家公司的 IT 部門都將成為 AI Agent 的 HR 部門。」—— 英偉達 CEO 黃仁勛
2025 新年伊始,在很多趨勢都還不明朗的情況下,幾位 AI 業(yè)界的重要人物幾乎在同一時間做出了類似的判斷 ——2025 年將是 AI Agent 之年。
沒想到,MiniMax 很快就有了動作:開源了最新的基礎(chǔ)語言模型 MiniMax-Text-01 和視覺多模態(tài)模型 MiniMax-VL-01。
新模型的最大亮點是,在業(yè)內(nèi)首次大規(guī)模實現(xiàn)了新的線性注意力機制,這使得輸入的上下文窗口大大變長:一次可處理 400 萬 token,是其他模型的 20-32 倍。
他們相信,這些模型能夠給接下來一年潛在 Agent 相關(guān)應(yīng)用的爆發(fā)做出貢獻。
為什么這項工作對于 Agent 如此重要?
隨著 Agent 進入應(yīng)用場景,無論是單個 Agent 工作時產(chǎn)生的記憶,還是多個 Agent 協(xié)作所產(chǎn)生的 context,都會對模型的長上下文窗口提出更多需求。

開源地址:https://github.com/MiniMax-AIHugging Face:https://huggingface.co/MiniMaxAI技術(shù)報告:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf網(wǎng)頁端:https://www.hailuo.aiAPI:https://www.minimaxi.com/platform一系列創(chuàng)新造就比肩頂尖模型的開源模型MiniMax-Text-01 究竟是如何煉成的?事實上,他們?yōu)榇诉M行了一系列創(chuàng)新。從新型線性注意力到改進版混合專家架構(gòu),再到并行策略和通信技術(shù)的優(yōu)化,MiniMax 解決了大模型在面對超長上下文時的多項效果與效率痛點。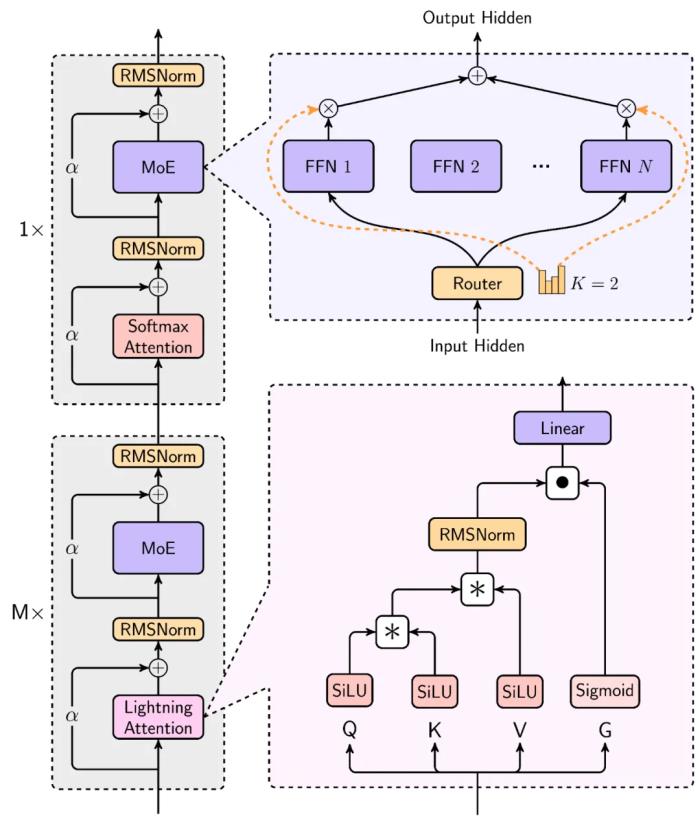
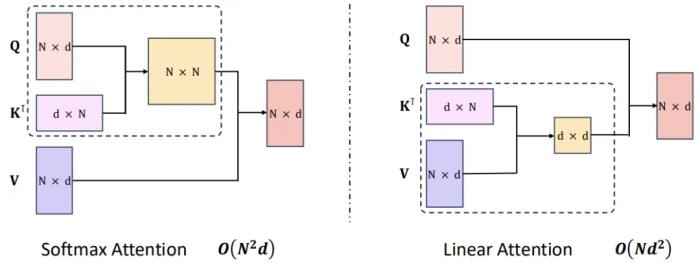
MiniMax-Text-01 的架構(gòu)Lightning Attention目前領(lǐng)先的 LLM 大都基于 Transformer,而 Transformer 核心的自注意力機制是其計算成本的重要來源。為了優(yōu)化,研究社區(qū)可以說是絞盡腦汁,提出了稀疏注意力、低秩分解和線性注意力等許多技術(shù)。MiniMax 的 Lightning Attention 便是一種線性注意力。通過使用線性注意力,原生 Transformer 的計算復(fù)雜度可從二次復(fù)雜度大幅下降到線性復(fù)雜度,如下圖所示。
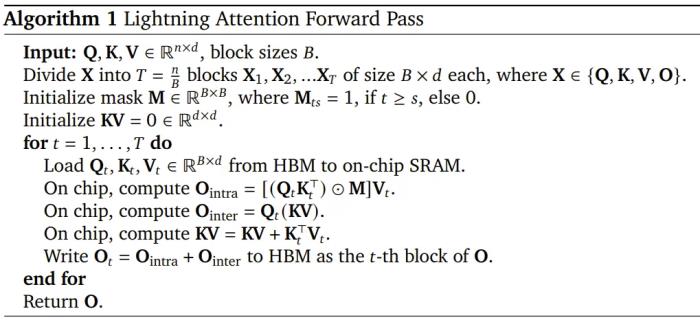
MiniMax 的相關(guān)技術(shù)報告中寫道,這主要是得益于一種右邊積核技巧(right product kernel trick)。以 2022 年論文《The Devil in Linear Transformer》中的 TransNormer 為例,下圖左側(cè)的 NormAttention 機制可轉(zhuǎn)換成使用「右側(cè)矩陣乘法」的線性變體。 而 Lightning Attention 便是基于 TransNormer 實現(xiàn)的一個 I/O 感知型優(yōu)化版本。以下是 Lightning Attention 前向通過的算法描述。
而 Lightning Attention 便是基于 TransNormer 實現(xiàn)的一個 I/O 感知型優(yōu)化版本。以下是 Lightning Attention 前向通過的算法描述。
基于 Lightning Attention,MiniMax 還提出了一種 Hybrid-lightning,即每隔 8 層將 Lightning Attention 替換成 softmax 注意力,從而既解決了 softmax 注意力的效率問題,也提升了 Lightning Attention 的 scaling 能力。效果如何?下表給出了根據(jù)層數(shù) l、模型維度 d、批量大小 b 和序列長度 n 計算注意力架構(gòu)參數(shù)量與 FLOPs 的公式。 可以明顯看出,模型規(guī)模越大,Lightning Attention 與 Hybrid-lightning 相對于 softmax 注意力的優(yōu)勢就越明顯。混合專家(MoE)MoE 相對于密集模型的效率優(yōu)勢已經(jīng)得到了大量研究證明。MiniMax 團隊同樣也進行了一番比較實驗。他們比較了一個 7B 參數(shù)的密集模型以及 2B 激活參數(shù)和 20B 總參數(shù)的 MoE 模型。結(jié)果如下圖所示。
可以明顯看出,模型規(guī)模越大,Lightning Attention 與 Hybrid-lightning 相對于 softmax 注意力的優(yōu)勢就越明顯。混合專家(MoE)MoE 相對于密集模型的效率優(yōu)勢已經(jīng)得到了大量研究證明。MiniMax 團隊同樣也進行了一番比較實驗。他們比較了一個 7B 參數(shù)的密集模型以及 2B 激活參數(shù)和 20B 總參數(shù)的 MoE 模型。結(jié)果如下圖所示。
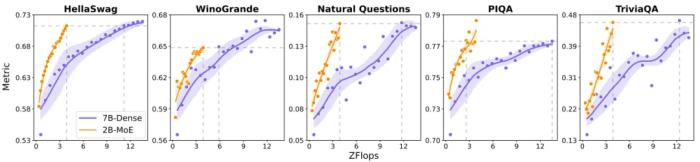
可以看到,在多種基準(zhǔn)上,當(dāng)計算負載一樣時,MoE 模型的表現(xiàn)要大幅優(yōu)于密集模型。MiniMax 還引入了一個新的 allgather 通信步驟,可解決擴大 MoE 模型的規(guī)模時可能會遇到路由崩潰(routing collapse)問題。計算優(yōu)化與許多大模型訓(xùn)練項目一樣,MiniMax 先通過小規(guī)模實驗上述技術(shù)改進的有效性以及 Scaling Law,然后再開始著手大規(guī)模訓(xùn)練。MiniMax 為此采用了 1500 到 2500 臺 H800 GPU—— 并且在訓(xùn)練過程中,具體使用 GPU 數(shù)量會動態(tài)變化。而大規(guī)模訓(xùn)練都有自己的特有挑戰(zhàn),MiniMax 開發(fā)了一系列針對性的優(yōu)化技術(shù)。首先,對于MoE 架構(gòu),最主要的優(yōu)化目標(biāo)是降低其通信負載。尤其是對于采用 all-to-all(a2a)通信的 MoE 模型。MiniMax 的解決方案是一種基于 token 分組的重疊方案。其次,對于長上下文訓(xùn)練,一大主要挑戰(zhàn)是難以將真實的訓(xùn)練樣本標(biāo)準(zhǔn)化到統(tǒng)一長度。傳統(tǒng)的方式是進行填充,但這種方法非常浪費計算。MiniMax 的解決思路是進行數(shù)據(jù)格式化,其中不同樣本會沿序列的維度首尾相連。他們將這種技術(shù)命名為 data-packing。這種格式可盡可能地降低計算過程中的計算浪費。最后,為了將Lightning Attention 投入實踐,MiniMax 采用了四項優(yōu)化策略:分批核融合、分離式的預(yù)填充與解碼執(zhí)行、多級填充、跨步分批矩陣乘法擴展。MiniMax-Text-01上下文巨長,能力也夠強基于以上一系列創(chuàng)新,MiniMax 最終得到了一個擁有32 個專家共4560 億參數(shù)的 LLM,每個 token 都會激活其中 459 億個參數(shù)。MiniMax 將其命名為 MiniMax-Text-01。在執(zhí)行推理時,它的上下文長度最高可達400 萬 token,并且其表現(xiàn)出了非常卓越的長上下文能力。MiniMax-Text-01 基準(zhǔn)成績優(yōu)秀在常見的學(xué)術(shù)測試集上,MiniMax-Text-01 基本上能媲美甚至超越 GPT-4o、Claude 3.5 Sonnet 等閉源模型以及 Qwen2.5、DeepSeek v3、Llama 3.1 等 SOTA 開源模型。下面直接上成績。
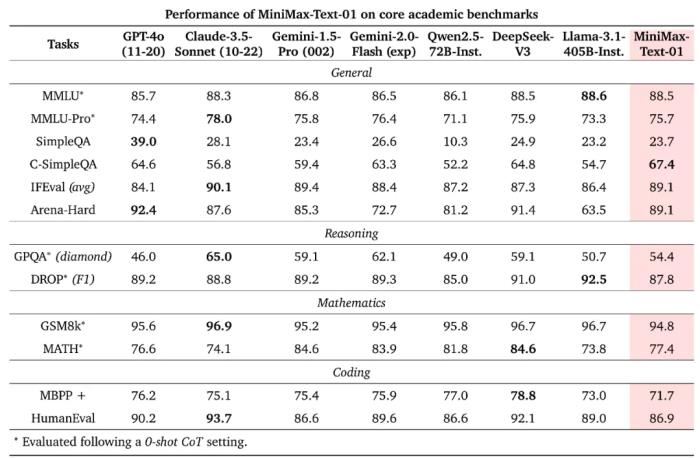
可以看到,在 HumanEval 上,MiniMax-Text-01 與 Instruct Qwen2.5-72B 相比表現(xiàn)出色。此外,MiniMax-Text-01 在 GPQA Diamond 這樣具有挑戰(zhàn)性問答的數(shù)據(jù)集上取得了 54.4 的成績,超過了大多數(shù)開源指令微調(diào)的 LLM 以及最新版本的 GPT-4o。MiniMax-Text-01 在 MMLU、IFEval 和 Arena-Hard 等測試中也取得了前三名的成績,展示了其在給定限制條件下,應(yīng)用全面知識來充分滿足用戶查詢、與人類偏好保持一致的卓越能力。可以想象,基于最新的模型能力,也給開發(fā)者開發(fā) Agent 應(yīng)用提供了更好的基礎(chǔ)。領(lǐng)先的上下文能力那 MiniMax-Text-01 引以為傲的長上下文能力呢?其優(yōu)勢就更為明顯了。在長上下文理解任務(wù)上,MiniMax 測試了 Ruler 和 LongBench v2 這兩個常見基準(zhǔn)。首先在 Ruler 上,可以看到,當(dāng)上下文長度在 64k 或更短時,MiniMax-Text-01 與其它 SOTA 模型不相上下,而當(dāng)上下文長度超過 128k 時,MiniMax-Text-01 的優(yōu)勢就明顯顯現(xiàn)出來了。
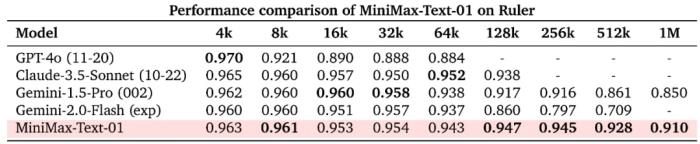
在 Ruler 上,MiniMax-Text-01 與其它模型的性能比較同樣,MiniMax-Text-01 在 LongBench v2 的長上下文推理任務(wù)上的表現(xiàn)也非常突出。
在 LongBench v2 上,MiniMax-Text-01 與其它模型的性能比較另外,MiniMax-Text-01 的長上下文學(xué)習(xí)能力(終身學(xué)習(xí)的一個核心研究領(lǐng)域)也是 SOTA 水平。MiniMax 在 MTOB 基準(zhǔn)上驗證了這一點。
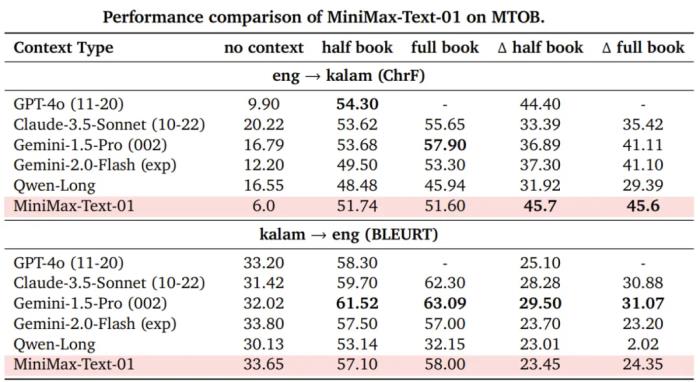
在 MTOB 上,MiniMax-Text-01 與其它模型的性能比較長文本能力ShowcaseMiniMax-Text-01 得到了很不錯的基準(zhǔn)分數(shù),但實際表現(xiàn)如何呢?下面展示了一些示例。首先,來寫首歌吧!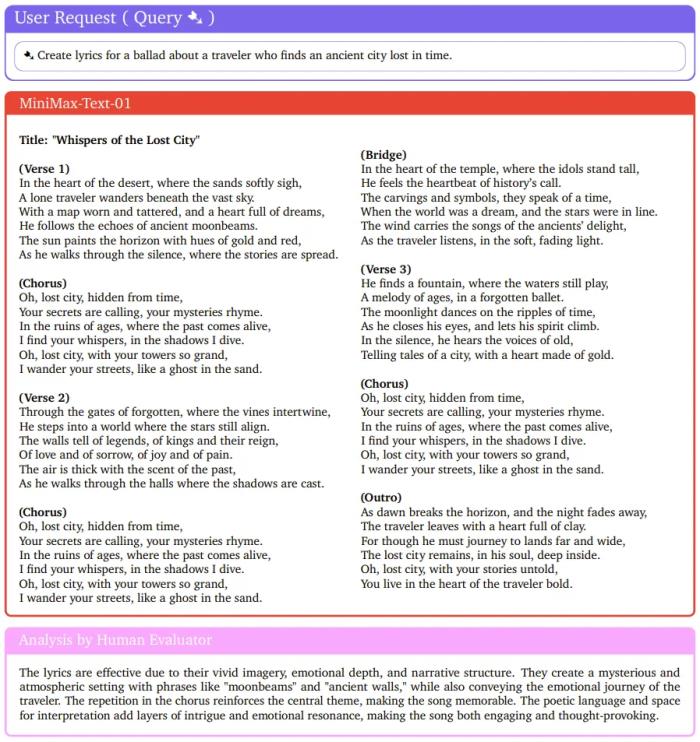
人類評估者也給出了非常正面的評價:詩意的語言和演繹空間為歌曲增添了層層的趣味和情感共鳴,使歌曲既引人入勝又發(fā)人深省。下面重點來看看 MiniMax-Text-01 的長上下文能力。對于新幾內(nèi)亞的一門小眾語言 Kalamang,先將指令、語法書、單詞表、與英語的對照例句放入 MiniMax-Text-01 的上下文,然后讓其執(zhí)行翻譯。可以看到,MiniMax-Text-01 給出的答案基本與標(biāo)準(zhǔn)答案一致。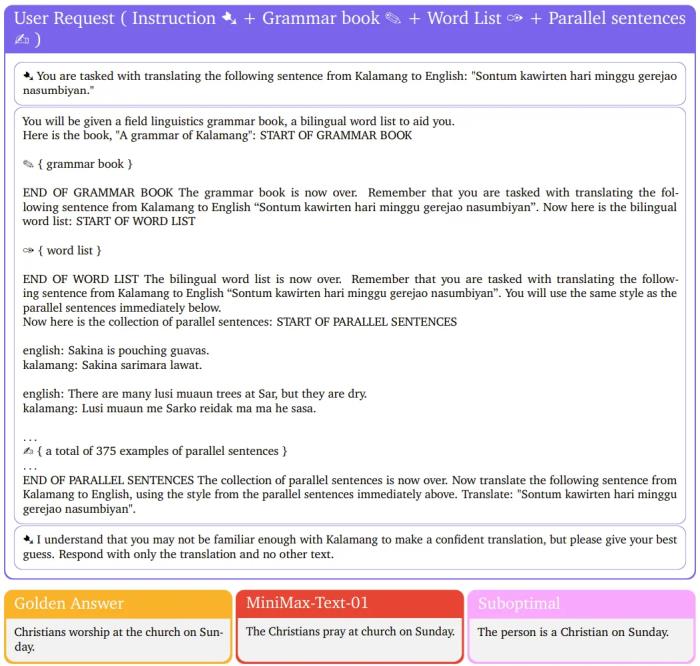
至于長對話記憶任務(wù),MiniMax-Text-01 可說是表現(xiàn)完美。
視覺-語言模型基于 MiniMax-Text-01,MiniMax 還開發(fā)了一個多模態(tài)版本:MiniMax-VL-01。思路很簡單,就是在文本模型的基礎(chǔ)上整合一個圖像編碼器和一個圖像適配器。簡而言之,就是要將圖像變成 LLM 能夠理解的 token 形式。因此,其整體架構(gòu)符合比較常見的 ViT-MLP-LLM 范式:MiniMax-VL-01 作為基礎(chǔ)模型,再使用一個 303M 參數(shù)的 ViT 作為視覺編碼器,并使用了一個隨機初始化的兩層式 MLP projector 來執(zhí)行圖像適應(yīng)。當(dāng)然,為了確保 MiniMax-VL-01 的視覺理解能力足夠好,還需要在文本模型的基礎(chǔ)上使用圖像-語言數(shù)據(jù)進行持續(xù)訓(xùn)練。為此,MiniMax 設(shè)計了一個專有數(shù)據(jù)集,并實現(xiàn)了一個多階段訓(xùn)練策略。最終,得到的 MiniMax-VL-01 模型在各個基準(zhǔn)上取得了如下表現(xiàn)。
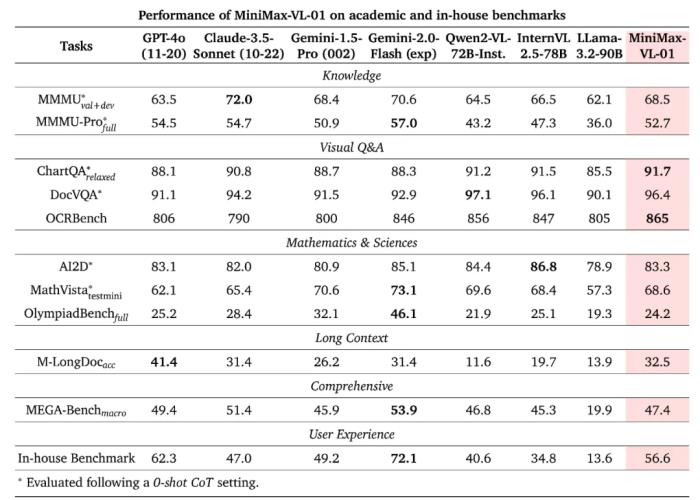
可以看到,MiniMax-VL-01 整體表現(xiàn)強勁,整體能與其它 SOTA 模型媲美,并可在某些指標(biāo)上達到最佳。下面展示了一個分析導(dǎo)航地圖的示例,MiniMax-VL-01 的表現(xiàn)可得一個贊。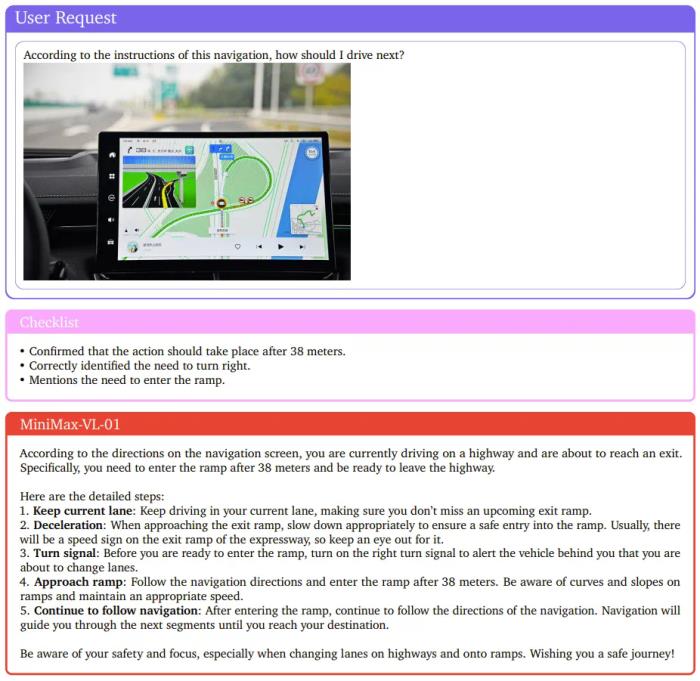
探索無限的上下文窗口讓 Agent 走進物理世界有人認為[1],context 會是貫穿 AI 產(chǎn)品發(fā)展的一條暗線,context 是否充分同步會直接影響智能應(yīng)用的用戶體驗,這包括用戶的個性化信息、環(huán)境變化信息等各種背景上下文信息。而為了保證 context 充分同步,足夠大的上下文窗口就成了大模型必須克服的技術(shù)難題。目前,MiniMax 已經(jīng)在這條路上邁出了重要的一步。不過,400 萬 token 的上下文窗口明顯不是終點。他們在技術(shù)報告中寫道:「我們正在研究更高效的架構(gòu),以完全消除 softmax 注意力,這可能使模型能夠支持無限的上下文窗口,而不會帶來計算開銷。」除此之外,MiniMax 還在 LLM 的基礎(chǔ)上訓(xùn)練的視覺語言模型,同樣擁有超長的上下文窗口,這也是由 Agent 所面臨的任務(wù)所決定的。畢竟,在現(xiàn)實生活中,多模態(tài)任務(wù)遠比純文本任務(wù)更常見。「我們認為下一代人工智能是無限接近通過圖靈測試的智能體,交互自然,觸手可及,無處不在。」MiniMax 創(chuàng)始人在去年的一次活動中提到。或許,「無處不在」也意味著,隨著多模態(tài) token 的加入,Agent 也將逐步進入物理世界。為此,AI 社區(qū)需要更多的技術(shù)儲備。
參考鏈接:[1]https://mp.weixin.qq.com/s/k43nIdVUV_Do7_dRcf4DsA
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責(zé)任。
