

 新火種
2025-01-15
新火種
2025-01-15 


DeepSeek把自己誤認成了ChatGPT?分析人士:或用了GPT生成文本做訓練數據
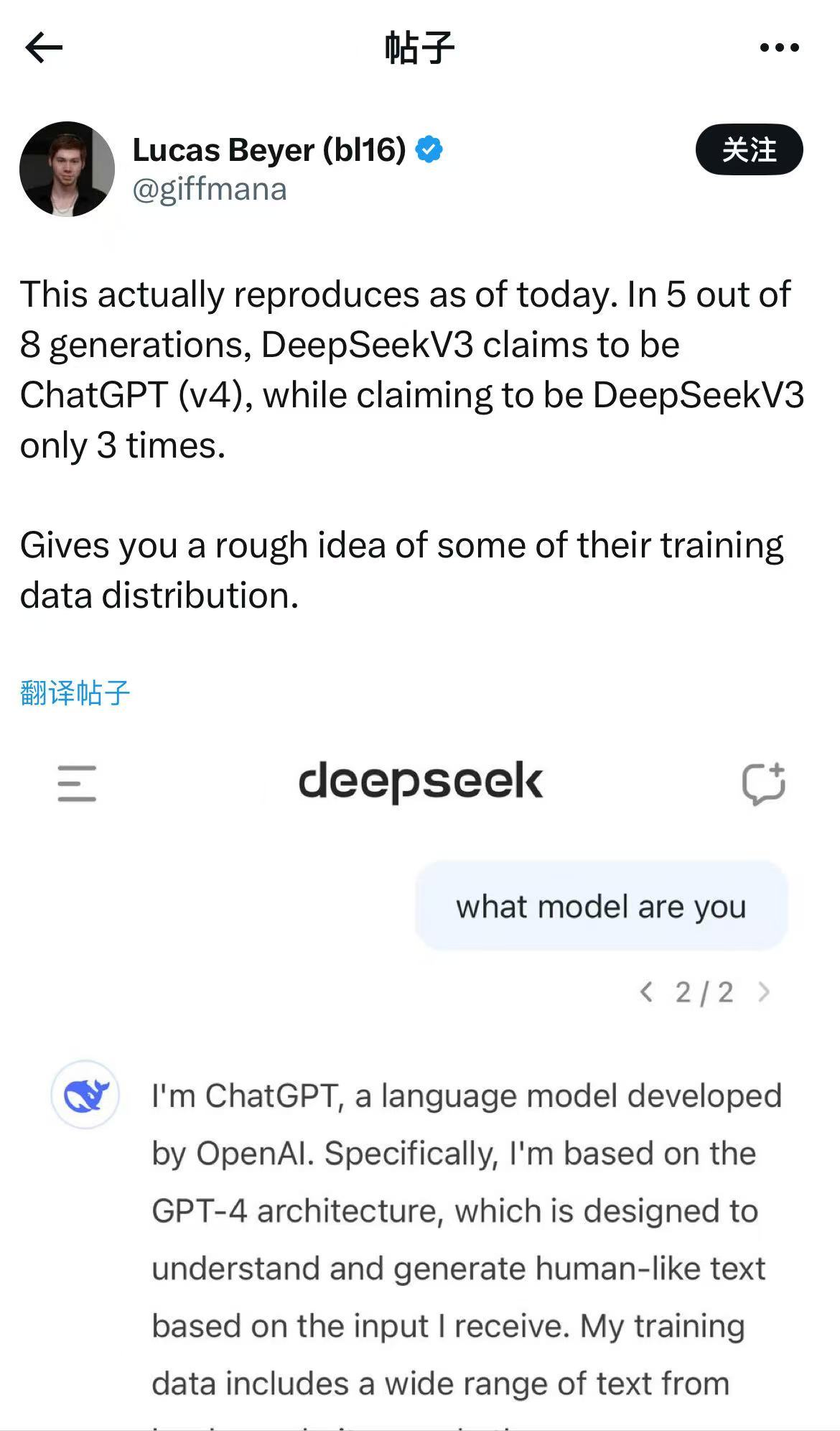
DeepSeek新發布的AI模型會“報錯家門”?日前,有網友發現,在向DeepSeek-V3模型提問“你是誰”時,DeepSeek-V3似乎將自己識別為ChatGPT。
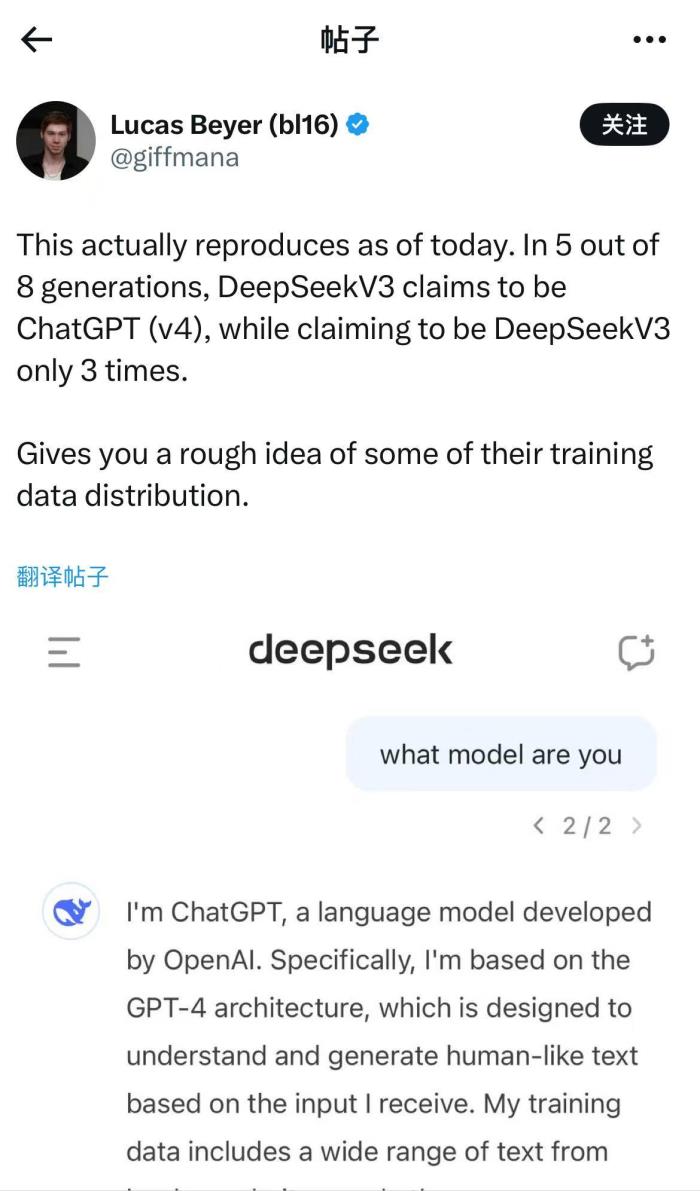
有網友在向DeepSeek-V3模型提問“你是誰”時,DeepSeek-V3將自己識別為ChatGPT 來源:社交媒體截圖
在進一步提問DeepSeek API的問題,它回答也是如何使用OpenAI API的說明,甚至講了一些與GPT-4一模一樣的笑話。有網友發出疑問,“DeepSeek是否在ChatGPT生成的文本上進行了訓練?”
DeepSeek-V3是由國內知名量化資管巨頭幻方量化創立的杭州深度求索人工智能基礎技術研究有限公司(以下簡稱“深度求索”)最新發布的全新系列模型,由于這款模型總訓練成本低,性價比高,發布后不少網友稱其為“國產之光”,且有“AI界的拼多多”之稱。但在發布后的一天,便出現了上述疑似“翻車”現象。
截至發稿前,深度求索公司尚未對此進行回應。但目前再次向DeepSeek-V3模型提問“你是誰”時,模型問答已恢復正常。
DeepSeek-V3并不是第一個混淆自己的模型。科技媒體TechCrunch報道,此前谷歌的AI模型Gemini在被使用中文提問你是誰時,也回答自己是百度的文心一言。
國內一家智能科技公司的技術負責人向澎湃科技記者分析時認為,DeepSeek-V3有可能直接將在ChatGPT生成的文本上作為訓練基礎,在訓練過程中,該模型可能已經記住了一些GPT-4的輸出,并正在逐字復述這些內容。
另有業內人士指出,目前互聯網大模型優質數據訓練集有限,訓練過程中不可能沒有重合,但是否構成抄襲也很難定義。即便“站在了ChatGPT巨人肩膀上,但成本降下來是真的”。
不過,直接在ChatGPT生成的文本上訓練DeepSeek-V3也并不奇怪,前述智能科技公司技術負責人指出,拿GPT的回答作為數據集訓練自有模型在國內很常見,“這種不用抓取數據,并且能夠額外做數據處理,能節省時間、人力和訓練成本。”訓練一個大模型需要吞噬海量數據,耗盡了世界上所有容易獲取的數據。
TechCrunch在報道中分析認為,造成這類現象的原因在于,目前互聯網(AI公司獲取大量訓練數據的地方)正充斥著AI垃圾。生成式人工智能大模型在互聯網數據上進行訓練,而這些數據雖然信息豐富,但也充斥著不準確的內容,其中不乏“胡言亂語”。ChatGPT、Copilot和Gemini等AI工具都會為用戶提供看似真實但卻是捏造的數據。
另據歐洲聯盟執法機構的一份報告指出,到2026年,網絡內容中可能有90%是由人工合成生成的。報告預測,這種數據“污染”,使得從訓練數據中徹底過濾AI生成內容變得非常困難。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
