

 新火種
2023-10-19
新火種
2023-10-19 


GPT-4肆虐「誰是臥底」桌游!交談逼真,類人屬性仍有發(fā)展空間
來源:新智元

圖片來源:由無界 AI生成
最近,韓國(guó)一團(tuán)隊(duì)為了測(cè)試GPT-3.5和GPT-4的類人屬性,竟然讓它們玩兒這款游戲!生成式AI研究再整新活!
韓國(guó)團(tuán)隊(duì)嘗試讓GPT玩兒游戲,還是個(gè)黑幫題材的游戲——「Spyfall」。
不熟悉這個(gè)游戲的朋友先來了解一下,下圖就是「Spyfall」的畫風(fēng)。

實(shí)際上這是個(gè)桌游,屬于老少咸宜,很適合朋友聚會(huì)的那種熱場(chǎng)游戲。
游戲的主要進(jìn)行方式就是「說話」。
玩家中會(huì)有一位扮演「間諜」,所有玩家抽取一張牌,其中有一張間諜牌,剩余玩家抽到的都是相同的地點(diǎn)牌。
間諜的目標(biāo),就是通過交談?wù)页鍪O峦婕宜诘牡攸c(diǎn),而其余玩家就是要判斷誰是間諜。
游戲總共進(jìn)行8分鐘,玩家之間可以相互提問。8分鐘一到,所有玩家要一同投票。
是不是很像平時(shí)我們聚會(huì)玩兒的誰是臥底?唯一不同在于,誰是臥底的詞匯可能來自各個(gè)領(lǐng)域,而這款游戲只有地點(diǎn)類名詞,比如球場(chǎng)、劇院、教室等等。
好了,游戲規(guī)則搞明白,下一步就是要讓GPT來玩玩看了。
研究結(jié)果
研究團(tuán)隊(duì)表示, 在實(shí)驗(yàn)過程中,將會(huì)特別關(guān)注GPT在角色扮演中的表現(xiàn),本研究旨在展示GPT在具體游戲場(chǎng)景中的理解、決策和互動(dòng)的能力以及潛力。
從結(jié)果粗看,GPT-4與GPT-3.5-turbo的對(duì)比分析表明,GPT-4增強(qiáng)了對(duì)游戲環(huán)境的適應(yīng)性,在提出相關(guān)問題和形成類似人類的反應(yīng)方面有顯著改進(jìn)。
然而,也并非全是優(yōu)點(diǎn)。比如說,GPT-4在虛張聲勢(shì)(Bluff)和預(yù)測(cè)對(duì)手行動(dòng)方面存在一定的局限性,尤其是沒扮演間諜的時(shí)候。
研究結(jié)果表明,雖然GPT-4與之前的版本相比取得了不錯(cuò)的進(jìn)步,但還是有進(jìn)一步發(fā)展的潛力,特別是在向AI灌輸更多「類人」屬性的方面。
不過,實(shí)驗(yàn)還是成功表明,生成式AI在模擬類人互動(dòng)方面大有可為。從GPT-2到GPT-4,模型的決策能力、可解釋性和解決問題的能力都有了長(zhǎng)足的進(jìn)步。
未來的努力方向,就是上面提到的「類人」屬性,使GPT更具通用性和廣泛性。
研究方法
首先,我們知道,GPT模型最大的優(yōu)勢(shì)就在于,用戶可以通過自然語(yǔ)言和其進(jìn)行直觀的交互,無論用戶本人是否對(duì)技術(shù)的內(nèi)核熟悉。
當(dāng)然,幾乎所有的模型交互都是通過自然語(yǔ)言進(jìn)行的,用戶可以用自己最熟悉的方式表達(dá)自己的想法和意圖,并得到模型的回應(yīng)。
此外,LLM擁有廣闊的知識(shí)譜系,GPT-4的數(shù)據(jù)庫(kù)也能使模型提供關(guān)于眾多主題的深入的知識(shí)。
同時(shí),GPT和其它LLM所不同之處在于其可擴(kuò)展性非常強(qiáng),用戶可以在很多領(lǐng)域應(yīng)用GPT,就比如說今天介紹的實(shí)驗(yàn)。
在這次實(shí)驗(yàn)中,研究人員一共安排了5名玩家,包括GPT。
研究人員總共進(jìn)行了2項(xiàng)實(shí)驗(yàn)。
實(shí)驗(yàn)一:測(cè)試GPT-4和GPT-3.5-turbo的性能差異。實(shí)驗(yàn)二:僅使用GPT-4進(jìn)行游戲。研究人員一共進(jìn)行了8局游戲,記錄了每場(chǎng)游戲的日志,并對(duì)結(jié)果進(jìn)行了討論。
當(dāng)然,對(duì)于給出生成式AI的潛力一個(gè)確切的結(jié)論來說,實(shí)驗(yàn)次數(shù)并不足夠。但是按照這個(gè)思路進(jìn)行更多組重復(fù)實(shí)驗(yàn)以及更加廣泛的測(cè)試,就可以提供更多實(shí)質(zhì)性的證據(jù)。
我們先來看實(shí)驗(yàn)一。
為了評(píng)估GPT-4與GPT-3.5-turbo相比的差異,尤其是在格式方面出現(xiàn)錯(cuò)誤的機(jī)率、對(duì)游戲規(guī)則和進(jìn)程等游戲背景相關(guān)內(nèi)容的理解,以及類人反應(yīng)方面的不同。
研究人員從第一輪交談的第一個(gè)問題開始進(jìn)行實(shí)驗(yàn)。
有了這一最清晰、變數(shù)最小的游戲部分,他們就可以精確地分析每個(gè)模型的能力,最大限度地減少外部因素的影響。
首先,研究人員比較了GPT-3.5-turbo和GPT-4對(duì)規(guī)則腳本中,所描述的30個(gè)地點(diǎn)中每個(gè)地點(diǎn)的30個(gè)首輪問題的回答。
向兩種模型提問的行動(dòng)請(qǐng)求腳本是相同的,只是更改了地點(diǎn)的關(guān)鍵字而已。
規(guī)則與基本策略都和上述腳本相同,如下圖所示,實(shí)驗(yàn)人員通過將三個(gè)腳本合并為一個(gè)請(qǐng)求,來獲得模型的響應(yīng)。
為了進(jìn)行更準(zhǔn)確的比較,所有請(qǐng)求都固定為玩家 1,并假定玩家 1 不是間諜。
提交給每個(gè)模型的腳本如下:

你是玩家1,你不是間諜。本輪的地點(diǎn)是______。
現(xiàn)在輪到你來向其他玩家提問。從玩家1到5中(不可以選擇自己)選擇一位玩家,并寫下你的問題。并按以下格式進(jìn)行提交:n(玩家序號(hào))_player,問題內(nèi)容
對(duì)于游戲本身來說,一個(gè)高質(zhì)量的提問應(yīng)該包括以下幾個(gè)部分:表明身份,即自己不是間諜。表明自己知道地點(diǎn)是什么,以此來證明自己不是間諜。最后保證間諜不會(huì)知道地點(diǎn)究竟在哪里。
同時(shí),模型的輸出結(jié)果必須符合上述腳本中的格式。研究人員表示,如果模型不遵守格式,那就要花費(fèi)大量精力來進(jìn)行糾正。
我們來看如下輸出:

最上面就是一個(gè)不錯(cuò)的問題:你去這個(gè)地方需要買票嗎?
下面的例子則是一些不太相關(guān)的問題,但是符合格式。
比如:?jiǎn)栴}中直接提到地點(diǎn)(就好像玩兒誰是臥底的時(shí)候直接把底牌交了)。
再比如:和上述游戲計(jì)劃無關(guān)的問題。
(例:正確地點(diǎn)是劇院,GPT問其他玩家最喜歡的戰(zhàn)爭(zhēng)片是什么。)
當(dāng)然,還有完全失敗的情況:

比如經(jīng)典話術(shù):作為一個(gè)AI語(yǔ)言模型,我不能....
甚至還有從單純重復(fù)問題的情況出現(xiàn)。
根據(jù)上述結(jié)果(完整結(jié)果見論文),研究人員得出結(jié)論,和GPT-3.5-turbo相比,GPT-4更適合下一步的實(shí)驗(yàn)。
檢查數(shù)據(jù)時(shí)研究人員發(fā)現(xiàn),GPT-3.5-turbo經(jīng)常會(huì)生成一些脫離游戲背景的問題。比如上面提到的直接交出地點(diǎn),使間諜能立即確定位置,對(duì)非間諜不利。
還有上面說的詢問玩家的個(gè)人喜好,而非與游戲相關(guān)的話題,擾亂了游戲流程。這都是GPT-3.5干的。
此外,不按要求的格式回答,妨礙游戲進(jìn)行,也是GPT-3.5的拿手好戲。
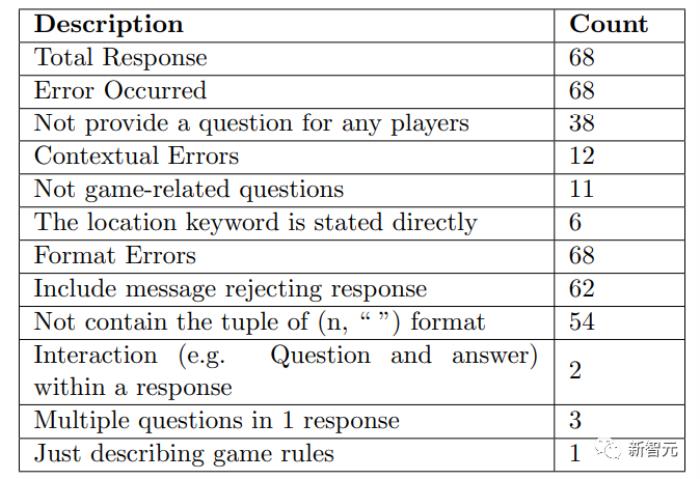
上表即為GPT-3.5不合要求的所有情況統(tǒng)計(jì)。有意思的是,總共68個(gè)回答,出錯(cuò)68次,沒一個(gè)完美的輸出。
GPT-3.5 pass,我們接下來再來看GPT-4進(jìn)行下一個(gè)實(shí)驗(yàn)。
研究人員按照概述的規(guī)則進(jìn)行了8次游戲,并用GPT-4采集了每次游戲的日志。
游戲中的所有反應(yīng)都是由GPT-4生成的,而游戲的自動(dòng)化代碼則是由Python編寫的。
根據(jù)本文中的規(guī)則和腳本,感興趣的朋友們可以輕松重現(xiàn)該實(shí)驗(yàn)。
研究人員從地點(diǎn)列表中的A開始依次選擇地點(diǎn),總共進(jìn)行了8場(chǎng)游戲。每局游戲都從玩家1開始,GPT-4會(huì)獨(dú)立響應(yīng)每個(gè)請(qǐng)求,不會(huì)從一局游戲保留到下一局游戲。
GPT-4僅根據(jù)提供的腳本來做出決定,這意味著開始玩家的身份不會(huì)影響游戲結(jié)果。
經(jīng)過8輪游戲,研究人員得出的結(jié)論是,GPT-4在每個(gè)游戲和回合中的對(duì)話都是流暢和有機(jī)的,一連串的問答讓人感覺真實(shí)可信、像人一樣。
同時(shí),在分析所提出的問題及其答案時(shí),團(tuán)隊(duì)發(fā)現(xiàn)了一個(gè)明顯的觀察結(jié)果。
那就是,在沒有經(jīng)過任何專門訓(xùn)練或微調(diào)的情況下,GPT-4模型就能根據(jù)游戲流程,熟練地提出各種相關(guān)問題。
為了證明GPT-4在游戲中提出的問題和答案的多樣性,研究人員將問題和相應(yīng)的答案分成了幾組
不過,雖說這些問題和答案沒有經(jīng)過預(yù)先訓(xùn)練,但每個(gè)回答都有自己的對(duì)象和獨(dú)特的細(xì)微差別。
盡管沒有經(jīng)過任何特定的訓(xùn)練,GPT-4還是能根據(jù)游戲的流程巧妙地提出相關(guān)問題,似乎能分辨出哪些問題適合游戲環(huán)境,哪些問題可能不合適或多余。
比如下面這個(gè)例子:

問:我們?cè)谶@里能吃到什么樣的點(diǎn)心?
答:小點(diǎn)心和飲料,包括軟飲料和酒精飲料,通常是小份供應(yīng)。
問:這里通常提供什么類型的食品和點(diǎn)心?
答:在這個(gè)地點(diǎn),您可以找到各種食品,如漢堡、熱狗、棉花糖、爆米花、和冰激凌,以及蘇打水和水等飲料,讓每個(gè)人都能精神飽滿。
問:我們可以在這里找到哪些食物?
答:這里有各種食品可供選擇,包括油炸食品、棉花糖和爆米花。
問:您通常在這里吃什么類型的食物?
答:根據(jù)情況,我們主要吃腌制食品和不易腐壞的食品。
在論文的結(jié)尾,研究人員表示,盡管存在某些局限性,但這些模型不斷增長(zhǎng)的潛力還是很有希望促進(jìn)創(chuàng)新、激發(fā)實(shí)際應(yīng)用的。
GPT系列模型的進(jìn)步非常迅速,尤其是在決策、可解釋性和解決問題的能力方面。
最初,GPT-2的目標(biāo)僅僅是處理基礎(chǔ)層面的自然語(yǔ)言。后來,該模型發(fā)展成為具有多種任務(wù)的交互模型。
而現(xiàn)在,GPT-4在某些領(lǐng)域展示出了超越人類表現(xiàn)的邏輯推理能力。接下來,研究人員就可以深入到一個(gè)新的融合領(lǐng)域了。
GPT出色的自然語(yǔ)言處理能力可極大地幫助用戶理解模型如何運(yùn)行并解釋其結(jié)果。
這種可訪問性擴(kuò)大了潛在用戶群,向來自不同背景的用戶張開了懷抱,增強(qiáng)了模型在不同領(lǐng)域的創(chuàng)造性,以及可擴(kuò)展性。
最后,GPT-4的類人特質(zhì)與其他模型相比,在模仿類人反應(yīng)的能力方面毫無疑問更勝一籌。
對(duì)于某些任務(wù)或活動(dòng)(比如說教育、體育、音樂和藝術(shù)等娛樂領(lǐng)域)來說,人性化地完成任務(wù)可能比返回最佳結(jié)果更重要。
參考資料:https://www.reddit.com/r/MachineLearning/comments/16qztf4/r_generative_ai_in_mafialike_game_simulation/
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
