

 新火種
2023-09-07
新火種
2023-09-07 

如何解決90%的自然語言處理問題:分步指南奉上
自然語言處理(NLP)與計算機視覺(CV)一樣,是目前人工智能領(lǐng)域里最為重要的兩個方向。如何讓機器學(xué)習(xí)方法從文字中理解人類語言內(nèi)含的思想?本文中,來自 Insight AI 的 Emmanuel Ameisen 將為我們簡述絕大多數(shù)任務(wù)上我們需要遵循的思路。

文本數(shù)據(jù)的 5W 和 1H!
文本數(shù)據(jù)無處不在
無論是成立的公司,還是致力于推出新服務(wù),你都可以利用文本數(shù)據(jù)來驗證、改進和擴展產(chǎn)品的功能。從文本數(shù)據(jù)中提取信息并從中學(xué)習(xí)的科學(xué)是自然語言處理(NLP)的一個活躍的研究課題。
NLP 覆蓋領(lǐng)域很廣,每天都會有新的令人興奮的結(jié)果。但經(jīng)過與數(shù)百家公司合作,Insight 團隊發(fā)現(xiàn)其中有幾個重要應(yīng)用出現(xiàn)得尤其頻繁:
識別不同的用戶/客戶群(例如預(yù)測客戶流失、顧客終身價值、產(chǎn)品偏好)準(zhǔn)確檢測和提取不同類別的反饋(正面和負(fù)面的評論/意見,提到的特定屬性,如衣服尺寸/合身度等)根據(jù)意圖對文本進行分類(例如尋求一般幫助,緊急問題)
盡管網(wǎng)上有很多 NLP 論文和教程,但我們很難找到從頭開始高效學(xué)習(xí)這些問題的指南和技巧。
本文給你的幫助
結(jié)合每年帶領(lǐng)數(shù)百個項目組的經(jīng)驗,以及全美國最頂尖團隊的建議,我們完成了這篇文章,它將解釋如何利用機器學(xué)習(xí)方案來解決上述 NLP 問題。我們將從最簡單的方法開始,然后介紹更細(xì)致的方案,如特征工程、單詞向量和深度學(xué)習(xí)。
閱讀完本文后,您將會知道如何:
收集、準(zhǔn)備和檢驗數(shù)據(jù)建立簡單的模型,必要時轉(zhuǎn)化為深度學(xué)習(xí)解釋和理解模型,確保捕獲的是信息而非噪聲
這篇文章我們將給你提供一步一步的指導(dǎo);也可以作為一個提供有效標(biāo)準(zhǔn)方法的高水平概述。
這篇文章附有一個交互式 notebook,演示和應(yīng)用了所有技術(shù)。
第 1 步:收集數(shù)據(jù)
數(shù)據(jù)源示例
每個機器學(xué)習(xí)問題都從數(shù)據(jù)開始,例如電子郵件、帖子或推文(微博)。文本信息的常見來源包括:
產(chǎn)品評論(來自亞馬遜,Yelp 和各種應(yīng)用商店)用戶發(fā)布的內(nèi)容(推文,F(xiàn)acebook 上的帖子,StackOverflow 上的問題)故障排除(客戶請求,支持票據(jù),聊天記錄)
「社交媒體中出現(xiàn)的災(zāi)難」數(shù)據(jù)集
本文我們將使用由 CrowdFlower 提供的一個名為「社交媒體中出現(xiàn)的災(zāi)難」的數(shù)據(jù)集,其中:
編者查看了超過 1 萬條推文,其中包括「著火」、「隔離」和「混亂」等各種搜索,然后看推文是否是指災(zāi)難事件(排除掉用這些單詞來講笑話或評論電影等沒有發(fā)生災(zāi)難的情況)。
我們的任務(wù)是檢測哪些推文關(guān)于災(zāi)難性事件,排除像電影這種不相關(guān)的話題。為什么?一個可能的應(yīng)用是僅在發(fā)生緊急事件時(而不是在討論最近 Adam Sandler 的電影時)通知執(zhí)法官員。
這篇文章的其它地方,我們將把關(guān)于災(zāi)難的推文稱為「災(zāi)難」,把其它的推文稱為「不相關(guān)事件」。
標(biāo)簽
我們已經(jīng)標(biāo)記了數(shù)據(jù),因此我們知道推文所屬類別。正如 Richard Socher 在下文中概述的那樣,找到并標(biāo)記足夠多的數(shù)據(jù)來訓(xùn)練模型通常更快、更簡單、更便宜,而非嘗試優(yōu)化復(fù)雜的無監(jiān)督方法。
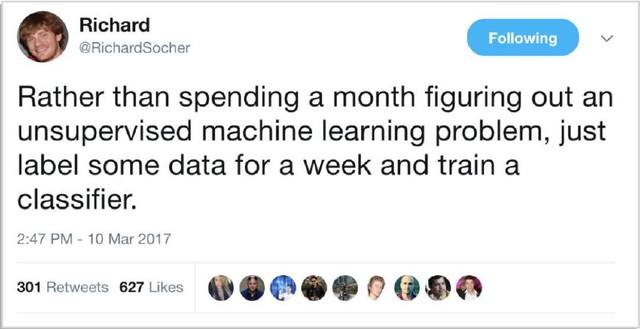
Richard Socher 的小建議
第 2 步:清理數(shù)據(jù)
我們遵循的首要規(guī)則是:「你的模型受限于你的數(shù)據(jù)」。
數(shù)據(jù)科學(xué)家的重要技能之一就是知道下一步的工作對象是模型還是數(shù)據(jù)。一個好的方法是先查看數(shù)據(jù)再清理數(shù)據(jù)。一個干凈的數(shù)據(jù)集可以使模型學(xué)習(xí)有意義的特征,而不是過度擬合無關(guān)的噪聲。
下面是一個清理數(shù)據(jù)的清單:(更多細(xì)節(jié)見代碼 code):
1. 刪除所有不相關(guān)的字符,如任何非字母數(shù)字字符
2. 把文字分成單獨的單詞來標(biāo)記解析
3. 刪除不相關(guān)的詞,例如推文中的「@」或網(wǎng)址
4. 將所有字符轉(zhuǎn)換為小寫字母,使「hello」,「Hello」和「HELLO」等單詞統(tǒng)一
5. 考慮將拼寫錯誤和重復(fù)拼寫的單詞歸為一類(例如「cool」/「kewl」/「cooool」)
6. 考慮詞性還原(將「am」「are」「is」等詞語統(tǒng)一為常見形式「be」)
按這些步驟操作并檢查錯誤后,就可以使用干凈的標(biāo)簽化的數(shù)據(jù)來訓(xùn)練模型啦!
第 3 步:尋找好的數(shù)據(jù)表示
機器學(xué)習(xí)模型的輸入是數(shù)值。如圖像處理的模型中,用矩陣來表示各個顏色通道中每個像素的強度。
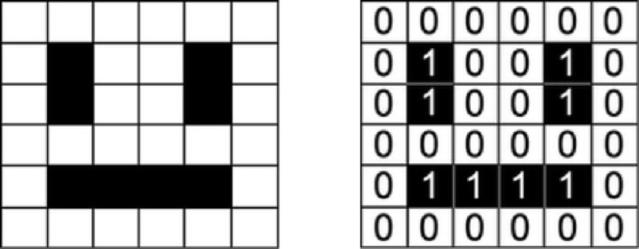
一個笑臉可以表示為一個數(shù)字矩陣。
如果我們的數(shù)據(jù)集是一系列的句子,為了使算法可以從數(shù)據(jù)中提取特征,我們需要表示為可以被算法識別的形式,如表示為一系列數(shù)字
One-hot encoding(詞袋模型)
表示文本的一種常見方法是將每個字符單獨編碼為一個數(shù)字(例如 ASCII)。如果我們直接把這種簡單的形式用于分類器,那只能基于我們的數(shù)據(jù)從頭開始學(xué)習(xí)單詞的結(jié)構(gòu),這對于大多數(shù)數(shù)據(jù)集是不可實現(xiàn)的。因此,我們需要一個更高級的方法。
例如,我們可以為數(shù)據(jù)集中的所有單詞建立一個詞匯表,每個單詞對應(yīng)一個不同的數(shù)字(索引)。那句子就可以表示成長度為詞匯表中不同單詞的一個列表。在列表的每個索引處,標(biāo)記該單詞在句子中出現(xiàn)的次數(shù)。這就是詞袋模型(Bag of Words),這種表示完全忽略了句子中單詞的順序。如下所示。
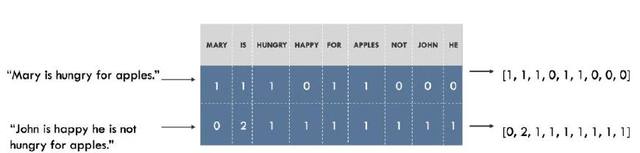
將句子表示為詞袋。左邊為句子,右邊為對應(yīng)的表示,向量中的每個數(shù)字(索引)代表一個特定的單詞。
可視化詞嵌入
在「社交媒體中出現(xiàn)的災(zāi)難」一例中,大約有 2 萬字的詞匯,這代表每個句子都將被表示為長度為 2 萬的向量。向量中有很多 0,因為每個句子只包含詞匯表中非常小的一個子集。
為了了解詞嵌入是否捕獲到了與問題相關(guān)的信息(如推文是否說的是災(zāi)難),有一個很好的辦法,就是將它們可視化并看這些類的分離程度。由于詞匯表很大,在 20,000 個維度上可視化數(shù)據(jù)是不可能的,因此需要主成分分析(PCA)這樣的方法將數(shù)據(jù)分到兩個維度。如下圖所示。
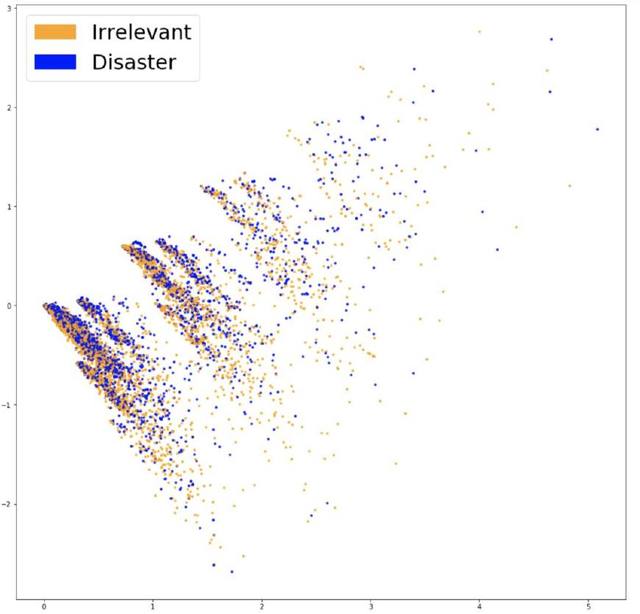
將嵌入的詞袋可視化。
看起來很難分為兩類,也不好去降低維度,這是嵌入的一個特點。為了了解詞袋模型特征是否有用,我們可以基于它們訓(xùn)練一個分類器。
第 4 步:分類器
遇到一個問題時,通常從尋找解決問題的工具入手。當(dāng)我們要對數(shù)據(jù)進行分類時,出于通用性和可解釋性的考慮,通常使用 Logistic 回歸(Logistic Regression)。訓(xùn)練非常簡單,結(jié)果也可解釋,因為易于從模型提取出最重要的參數(shù)。
我們將數(shù)據(jù)分成一個用于擬合模型的訓(xùn)練集和一個用于分析對不可見數(shù)據(jù)擬合程度的測試集。訓(xùn)練結(jié)束后,準(zhǔn)確率為 75.4%。還看得過去!最頻繁的一類(「不相關(guān)事件」)僅為 57%。但即使只有 75% 的準(zhǔn)確率也足以滿足我們的需要了,一定要在理解的基礎(chǔ)上建模。
第 5 步:檢驗
混淆矩陣(Confusion Matrix)
首先要知道我們模型的錯誤類型,以及最不期望的是哪種錯誤。在我們的例子中,誤報指將不相關(guān)的推文分類為災(zāi)難,漏報指將關(guān)于災(zāi)難的推文歸為不相關(guān)事件。如果要優(yōu)先處理每個可能的事件,那我們想降低漏報的情況。如果我們優(yōu)先考慮資源有限的問題,那我們會優(yōu)先降低誤報的情況,從而減少誤報的提醒。我們可以用混淆矩陣來可視化這些信息,混淆矩陣將我們模型預(yù)測的結(jié)果與真實情況進行比較。理想情況下(我們的預(yù)測結(jié)果與真實情況完全相符),矩陣為從左上到右下的一個對角矩陣。
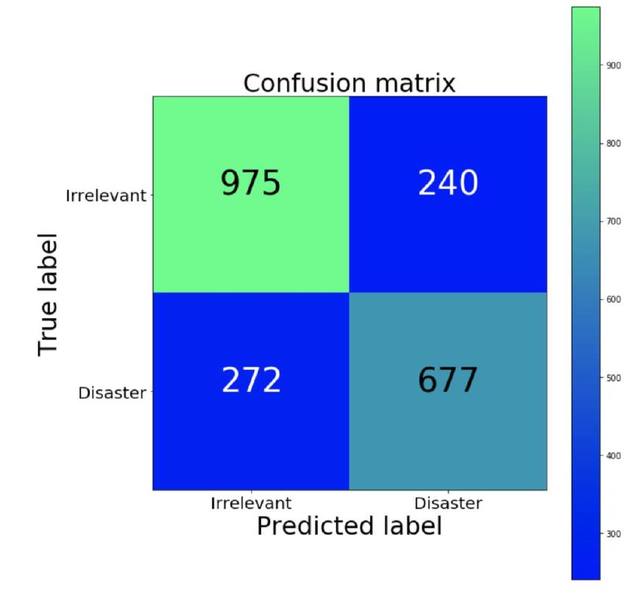
混淆矩陣(綠色比例大,藍色比例小)
我們的分類器的漏報情況(相對)高于誤報情況。也就是說,這個模型很可能錯誤地將災(zāi)難歸為不相關(guān)事件。如果誤報情況下執(zhí)法的成本很高,那我們更傾向于使用這個分類器。
解釋模型
為了驗證模型并解釋模型的預(yù)測,我們需要看哪些單詞在預(yù)測中起主要作用。如果數(shù)據(jù)有偏差,分類器會對樣本數(shù)據(jù)作出準(zhǔn)確的預(yù)測,但在實際應(yīng)用時模型預(yù)測的效果并不理想。下圖中我們給出了關(guān)于災(zāi)難和不相關(guān)事件的重要詞匯。我們可以提取并比較模型中的預(yù)測系數(shù),所以用詞袋模型和 Logistic 回歸來尋找重要詞匯非常簡單。
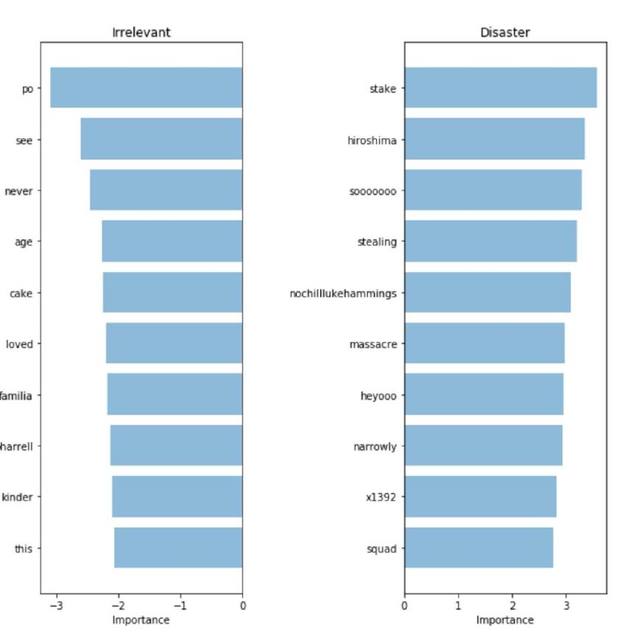
詞袋:重要詞匯
我們的分類器正確地找到了一些模式(廣島,大屠殺),但顯然這是無意義數(shù)據(jù)的過度擬合(heyoo, x1392)。現(xiàn)在我們的詞袋模型正在處理一個龐大的詞匯表,所有詞匯對它來說都是一樣的。但一些詞匯出現(xiàn)地非常頻繁,而且只會對我們的預(yù)測加入噪聲。接下來,我們試著用一個方法來表示詞匯出現(xiàn)的頻率,看我們能否從數(shù)據(jù)中獲得更多的信號。
第 6 步:統(tǒng)計詞匯
TF-IDF
為了使模型更關(guān)注有意義的單詞,我們可以使用 TF-IDF(詞頻-逆文檔頻率)對我們的詞袋模型進行評估。TF-IDF 通過對數(shù)據(jù)集中詞匯出現(xiàn)的頻率來加權(quán),并減小高頻但只是增加噪音的單詞的權(quán)重。這是我們新嵌入的 PCA 預(yù)測。
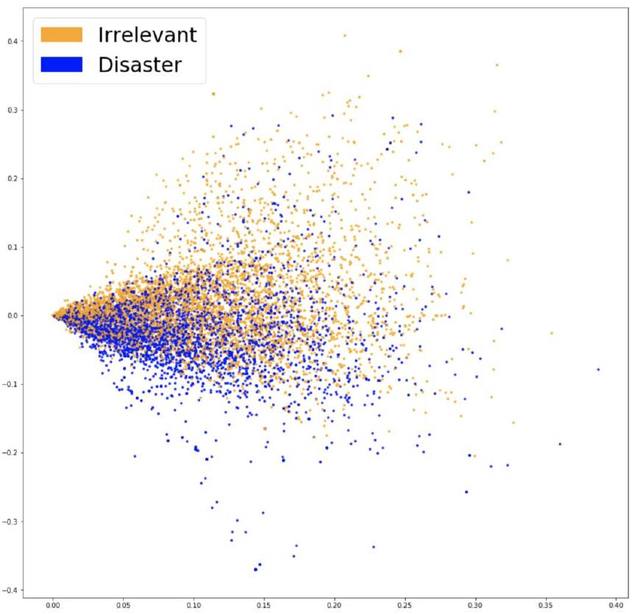
將 TF-IDF 嵌入可視化
由上圖我們看到,兩種顏色的數(shù)據(jù)差別更加明顯。這使分類器分組更加容易。讓我們來看一下這樣結(jié)果是否會更好。訓(xùn)練新嵌入的 Logistic 回歸,我們得到了 76.2%的準(zhǔn)確率。
只是稍稍地進行了改進。那現(xiàn)在我們的模型可以選擇更重要的單詞了嗎?如果模型預(yù)測時有效地繞過了「陷阱」,得到了更好的結(jié)果,那就可以說,這個模型得到了優(yōu)化。
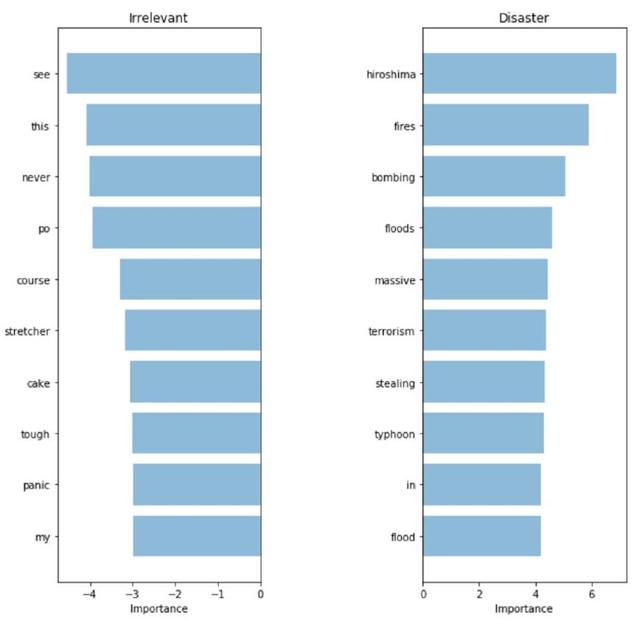
TF-IDF:重要詞匯
挑出來的單詞似乎更加相關(guān)了!盡管我們測試集的指標(biāo)稍有增加,但模型使用的詞匯更加關(guān)鍵了,因此我們說「整個系統(tǒng)運行時與客戶的交互更加舒適有效」。
第 7 步:利用語義
Word2Vec
我們最新的模型可以挑出高信號的單詞。但很可能我們運作模型時會遇到訓(xùn)練集中沒有單詞。因此,即使在訓(xùn)練中遇到非常相似的單詞,之前的模型也不會準(zhǔn)確地對這些推文進行分類。
為了解決這個問題,我們需要捕獲單詞的含義,也就是說,需要理解「good」和「positive」更接近而不是「apricot」或「continent」。用來捕獲單詞含義的工具叫 Word2Vec。
使用預(yù)訓(xùn)練的單詞
Word2Vec 是尋找單詞連續(xù) embedding 的技術(shù)。通過閱讀大量的文本學(xué)習(xí),并記憶哪些單詞傾向于相似的語境。訓(xùn)練足夠多的數(shù)據(jù)后,詞匯表中的每個單詞會生成一個 300 維的向量,由意思相近的單詞構(gòu)成。
論文《Efficient Estimation of Word Representations in Vector Space》的作者開源了一個模型,對一個足夠大的可用的語料庫進行預(yù)訓(xùn)練,將其中的一些語義納入我們的模型中。預(yù)訓(xùn)練的向量可以在這篇文章相關(guān)的資源庫中找到。
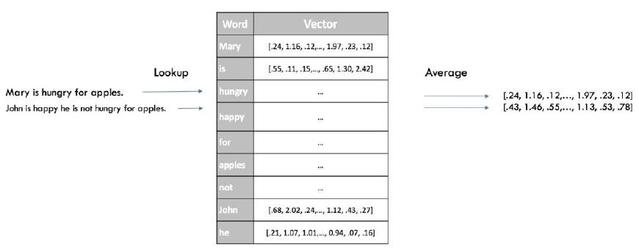
句子的表示
快速得到分類器的 sentence embedding 的一個方法是平均對句子中的所有單詞的 Word2Vec 評估。這和之前詞袋模型是一個意思,但這次我們保留一些語言信息,僅忽略句子的語法。
以下是之前技術(shù)的新嵌入的可視化:
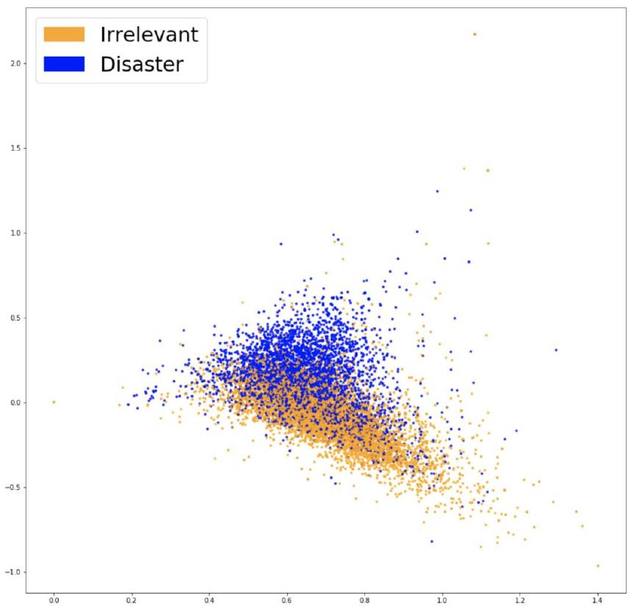
可視化 Word2Vec 嵌入
這兩種顏色的數(shù)據(jù)更明顯地分離了,我們新的嵌入可以使分類器找到兩類之前的分離。經(jīng)過第三次訓(xùn)練同一個模型后(Logistic 回歸),我們得到了 77.7%的準(zhǔn)確率,這是目前最好的結(jié)果!可以檢驗我們的模型了。
復(fù)雜性/可解釋性的權(quán)衡
我們的 embedding 沒有向之前的模型那樣每個單詞表示為一維的向量,所以很驗證看出哪些單詞和我們的向量最相關(guān),。雖然我們?nèi)钥梢允褂?Logistic 回歸的系數(shù),但它們和我們 embedding 的 300 個維度有關(guān),而不再是單詞的索引。
它的準(zhǔn)確率這么低,拋掉所有的可解釋性似乎是一個粗糙的權(quán)衡。但對于更復(fù)雜的模型來說,我們可以利用 LIME 之類的黑盒解釋器(black box explainers)來深入了解分類器的工作原理。
LIME
可以通過開源軟件包在 Github 上找到 LIME
黑盒解釋器允許用戶通過擾亂輸入并觀察預(yù)測的變化來解釋一個特定例子的任何分類器的決定。
讓我們看一下數(shù)據(jù)集中幾個句子的解釋。

挑選正確的災(zāi)難詞匯并歸類為「相關(guān)」。
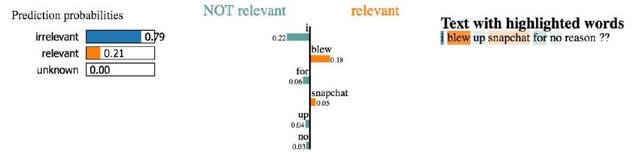
這里,這個詞對分類器的造成的影響似乎不太明顯。
但是,我們沒有時間去探索數(shù)據(jù)集中的數(shù)千個示例。我們要做的是在測試?yán)拥拇順颖旧线\行 LIME,看哪些詞匯做的貢獻大。使用這種方式,我們可以像之前的模型一樣對重要單詞進行評估,并驗證模型的預(yù)測結(jié)果。
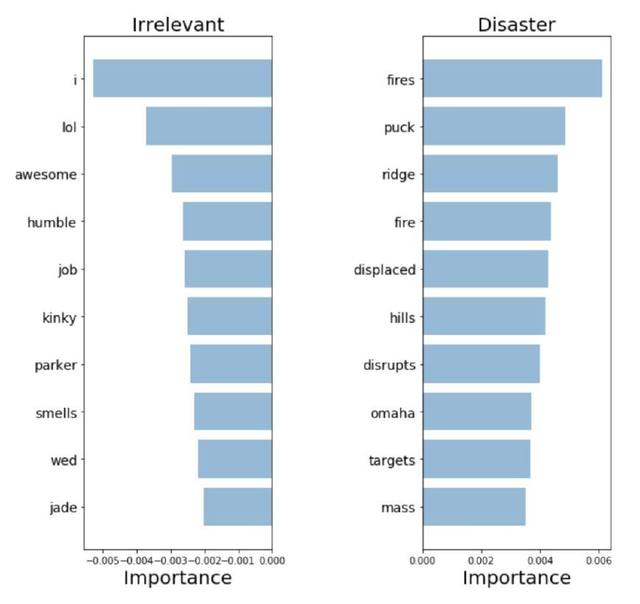
Word2Vec:重要單詞
模型提取的高度相關(guān)的詞意味它可以做出更加可解釋的決定。這些看起來像是之前模型中最相關(guān)的詞匯,因此我們更愿意將其加入到我們的模型中。
第 8 步:使用端到端(end-to-end)方法
我們已經(jīng)介紹了生成簡潔句嵌入快速有效的方法。但是由于忽略了單詞的順序,我們跳過了句子所有的語法信息。如果這些方法提供的結(jié)果不充分,那我們可以使用更復(fù)雜的模型,輸入整個句子并預(yù)測標(biāo)簽,而不需要中間表示。一個常見的方法是使用 Word2Vec 或更類似的方法(如 GloVe 或 CoVe)將句子看作一個單詞向量的序列。這就是我們下文中要做的。
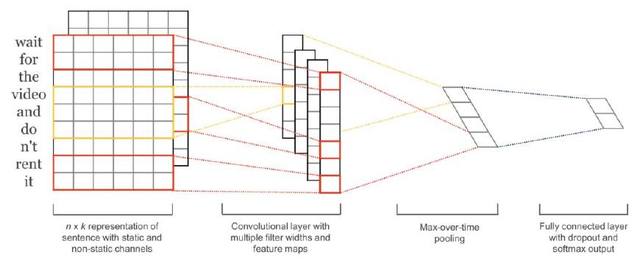
高效的端到端結(jié)構(gòu)
用于句子分類的卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練非常迅速,作為入門級深度學(xué)習(xí)體系效果非常理想。雖然卷積神經(jīng)網(wǎng)絡(luò)(CNN)主要因為在圖像處理的使用而廣為人知,但它們在處理文本相關(guān)任務(wù)時得到的結(jié)果也非常好,而且通常比大多數(shù)復(fù)雜的 NLP 方法(如 LSTMs 和 Encoder/Decoder 結(jié)構(gòu))訓(xùn)練地更快。這個模型考慮了單詞的順序,并學(xué)習(xí)了哪些單詞序列可以預(yù)測目標(biāo)類等有價值的信息,可以區(qū)別「Alex eats plants」和「Plants eat Alex」
訓(xùn)練這個模型不用比之前的模型做更多的工作,并且效果更好,準(zhǔn)確率達到了 79.5%!
與上述模型一樣,下一步我們要使用此方法來探索和解釋預(yù)測,以驗證它是否是給用戶提供的最好的模型。到現(xiàn)在,你應(yīng)該對這樣的問題輕車熟路了。
結(jié)語
下面對我們成功使用的方法進行簡要回顧:
從一個簡單快速的模型開始解釋其預(yù)測了解其錯誤類型根據(jù)以上知識來判斷下一步的工作——處理數(shù)據(jù)還是尋找更復(fù)雜的模型
這些方法只用于特定的例子——使用適當(dāng)?shù)哪P蛠砝斫夂屠枚涛谋荆ㄍ莆模@種思想適用于各種問題。希望這篇文章對你有所幫助,也歡迎大家提出意見和問題。
相關(guān)推薦


- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
