

 新火種
2025-01-10
新火種
2025-01-10 



“AI界的拼多多”DeepSeek推出新款大模型,水平如何?

開源和閉源AI的差距,進一步被這家中國公司縮小了。
近日,被稱為“AI界拼多多”的中國人工智能初創公司深度求索(DeepSeek)發布了全新大模型DeepSeek-V3(下稱V3)并同步開源。該模型在Aider多語言編程測試排行榜中,已超越Anthropic的Claude 3.5 Sonnet大模型,僅次于榜首的OpenAI o1大模型。
開源No.1,多方面追平閉源大模型
DeepSeek是知名私募巨頭幻方量化旗下的人工智能公司,根據DeepSeek公布的測試結果,其運行了多項基準測試來比較性能,V3模型已明顯優于包括Meta公司的Llama-3.1-405B和阿里云的Qwen 2.5-72B等一眾領先開源模型。在大多數基準測試中,它甚至部分超越了OpenAI的閉源模型GPT-4o。
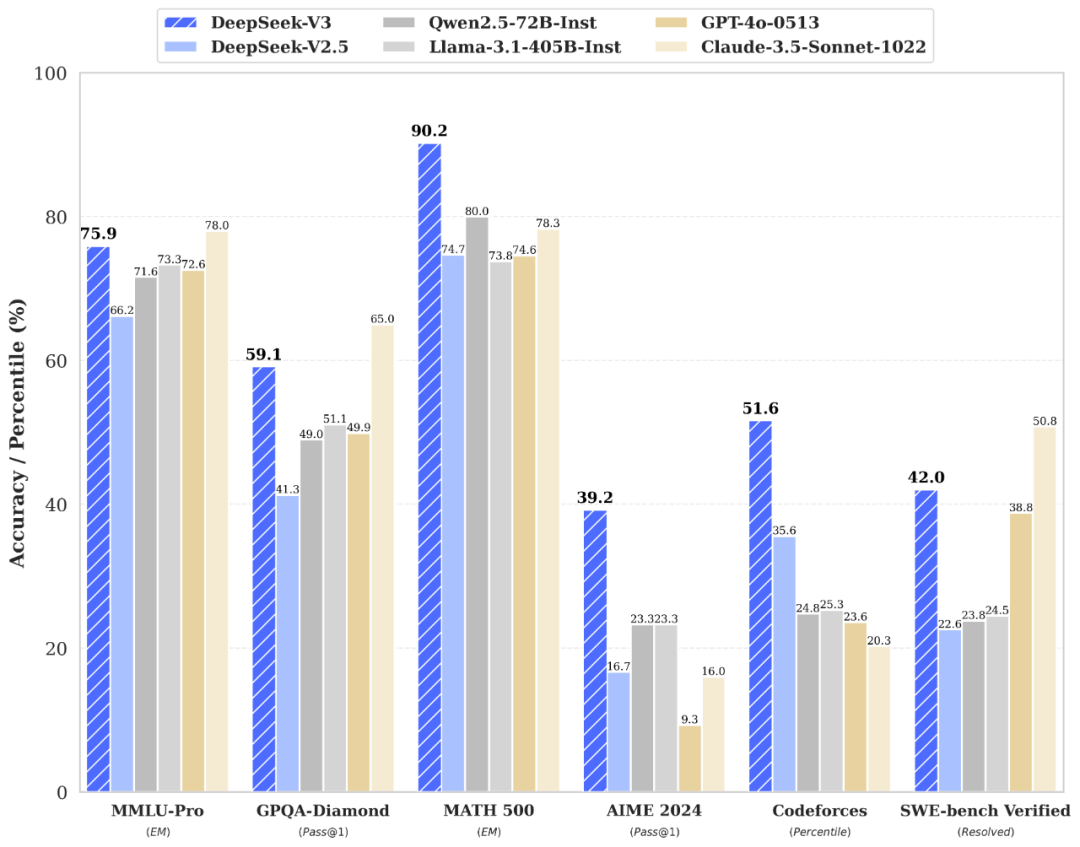
Deepseek-V3在多方面超越、追平各種開源、閉源大模型。Deepseek
首先是百科知識上,V3的知識類任務(MMLU, MMLU-Pro, GPQA, SimpleQA)水平相比前代 DeepSeek-V2.5 (下稱V2.5)顯著提升,接近當前表現最好的模型 Claude-3.5-Sonnet-1022。長文本測評方面,在DROP、FRAMES 和 LongBench v2 上,V3 平均表現超越其他模型。
此外,V3 在算法類代碼場景(Codeforces),遠遠領先于市面上已有的全部非o1類模型,并在工程類代碼場景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
值得注意的是,V3在中文和數學相關基準測試中表現尤為突出。
在美國數學競賽(AIME 2024, MATH)和全國高中數學聯賽(CNMO 2024)上,V3大幅超過了所有開源閉源模型。在中文能力上,V3 與 Qwen2.5-72B 在教育類測評 C-Eval 和代詞消歧等評測集上表現相近,但在事實知識 C-SimpleQA 上更為領先。
訓練成本極低
按照美媒Venture Beat的說法,雖然V3已成為市場上最強大的開源模型,但其訓練成本卻非常非常低。
通過在上一代DeepSeek-V2上的成功驗證,V3沿用了可以大幅降低顯存占用的MLA(多頭潛注意)和DeepSeekMoE(混合專家)架構,其具有6710億參數,每次推理激活370億參數,這種方法確保了高效的訓練及推理。在訓練階段,DeepSeek使用了多種硬件和算法優化,包括FP8混合精度訓練框架和用于管道并行的DualPipe算法,以降低訓練成本。
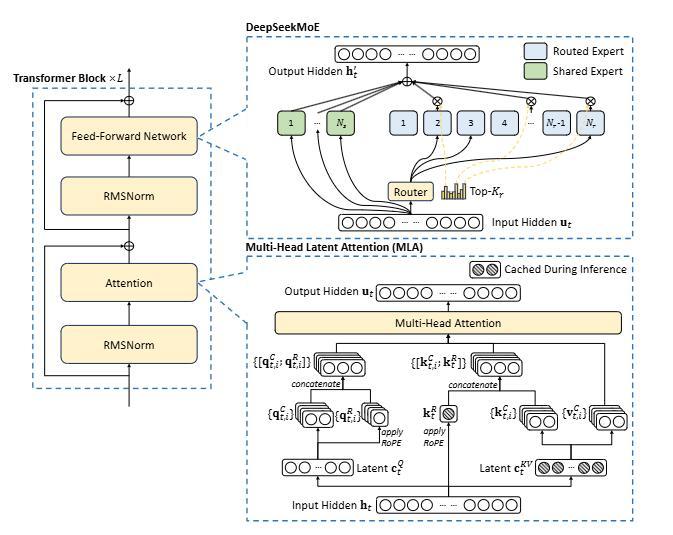
V3基礎架構,DeepSeek創新的MLA被用于高效推理,DeepSeekMoE則用于經濟訓練。DeepSeek論文
DeepSeek聲稱,V3 實現了極高的訓練效率。在約278.8萬個英偉達 H800 GPU小時內完成了V3的整個訓練,假設GPU的小時租金為2美元,總成本就是約為557萬美元。這遠低于通常用于預訓練大語言模型動輒上億美元的成本,比如Llama-3.1的預訓練成本估計就超過5億美元。
DeepSeek還通過算法和工程上的創新,使V3的生成吐字速度從20TPS大幅提高至60TPS,相比V2.5模型實現了3倍的提升,在處理多模態數據和長文本時表現突出。而隨著性能更強、速度更快的V3更新上線,DeepSeek的模型API服務定價也調整為每百萬輸入tokens 0.5元(緩存命中)/2元(緩存未命中),每百萬輸出tokens 8元。
量化基金轉型人工智能
公開資料顯示,在DeepSeek背后是量化私募巨頭幻方(High-Flyer Quant),也是大廠外唯一一家儲備上萬張英偉達 A100芯片的公司。幻方成立于2008年,總部位于中國杭州,專注于利用數學、統計學和計算機技術進行金融市場的量化分析和交易。
自2023年四季度以來,A股市場不斷下行,而利用數學模型和計算機程序等技術手段進行投資決策的量化基金曾被作為“罪魁禍首”受到輿論的沖擊,這也讓幻方旗下基金表現一直落后于滬深300指數4個百分點。
不過,隨著今年5月DeepSeek-V2發布,幻方量化卻成功轉型為人工智能先驅,其超低價格甚至引發了國內大模型的價格戰,DeepSeek也被迅速冠以“AI界拼多多”之稱。這反映出百度和阿里巴巴等科技巨頭,盡管在生成式人工智能領域已處于領先地位,但仍需要面對著來自新玩家的激烈競爭。
幻方創始人梁文鋒此前曾回應稱,DeepSeek定價原則就是不貼錢,但也不賺取暴利。只是讓他也沒想到的是,DeepSeek的定價卻讓各大廠商紛紛降價,然而DeepSeek自身反而卻是有利潤的。
“字節是第一個跟進的,其旗艦模型降到和我們一樣的價格,然后觸發了其它大廠紛紛降價”,梁文鋒解釋說,“因為大廠的模型成本比DeepSeek高很多,所以DeepSeek沒想到會有人虧錢做這件事,最后就變成了互聯網時代的燒錢補貼的邏輯。”
梁文鋒認為,更多的投入并不一定產生更多的創新,否則大廠可以把所有的創新包攬了。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
