

 新火種
2025-01-08
新火種
2025-01-08 


AI華佗?港中大、深圳大數據研究院提出醫療推理大模型HuatuoGPT-o1

編輯 | 白菜葉
OpenAI o1 的突破凸顯了通過增強推理能力來提高自然語言大模型(LLM)的應用潛力。然而,大多數推理研究都集中在數學任務上,而醫學等領域尚未得到充分探索。
醫學領域雖然不同于數學,但鑒于醫療保健的高標準,它也需要強大的推理能力來提供可靠的答案。然而,與數學不同,驗證醫學推理具有挑戰性。
為了解決這個問題,香港中文大學,深圳市大數據研究院的研究人員提出了可驗證的醫學問題,使用醫學驗證器來檢查模型輸出的正確性。
同時,該團隊推出了 HuatuoGPT-o1,這是一款能夠進行復雜推理的醫學 LLM,僅使用 40K 個可驗證問題,其表現就優于醫學專用基線。
該研究以「HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs」為題,于 2024 年 12 月 25 日發布在arXiv預印平臺。

類似 o1 的方法在醫學等專業領域的應用仍未得到充分探索。醫療任務通常涉及復雜的推理。
在現實世界的醫療診斷或決策中,醫生往往需要仔細斟酌。這一關乎生命的重要領域要求縝密的思考,確保得出更為可靠的結論。
并且,醫療領域具有獨特的優勢:與一般領域相比,醫療領域的范圍通常較窄,且更易于驗證。此外,醫療推理與金融、法律、教育和安全等領域的實際應用密切相關,使得該領域的進展能夠輕松地遷移到其他領域。
HuatuoGPT-o1
盡管存在這些優勢,醫學推理中的一個關鍵挑戰在于驗證其思維過程,這一過程通常缺乏清晰的步驟。受數學問題通過其結果進行驗證的啟發,研究人員從具有挑戰性的閉卷醫學考試題目中重構了 40,000 個可驗證的醫學問題。
這些可驗證問題的特點是開放式且具有唯一的客觀真實答案,使得大型語言模型(LLM)驗證器能夠檢查解決方案的正確性。
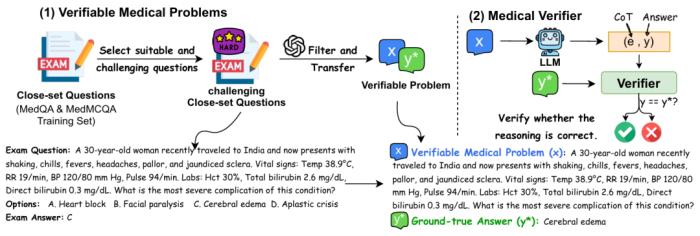
圖示:利用具有挑戰性的閉卷考試題目構建可驗證醫學問題;驗證器將模型的答案與真實答案進行對比檢查。(來源:論文)
這為推進醫學復雜推理提供了一種方法:
第一階段:學習復雜推理
該團隊通過基于驗證器反饋(正確或錯誤)的策略搜索構建復雜推理軌跡。大型語言模型(LLM)首先初始化一個思維鏈(CoT)。如果驗證器拒絕當前的思維鏈,模型將通過應用從回溯、探索新路徑、驗證和修正中采樣的策略來擴展思維鏈,直到提供正確答案。成功的推理軌跡隨后用于微調大型語言模型,使其能夠發展出體現迭代反思的復雜推理能力。
第二階段:通過強化學習增強復雜推理
在掌握復雜推理技能后,強化學習(RL)進一步優化這一能力。具體而言,驗證器提供的稀疏獎勵通過近端策略優化(PPO)算法引導模型進行自我改進。
通過這種方法,研究人員提出了 HuatuoGPT-o1,這是一種能夠生成長思維鏈(CoT)以識別錯誤、嘗試不同策略并優化答案的醫學大型語言模型(LLM)。
HuatuoGPT-o1(僅使用 40K 數據點)在 8B 模型上實現了醫學基準測試 8.5 分的提升。此外,70B 版本的 HuatuoGPT-o1 在多個醫學基準測試中優于其他開源通用及醫學專用 LLM。
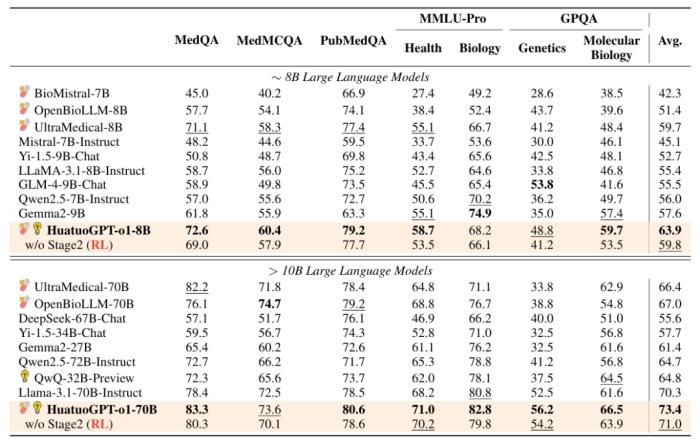
圖示:醫學基準測試的主要結果。(來源:論文)
該研究表明,與標準方法或非思維鏈方法相比,復雜推理能夠增強醫學問題解決能力并提升強化學習(RL)性能。
總之,該研究顯著提升了大型語言模型的醫學推理能力。實驗表明,復雜推理能夠顯著提升醫學問題解決能力,并從強化學習中明顯受益。
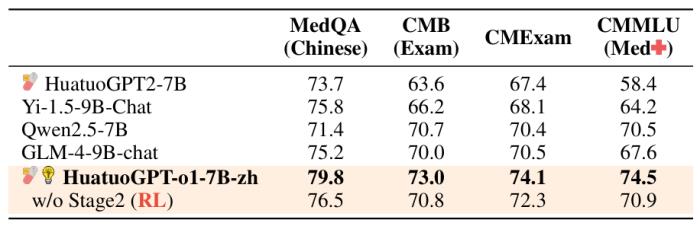
在中醫場景中的額外驗證進一步證明了該方法在其他領域的適應性。研究人員相信,該方法能夠超越數學領域,增強特定領域的推理能力,能夠激發醫學和其他專業領域的推理進步。
模型地址:https://github.com/FreedomIntelligence/HuatuoGPT-o1
論文鏈接:https://arxiv.org/abs/2412.18925
相關內容:https://x.com/_akhaliq/status/1873572891092283692
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
