把注意力計算丟給CPU,大模型解碼吞吐量提高1.76~4.99倍
CPU+GPU,模型KV緩存壓力被緩解了。來自CMU、華盛頓大學、Meta AI的研究人員提出MagicPIG,通過在CPU上使用LSH(局部敏感哈希)采樣技術,有效克服了GPU內存容量限制的問題。與僅使用GPU的注意力機制相比,MagicPIG在各種情況下提高了1.76~4.99倍的解碼吞吐量,并
CPU+GPU,模型KV緩存壓力被緩解了。來自CMU、華盛頓大學、Meta AI的研究人員提出MagicPIG,通過在CPU上使用LSH(局部敏感哈希)采樣技術,有效克服了GPU內存容量限制的問題。與僅使用GPU的注意力機制相比,MagicPIG在各種情況下提高了1.76~4.99倍的解碼吞吐量,并
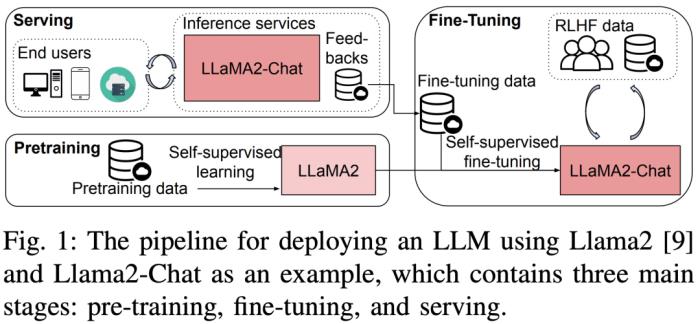
這是為數不多深入比較使用消費級 GPU(RTX 3090、4090)和服務器顯卡(A800)進行大模型預訓練、微調和推理的論文。大型語言模型 (LLM) 在學界和業界都取得了巨大的進展。但訓練和部署 LLM 非常昂貴,需要大量的計算資源和內存,
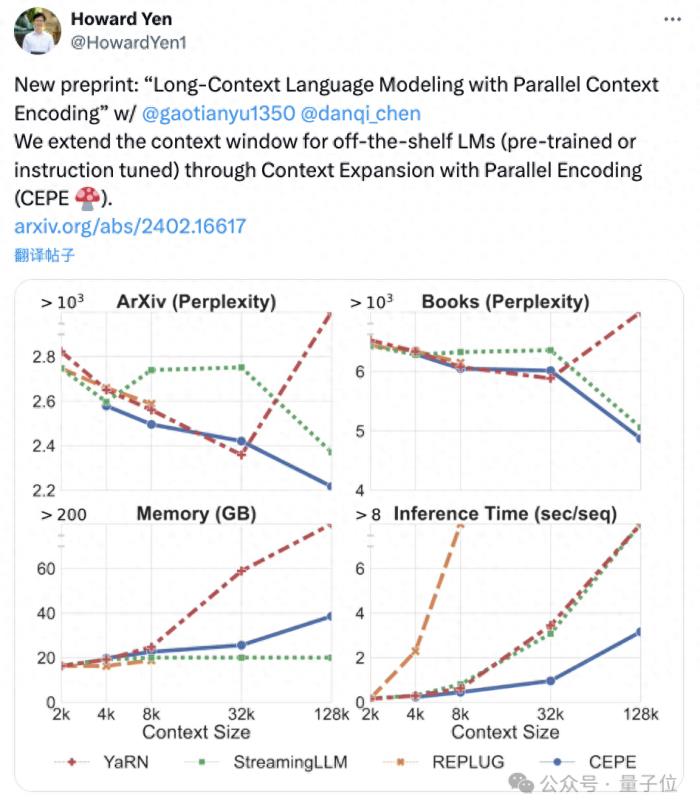
陳丹琦團隊剛剛發布了一種新的LLM上下文窗口擴展方法:它僅用8k大小的token文檔進行訓練,就能將Llama-2窗口擴展至128k。
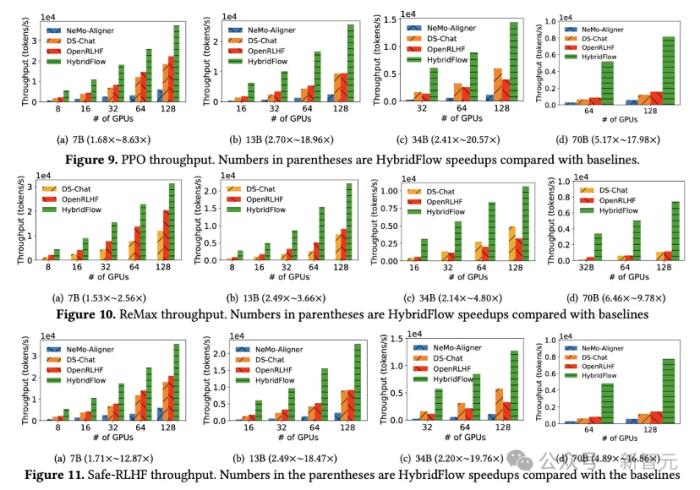
強化學習(RL)對大模型復雜推理能力提升有關鍵作用,但其復雜的計算流程對訓練和部署也帶來了巨大挑戰。近日,字節跳動豆包大模型團隊與香港大學聯合提出 HybridFlow。這是一個靈活高效的 RL/RLHF 框架,可顯著提升訓練吞吐量,降低開發和維護復雜度