大模型推理效率無損提升3倍,滑鐵盧大學、北京大學等機構發布EAGLE
大語言模型(LLM)被越來越多應用于各種領域。然而,它們的文本生成過程既昂貴又緩慢。這種低效率歸因于自回歸解碼的運算規則:每個詞(token)的生成都需要進行一次前向傳播,需要訪問數十億至數千億參數的 LLM。這導致傳統自回歸解碼的速度較慢。
大語言模型(LLM)被越來越多應用于各種領域。然而,它們的文本生成過程既昂貴又緩慢。這種低效率歸因于自回歸解碼的運算規則:每個詞(token)的生成都需要進行一次前向傳播,需要訪問數十億至數千億參數的 LLM。這導致傳統自回歸解碼的速度較慢。

12月3日下午,“讀懂廣州”系列論壇“打造數產融合全球標桿城市”分論壇在廣州越秀國際會議中心舉行。會上,北京大學數字中國研究院(華南)院長助理、研究員傅瑜以“高質量發展數實融合探索路徑”為題作主旨演講。

據國家知識產權局公告,北京大學取得一項名為“一種基于AI識別的多品類固廢再利用智能系統”,授權公告號CN117085970B,申請日期為2023年10月。

2023年12月18日消息,據國家知識產權局公告,北京大學取得一項名為“一種分布式多智能體合作方法、系統、介質及設備“,授權公告號CN116578636B,申請日期為2023年5月。專利摘要顯示,本公開涉及一種分布式多智能體合作方法、系統、介質及設備。

類別級 6D 物體位姿估計是一個基礎且重要的問題,在機器人、虛擬現實和增強現實等領域應用廣泛。本文中,來自北京大學的研究者提出了一種類別級 6D 物體位姿估計新范式,取得了新的 SOTA 結果,論文已被機器學習領域頂會 NeurIPS 2023 接收。

【明日主題前瞻】字節跳動與北京大學成立“豆包大模型系統軟件聯合實驗室”
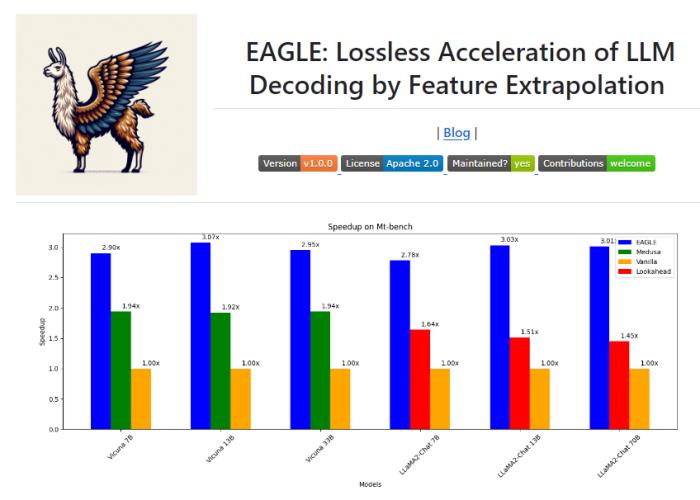
EAGLE采用外推大語言模型的第二頂層特征向量的方法,相較于普通自回歸解碼,其推理速度提升明顯,比普通自回歸解碼快3倍,比Lookahead解碼快2倍,比Medusa解碼快1.6倍。

2023年12月4日消息,據國家知識產權局公告,北京大學申請一項名為“基于圖神經網絡模型的組合邏輯電路等價性判定方法”,公開號CN117150920A,申請日期為2023年9月。

觀點網訊:12月12日,北京大學-字節跳動“豆包大模型系統軟件聯合實驗室”簽約儀式暨“面向大模型的智能化軟件技術與生態”學術研討會在北京大學英杰交流中心隆重舉行。會上消息,推動產學研深度融合對促進人工智能核心技術突破具有重要意義,此次聯合實驗室的成立是校企協同創新的重要里程碑,將依托雙方優勢,共同推

2023年12月20日消息,據國家知識產權局公告,北京大學申請一項名為“一種衍射神經網絡全光非線性激活器件及其實現方法“,公開號CN117250807A,申請日期為2023年9月。專利摘要顯示,本發明公開了一種衍射神經網絡全光非線性激活器件及其實現方法。