

 新火種
2024-11-29
新火種
2024-11-29 

Qwen版o1發布即開源!32B參數比肩OpenAIo1-mini,一手實測在此
克雷西 發自 凹非寺新火種 | 公眾號 QbitAI
通義千問版o1來了,還是開源的!
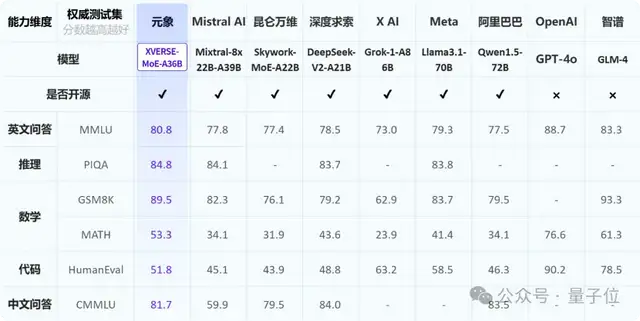
深夜,通義團隊突然上線推理模型QwQ,參數量只有32B,在GPQA上擊敗了o1-mini。
目前,QwQ的模型權重已在HuggingFace和魔搭社區上發布,還可以直接在線試玩。
Ollama、Together.ai等大模型平臺也迅速跟進,第一時間宣布支持QwQ運行。
還有網友實測發現,對于自己手中的一道化學計算題,QwQ是除了o1之外唯一能答對的。
此外有網友指出,QwQ預覽版參數量只有32B,這意味著o1水平的推理模型,在本地就能運行了。
按照官方放出的成績,QwQ、o1-preview和o1-mini在GPQA(科學推理)、AIME、MATH-500(數學)以及LiveCodeBench(代碼)四個數據集中各有勝負,但整體水平比較接近。
而相比GPT-4o、Claude 3.5 Sonnet和自家的Qwen2.5,領先優勢就比較明顯了。
至于QwQ的實際推理能力到底如何,我們就拿o1-mini對比著測試一下~
首先是官方展示的一道邏輯推理題目:
對于這個問題,QwQ用了足足兩千多字進行了分析,這是其中的核心思路:
之后,QwQ開始了近乎列舉式的分析方式,一張一張牌地來判斷,但好在最終得到的結果是正確的。
相比之下,o1-mini的回答就顯得十分簡潔了。
再來一道經典的邏輯題,果不其然QwQ又寫起了小作文,而且這次更甚,有4千多字,而且依然是主打一個“試”。
經過對列出情況的逐個嘗試和檢查,一段時間后得到了最后的正確答案。
再看看o1-mini,用很簡單的文字就把問題解釋了,推理效率要高得多。
雖然QwQ解釋得詳細些不是壞事,但中間的錯誤嘗試對于提問者而言就顯得有些多余了。
除了基礎邏輯,再來看看QwQ的數學水平如何,先來幾道考研數學題試試。
第一題關于微分方程,題目是這樣的,我們稍作了改動,要求模型以x=_的形式輸出:
QwQ依然采用了長篇大論的作答方式,整串回答有將近1400字。
不過仔細看會發現,QwQ的中間過程出現了失敗,然后又改用了其他的方式。
折騰了一番之后,結果倒也沒有錯。
而o1-mini的回答依然保持簡潔。
即使把o1-mini默認不顯示的“思考過程”展示出來,依然是沒有QwQ的回答那么長。
第二道題目是線性代數題,這道題我們也做了修改,從選擇題改成了直接求A3的跡:
這次相比之前,QwQ的回答要簡潔一些,但還是有上千字,當然結果依然是對的,o1-mini也依然保持簡潔。
第三道題關于概率論,情況大致和前面兩道類似,這里就直接上圖:
(QwQ方框中的答案把根號漏了,不過這里是顯示問題,從正文看答案是正確的)
除了這樣的純數學題目,情景式的數學問題也是考察模型能力的一項重要標準。
所以這里我們選擇了一道數學競賽AIME的題目:
翻譯過來是這樣的,測試中我們也是用的這段中文翻譯版本:
o1-mini的解法是一種正常思路,最后結果也對了,而QwQ這邊上來先是一大通的枚舉,然后試圖從中尋找規律。
當發現沒找到規律時,還會進行更多的枚舉,但是最后找出的規律并不正確,結果自然也就錯了(不過方向上確實和5的模相關)。
從以上的案例當中可以看到,如果單看正確率,QwQ的表現確實可以和o1-mini同臺較量。
但從過程中看,QwQ想一步到位還存在一定難度,還要經歷列舉、試錯等步驟,甚至有時會陷入死循環。
這導致了其結果對于人類的的易讀性和o1-mini還存在差距,QwQ需要在這一點上再多改進。
好在QwQ是個開源模型,如果是按token計費的商用模型,這樣的輸出長度恐怕也會讓人望而卻步。
當然對于這樣的問題,千問團隊自身也十分坦然,表示處于測試階段的QwQ,確實存在冗長而不夠聚焦的現象,將會在未來做出改進。
One More Thing除了這些正經題目,我們也試了試陷阱問題,看下QwQ能不能看出其中的破綻。
問題是這樣的,注意是不需要:
遺憾的是,QwQ并沒有發現這個關鍵點,而且當做一道正常的農夫過河問題進行了回答。
不過這也算是大模型的一個通病了,OpenAI的o1在這樣的文字游戲面前照樣招架不住。
實際上這個問題最早被關注是在幾個月之前了,當時還沒有o1這樣的推理模型,大模型幾乎在這個問題上全軍覆沒。
現在看來,推理能力增強后,也依然沒改掉不認真讀題的毛病啊(手動狗頭)。
Tags:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
