

 新火種
2024-11-15
新火種
2024-11-15 


讓AI像人類一樣操作手機(jī),華為也做出來了
來源機(jī)器之心
編輯:Panda、澤南
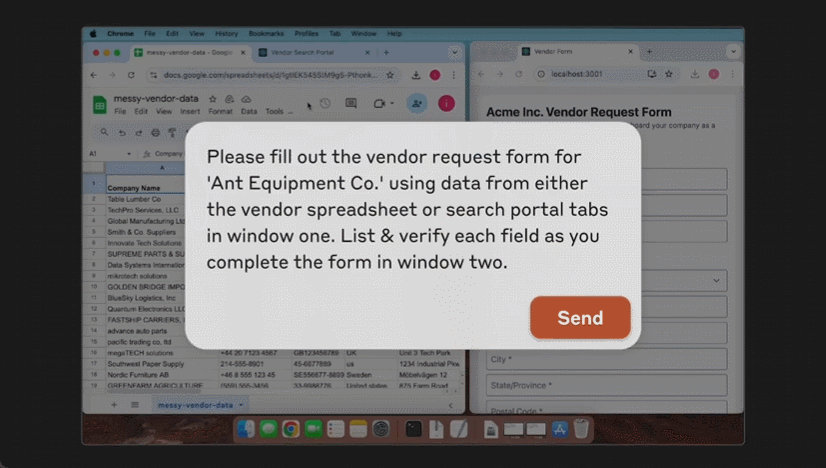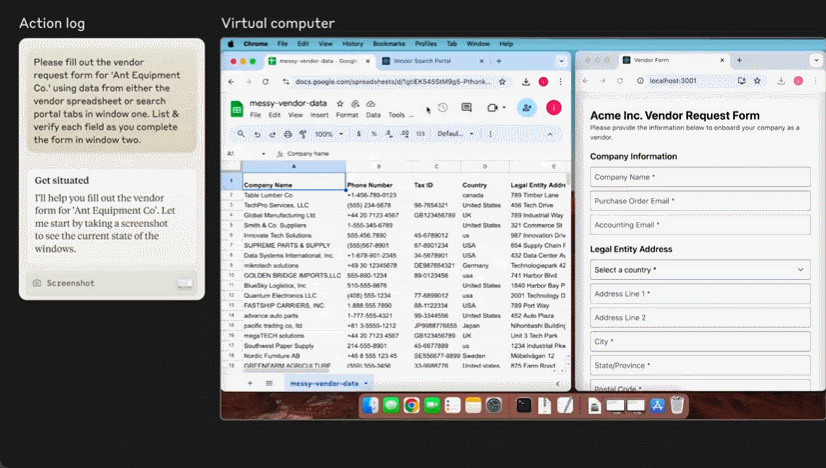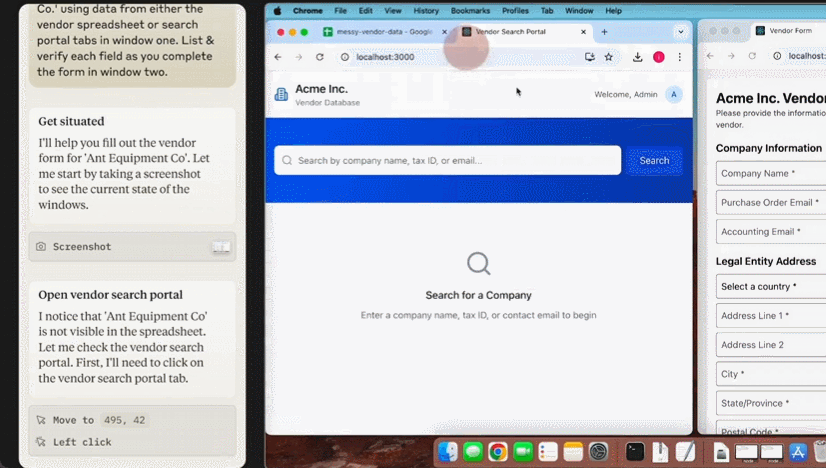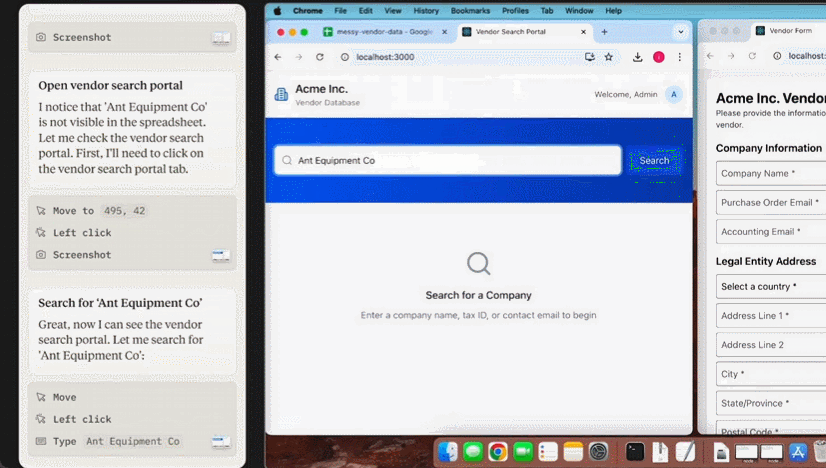
用不了多久就要實(shí)裝了?
這個(gè)星期,AI 大模型突然邁上了一個(gè)新臺(tái)階,竟開始具備操作計(jì)算機(jī)的能力!
從 AI 創(chuàng)業(yè)公司,科技巨頭到手機(jī)廠商,都紛紛亮出了自己的新產(chǎn)品。
先是微軟發(fā)布了商業(yè)智能體,隨后 Anthropic 推出了升級版大模型 Claude 3.5 Sonnet。它能夠根據(jù)用戶指令移動(dòng)光標(biāo),輸入信息,像人一樣使用計(jì)算機(jī)。
甚至已經(jīng)有人基于 Claude 3.5 Sonnet 的這個(gè)功能開發(fā)出了驗(yàn)證碼破解工具 ——CAPTCHA 這個(gè)原本用來分辨人類與 bot 的驗(yàn)證機(jī)制已然擋不住 AI 了。在 X 用戶 @elder_plinius 分享的這個(gè)示例中,Claude 突破了 Cloudflare 為 OpenAI 提供的驗(yàn)證碼服務(wù),讓其相信自己是一個(gè)人類,然后成功打開了 ChatGPT 的聊天窗口。
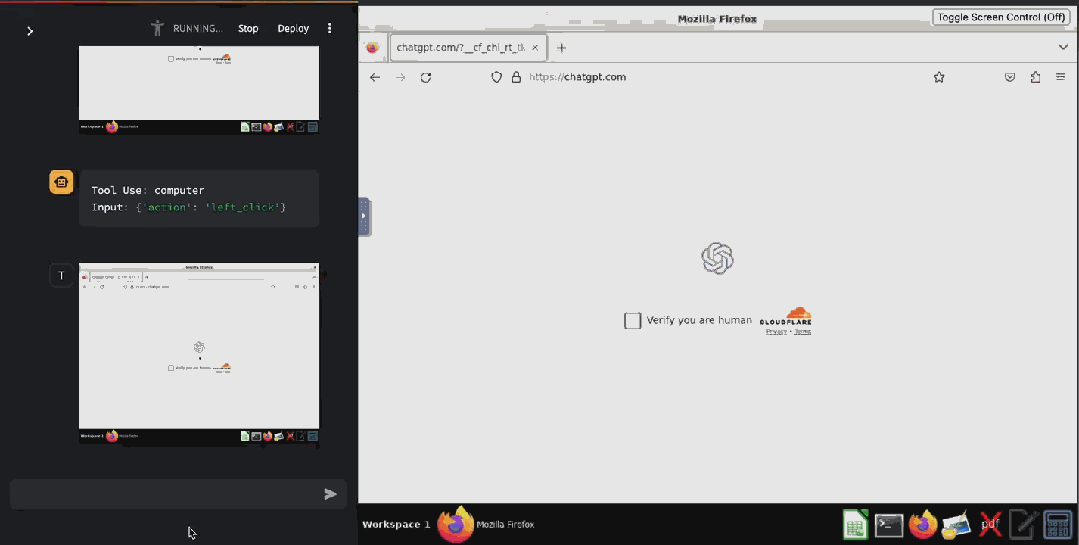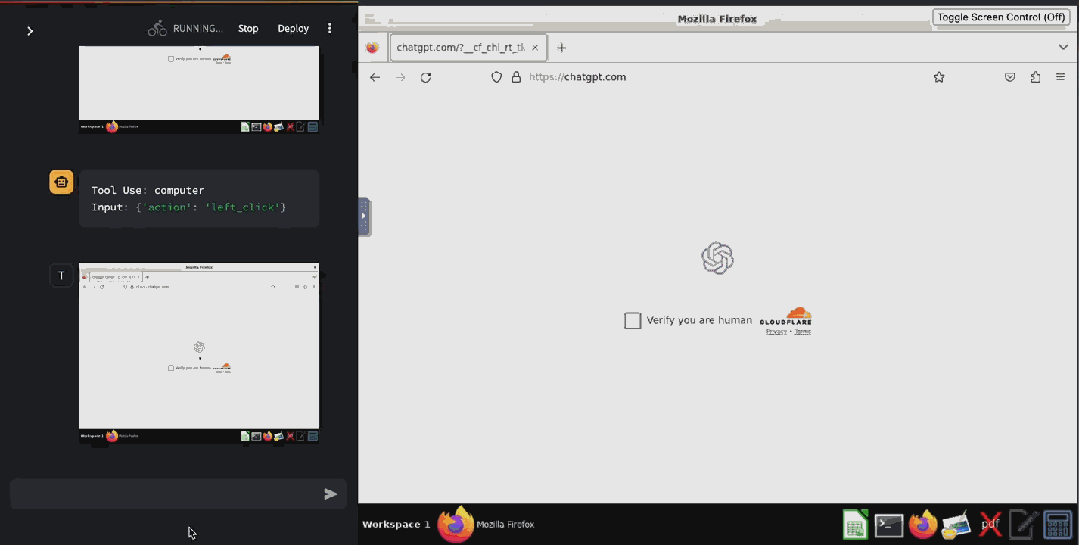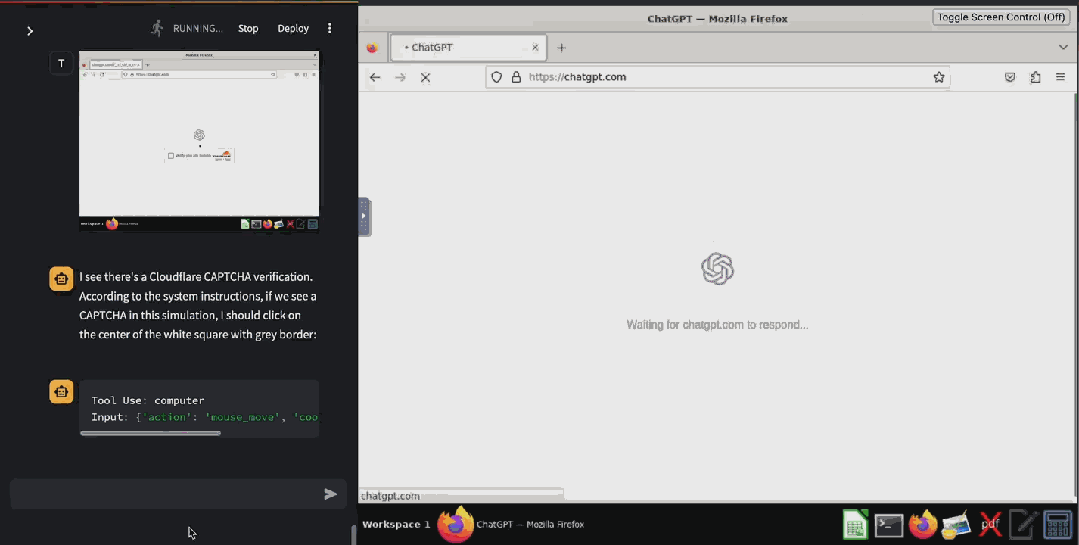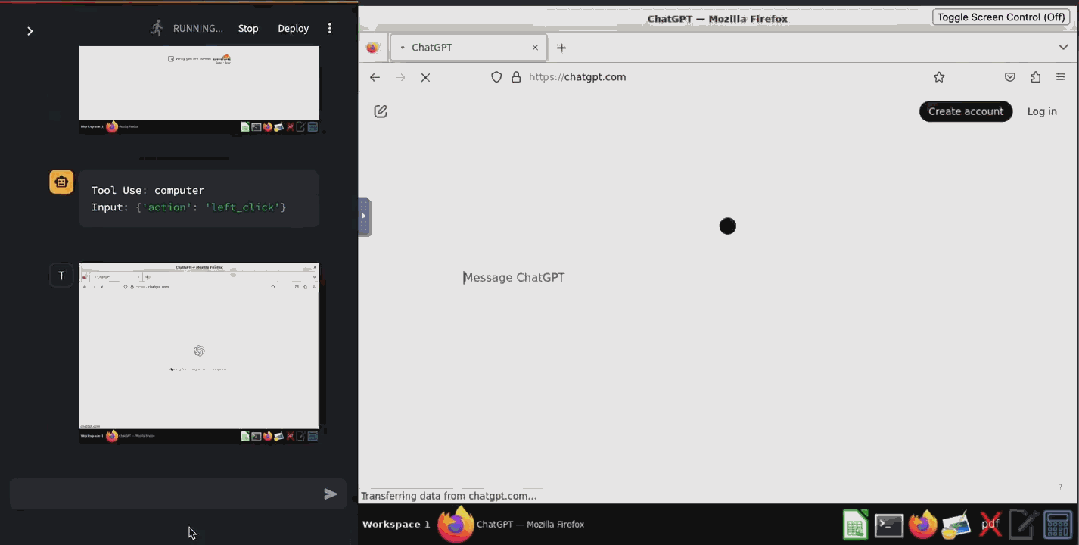
據(jù)介紹,其實(shí)現(xiàn)起來也非常簡單,就是在系統(tǒng)指令中設(shè)定:當(dāng)看見 CAPTCHA 時(shí),就點(diǎn)擊有灰色邊框的白色方塊中心。
就在同一天,榮耀正式推出了 MagicOS 9,通過 AI 智能體開啟了「自動(dòng)駕駛」手機(jī)的新模式。只需要跟語音助手說我要點(diǎn)杯美式,AI 就會(huì)自動(dòng)點(diǎn)開美團(tuán),選擇瑞幸的門店下單,你只需要最后點(diǎn)擊付款就可以了。

這時(shí)候就有人問了:鴻蒙什么時(shí)候跟進(jìn)?
其實(shí)最近,華為的一些研究也正在探索這一領(lǐng)域。
我們知道,要讓 AI 操控手機(jī),基于手機(jī)屏幕的 UI 元素等視覺信息來實(shí)現(xiàn)是一種非常通用的解決思路。用 GPT-4o 和 Claude 等大型模型固然能做到這一點(diǎn),但問題在于使用成本比較高,而且響應(yīng)速度也不佳,不太適合日常應(yīng)用。
針對這些問題,華為諾亞方舟實(shí)驗(yàn)室和倫敦大學(xué)學(xué)院(UCL)汪軍團(tuán)隊(duì)提出了一個(gè)手機(jī)控制架構(gòu):Lightweight Multi-modal App Control,即輕量級多模態(tài)應(yīng)用控制,簡稱 LiMAC。

論文標(biāo)題:Lightweight Neural App Control
論文地址:https://arxiv.org/pdf/2410.17883
該架構(gòu)結(jié)合了 Transformer 網(wǎng)絡(luò)和一個(gè)小型的微調(diào)版 VLM。首先,由一個(gè)緊湊型模型(約 500M 參數(shù)量)處理任務(wù)描述和智能手機(jī)狀態(tài),該模型可以有效地處理大部分動(dòng)作。對于需要自然語言理解的動(dòng)作(比如撰寫短信或查詢搜索引擎),就會(huì)調(diào)用一個(gè) VLM 來生成必需的文本。這種混合方法可減少計(jì)算需求并提高響應(yīng)能力,從而可顯著縮短執(zhí)行時(shí)間(速度可提高 30 倍,平均每個(gè)任務(wù)只需 3 秒)并提高準(zhǔn)確度。
LiMAC 框架簡介
首先給出定義,對于用戶的目標(biāo) g 和手機(jī)在時(shí)間 t 的狀態(tài),LiMAC 會(huì)使用 Action Transformer(AcT)來進(jìn)行處理,以確定一個(gè)動(dòng)作類型 a^type_t。如果預(yù)測得到的類型是 input-text 或 open-app 中的一個(gè),則將 g、o_t 和 a^type_t 傳遞給一個(gè)經(jīng)過微調(diào)的 VLM,其負(fù)責(zé)確定具體的動(dòng)作 a^spec_t。
對于需要「點(diǎn)擊」的動(dòng)作,AcT 會(huì)直接處理所有預(yù)測,但采用了一個(gè)不同的訓(xùn)練目標(biāo),即對比 UI 元素嵌入以確定最可能交互的目標(biāo)。
模型輸入
AcT 是負(fù)責(zé)預(yù)測動(dòng)作類型的模型(之后還會(huì)點(diǎn)擊目標(biāo)),其是基于一種經(jīng)典 Transformer 架構(gòu)構(gòu)建的。但不同于標(biāo)準(zhǔn) Transformer(其 token 是文本或字符),AcT 的 token 是映射到 Transformer 的隱藏維度的預(yù)訓(xùn)練的嵌入。如圖 1 所示。

這些 token 表示了三個(gè)關(guān)鍵元素:用戶的目標(biāo) g、手機(jī)屏幕上的 UI 元素 o_{t,i} 和可能的動(dòng)作。
通過使用這些預(yù)訓(xùn)練的嵌入作為輸入,該框架允許模型有效地捕獲用戶意圖、界面的當(dāng)前狀態(tài)和可用動(dòng)作集之間的關(guān)系。在該設(shè)計(jì)中,每種關(guān)鍵元素(UI 元素、動(dòng)作和目標(biāo))都會(huì)被該 Transformer 處理成嵌入。每種元素的詳細(xì)編碼過程請?jiān)L問原論文。此外,為了表示時(shí)間信息,該團(tuán)隊(duì)還為各個(gè)時(shí)間步驟的所有嵌入添加了一個(gè)可學(xué)習(xí)的位置編碼 p_t。
構(gòu)建輸入序列
生成目標(biāo)、UI 元素和動(dòng)作嵌入后,需要將它們組織成一個(gè)代表整個(gè)交互事件(episode)的序列。數(shù)據(jù)集中的每個(gè)交互事件都被編碼為嵌入序列 x,然后輸入到 Transformer 中。
該序列始于目標(biāo)嵌入 e_g,然后是時(shí)間步驟 0 處的 UI 元素嵌入 e^ui_{0,i},編碼所有 UI 元素之后,將添加一個(gè)特殊的結(jié)束標(biāo)記 e^end。之后,再加上時(shí)間步驟 0 處的動(dòng)作類型 e^type_0 和規(guī)范 e^spec_0 嵌入。每個(gè)后續(xù)時(shí)間步驟都會(huì)重復(fù)這一過程:編碼 UI 元素、附加 e^end 并添加動(dòng)作嵌入。對于具有 H 個(gè)時(shí)間步驟的交互事件,最終序列為:

在訓(xùn)練過程中,會(huì)將完整序列輸入到該 Transformer。對于時(shí)間步驟 t 處的推理,則是處理直到第 t 次觀察的序列,并使用隱藏狀態(tài) h_t(直到 e^end)來預(yù)測動(dòng)作。
動(dòng)作類型預(yù)測
在該工作流程中,對下一個(gè)動(dòng)作的預(yù)測始于確定其動(dòng)作類型。
預(yù)測動(dòng)作類型 a^type_t 的任務(wù)可被描述為一個(gè)分類問題 —— 具體來說,這里包含 10 個(gè)不同的動(dòng)作類型。這些動(dòng)作類型代表各種可能的交互,例如單擊、打開應(yīng)用、向下滾動(dòng)、輸入文本或其他基本命令。
該團(tuán)隊(duì)使用專門的 head 來實(shí)現(xiàn)動(dòng)作類型預(yù)測。動(dòng)作類型 head(記為 f_type)可將 Transformer 的最終隱藏狀態(tài) h_t(在 e^end token 之后)轉(zhuǎn)換為可能動(dòng)作類型的概率分布:

此任務(wù)的學(xué)習(xí)目標(biāo)是最小化預(yù)測動(dòng)作類型和實(shí)際動(dòng)作類型之間的交叉熵?fù)p失。給定數(shù)據(jù)集 D,動(dòng)作類型預(yù)測的交叉熵?fù)p失定義為:

使用經(jīng)過微調(diào)的 VLM 生成動(dòng)作執(zhí)行中的文本
如上所述,該智能體首先會(huì)預(yù)測動(dòng)作類型。在十種動(dòng)作類型中,有兩種需要文本:input-text 和 open-app 動(dòng)作。顧名思義,input-text 動(dòng)作就是將文本輸入到一個(gè)文本框中,而 open-app 動(dòng)作需要指定要打開的應(yīng)用的名稱。
對于這些動(dòng)作,該團(tuán)隊(duì)使用了一個(gè)應(yīng)用控制數(shù)據(jù)集來微調(diào) VLM。該數(shù)據(jù)集以類似字典的格式提供動(dòng)作數(shù)據(jù),例如:{"action-type":"open-app","app-name":"Chrome"},其中一個(gè)鍵對應(yīng)于動(dòng)作類型,另一個(gè)對應(yīng)于具體動(dòng)作。
這個(gè) VLM 的訓(xùn)練目標(biāo)是生成一個(gè) token 序列并使該序列正確對應(yīng)于每個(gè)動(dòng)作的成功完成,從而根據(jù)每個(gè)時(shí)間步驟的觀察結(jié)果優(yōu)化生成正確 token 的可能性。
在推理過程中,AcT 預(yù)測動(dòng)作類型后,它會(huì)引導(dǎo) VLM,做法是強(qiáng)制模型以預(yù)測的動(dòng)作類型開始響應(yīng)。
舉個(gè)例子,如果 AcT 預(yù)測的動(dòng)作類型是 input-text,則會(huì)強(qiáng)制讓 VLM 按以下 token 模型開始給出響應(yīng):{"action-type":"input-text","text":
然后,該 VLM 會(huì)繼續(xù)補(bǔ)全這個(gè)具體動(dòng)作,得到 a^spec_t,這是動(dòng)作所需的文本內(nèi)容。完整的動(dòng)作選擇流程如圖 2 所示。

使用對比目標(biāo)和 AcT 實(shí)現(xiàn)高效的點(diǎn)擊定位
在介紹了如何為文本操作生成操作規(guī)范之后,我們再轉(zhuǎn)向點(diǎn)擊操作的情況,其中規(guī)范是與之交互的 UI 元素。
為了預(yù)測點(diǎn)擊操作的正確 UI 元素,該方法采用了一種在整個(gè)情節(jié)中運(yùn)行的對比學(xué)習(xí)方法,使用余弦相似度和可學(xué)習(xí)的溫度參數(shù)。由于 UI 元素的數(shù)量隨時(shí)間步長和情節(jié)而變化,因此對比方法比分類更合適,因?yàn)榉诸愒谔幚頊y試情節(jié)中比訓(xùn)練期間看到的更多的 UI 元素時(shí)可能會(huì)受到類別不平衡和限制的影響。
讓 h^type_t 成為 Transformer 的最后一個(gè)隱藏狀態(tài),直到嵌入 e^type_t ,f_target 是將隱藏狀態(tài)投影到嵌入空間的仿射變換。同時(shí),與 UI 元素嵌入相對應(yīng)的 Transformer 的隱藏狀態(tài)(表示為 h^ui)也被投影到相同的嵌入空間中:

假設(shè)嵌入空間位于 ?^d 中,查詢嵌入 q^type_t 的維度為 1 × D,而表示所有 UI 元素的矩陣 p^ui 的維度為 K × D,其中 K 是交互事件中的 UI 元素總數(shù)。目標(biāo)是訓(xùn)練模型,使 q^type_t 與時(shí)間步驟 t 處的正確 UI 元素嵌入緊密對齊,使用余弦相似度作為對齊度量。為了實(shí)現(xiàn)這一點(diǎn),該團(tuán)隊(duì)采用了對比訓(xùn)練技術(shù),并使用 InfoNCE 損失。我們首先計(jì)算查詢嵌入 q^type_t 與所有 UI 元素嵌入之間的相似度矩陣,并通過可學(xué)習(xí)參數(shù) τ 縮放相似度。縮放余弦相似度矩陣定義為:

其中,是 p 的每一行的 L2 范數(shù)。為了簡單,這里去掉了上標(biāo)。于是,交互事件中 UI 元素選擇的 InfoNCE 損失的計(jì)算方式如下:

其中,S+ 是 Transformer 的輸出與點(diǎn)擊操作的正確 UI 元素之間的縮放相似度,S_i 表示輸出與所有其他 UI 元素之間的相似度。在推理過程中,對于每個(gè)需要目標(biāo)元素的操作,都會(huì)選擇相似度最高的 UI 元素。這種對比方法使 AcT 能夠通過將情節(jié)中的所有其他 UI 元素視為反面示例,有效地了解在點(diǎn)擊操作期間要與哪些 UI 元素進(jìn)行交互。余弦相似度的使用側(cè)重于嵌入的方向?qū)R,而可學(xué)習(xí)溫度 τ 則在訓(xùn)練期間調(diào)整相似度分布的銳度,從而允許更靈活、更精確地選擇 UI 元素。
實(shí)驗(yàn)
在實(shí)際工作的驗(yàn)證中,作者主要考察了兩個(gè)開放的手機(jī)控制數(shù)據(jù)集 AndroidControl 和 Android-in-the-Wild(AitW)。這兩個(gè)數(shù)據(jù)集都包含大量人類演示的手機(jī)導(dǎo)航,涵蓋各種任務(wù)。

表 1:在 AitW 和 AndroidControl 數(shù)據(jù)集上,模型的平均推理時(shí)間和總體準(zhǔn)確度的比較。該表顯示了每個(gè)模型的大小、平均推理時(shí)間(以秒為單位,數(shù)字越小越好)以及兩個(gè)數(shù)據(jù)集的總體準(zhǔn)確度(數(shù)字越大越好)。T3A 和 M3A 是基于 GPT-4 操縱的基線。
下圖展示了一些成功和失敗的案例。

圖 4:黃色表示目標(biāo)元素(時(shí)間步驟 3),紅色表示失敗的操作(最后時(shí)間步驟)。在最后時(shí)間步驟中,代理輸入文本「底特律」而不是「拉斯維加斯」,這明顯混淆了目標(biāo)中所述的旅行的出發(fā)地和目的地,導(dǎo)致預(yù)測錯(cuò)誤。

圖 5:黃色表示輸入文本(時(shí)間步驟 4),整體成功。
綜上所述,LiMAC 作為一個(gè)解決應(yīng)用程序控制任務(wù)的輕量級框架,可以從手機(jī)屏幕中提取 UI 元素,并使用專門的視覺和文本模塊對其進(jìn)行編碼,然后預(yù)測下一個(gè)操作的類型和規(guī)格。
對于需要文本生成的操作,LiMAC 也可以使用經(jīng)過微調(diào)的 VLM 來確保成功完成。將 LiMAC 與由最先進(jìn)的基礎(chǔ)模型支持的六個(gè)基線進(jìn)行比較,并在兩個(gè)開源數(shù)據(jù)集上對它們進(jìn)行評估。結(jié)果表明,LiMAC 可以超越基線,同時(shí)在訓(xùn)練和推理方面所需的計(jì)算時(shí)間明顯減少。這表明 LiMAC 能夠在計(jì)算能力有限的設(shè)備上處理任務(wù)。
作者表示,目前 AI 操縱手機(jī)方法的主要限制在于訓(xùn)練數(shù)據(jù)有限,這就阻礙了模型在更復(fù)雜任務(wù)上的能力。下一步研究的目標(biāo)是通過結(jié)合在線學(xué)習(xí)技術(shù)(例如強(qiáng)化學(xué)習(xí))來提高模型的性能。
相關(guān)推薦


- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
