

 新火種
2024-08-22
新火種
2024-08-22 


OpenAI終于發布GPT-4omini,但比中國大模型晚了半年
美國時間 7 月18 日,OpenAI 正式發布了多模態小模型 GPT-4o mini,在海內外引起了廣泛關注。
此前,OpenAI 憑借 GPT-3 開拓了 AI 模型的“暴力美學”時代,同時也以訓練超大參數規模的模型能力建立起 AGI 同賽道的護城河。但在其推出 GPT-4o 的“Mini”版本之后,OpenAI 似乎走向了原有優勢的反方向,開始卷“小模型”,而值得注意的是:
在 Mini 這條路上,歐洲與中國的大模型團隊已經率先研究了大半年。
從 2023 年上半年智譜 AI 發布對話小模型 ChatGLM-6B,10 月 Mistral 發布 7B 模型,到 2024 年 2 月面壁智能團隊祭出 2.4B 的 MiniCPM,緊接著是多模態小模型 8B MiniCPM-Llama3-V 2.5,還有商湯的 1.8B SenseChat Lite、上海人工智能實驗室 OpenGV Lab 團隊的 Intern-VL 系列……
基于通用大模型開發小模型或端側模型的路線,此前已在國內發酵大半年。如今,OpenAI 等世界級頭部 AI 企業的入局,更表明端側模型、“智能小模型”是大勢所趨。
GPT-4o 發布后,AI 技術大牛 Andrej Karpathy 也在推特上發表了自己對“小模型”的看法:

在 Andrej Karpathy 看來,未來將會出現參數規模小、但思考能力強的小模型;小模型才是 AI “大模型”的最終目標。
Andrej Karpathy 指出,現在的 AI 模型之所以“大”,是因為目前模型的訓練仍比較粗放;換言之,即訓練不高效——面壁智能團隊在 3 月與 AI 科技評論的交談中就已表達相似觀點。
如何讓小模型更智能?Andrej 認為關鍵點在于模型的知識,即訓練數據。目前來看,無論是 OpenAI、還是面壁智能等團隊,他們的路線都是先將模型“做大”、然后再將模型“做小”,原因在 Andrej 看來,是因為“小模型需要依托大模型來重構理想的合成數據”,直到大模型中的高質量數據被耗盡。
除數據考慮外,面壁團隊還告訴 AI 科技評論,從 2023 年下半年開始,他們通過建立一套“用大模型訓練小模型”的沙盒實驗機制,是為了驗證他們所理解的“Scaling Law”,即模型參數規模隨著時間推移遞減、但智能水平不斷上升的“面壁定律”——大模型的智能密度每 8 個月翻一倍。
如果模型能在越小的規模上實現更高的智能,那么模型的訓練與推理成本都將大幅下降。但據 AI 科技評論了解,該方向對算法與數據工程的挑戰也十分巨大,中間的技術門檻并不低。
隨著成本下降,英偉達的 GPU 需求量也將受到影響。有業內人士向 AI 科技評論評價,“對英偉達來說,相比 GPT-4o 或 GPT-4o mini,年底的 GPT-5 才是一個關鍵節點。”
同時,從商業上來看,GPT-4o mini 作為一個性價比極高的云端模型,對國內外云端 API 市場也將造成沖擊,大規模的云端模型更難賺錢;相反,端側模型將成為新的市場“顯學”。
GPT-4o mini 能力揭秘
作為 GPT-4o 更小參數的簡化版本,此次 GPT-4o mini 的發布意味著 OpenAI 正式“進軍”多模態小模型。據官網介紹,目前,在API層面,GPT-4o mini支持128k、16k輸入tokens(圖像和文本),未來還將支持視頻和音頻的輸入和輸出。
但是,OpenAI 并未透露此次新模型的參數量大小。
數據顯示,GPT-4o mini 在文本智能和多模態推理方面的學術基準測試中超越了 GPT-3.5 Turbo 和其他小模型,并且支持的語言范圍與 GPT-4o 相同。此外, GPT-3.5 Turbo 相比,其長上下文性能也有所提高。
與 GPT-4 相比,GPT-4o mini 在聊天偏好上表現優于 GPT-4 ,并在大規模多任務語言理解(MMLU)測試中獲得了82%的得分。公開資料介紹,MMLU 是一項包含 57 個學科大約 16000 道多項選擇題的考試,得分越高的大模型在各種領域中理解和使用語言的能力越強。
從 OpenAI 提供的數據來看,GPT-4o mini 的得分為82%,Google 的 Gemini Flash得分為77.9%,Anthropic 的Claude Haiku 得分為73.8%,GPT-4o mini 能力更強:
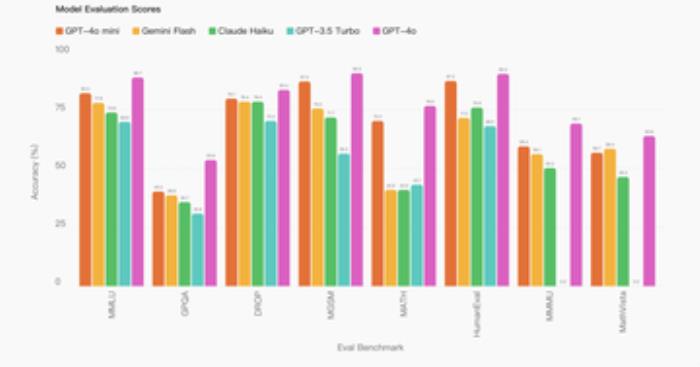
在實現性能優化的同時,價格也更便宜。
OpenAI 表示,GPT-4o mini 的成本為每百萬輸入標記(token)15 美分,每百萬輸出標記 60 美分,比 GPT-3.5 Turbo 便宜超過 60%。即日起正式向免費版、Plus 版和團隊版的 ChatGPT 用戶開放,企業用戶則從下周開始可使用。
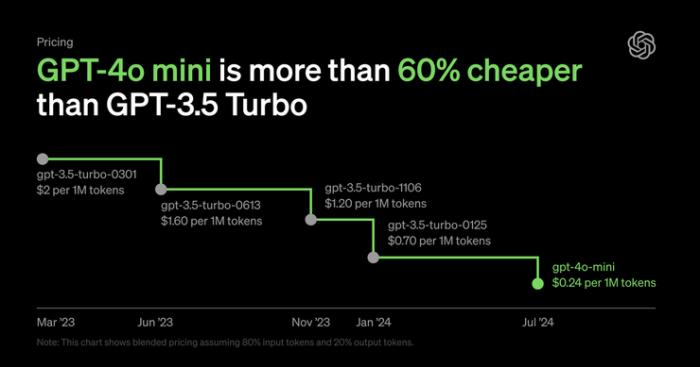
OpenAI 也想在小模型市場“分一杯羹”。
此前,無法承擔 OpenAI 模型昂貴費用的開發者往往會選擇更便宜的替代,如 Gemini 1.5 Flash 及 Claude 3 Haiku,這或許也是此次 OpenAI 推出小模型的主要原因——為開發者提供更為輕量且廉價的工具,以創建其無法負擔的大模型(如 GPT-4)的應用程序和工具。
對于此次 GPT-4o mini 的推出,社交平臺上外國網友們似乎存在不少不買賬的聲音,部分網友催促 OpenAI 發布 GPT-4o 完整版,「No one wants a cheaper 3.5. We want a better 4o.」(沒有人想要更便宜的3.5,我們想要更好的4o),還有網友顯然對于 GPT-4.5 以及 GPT-5 的熱情更盛。
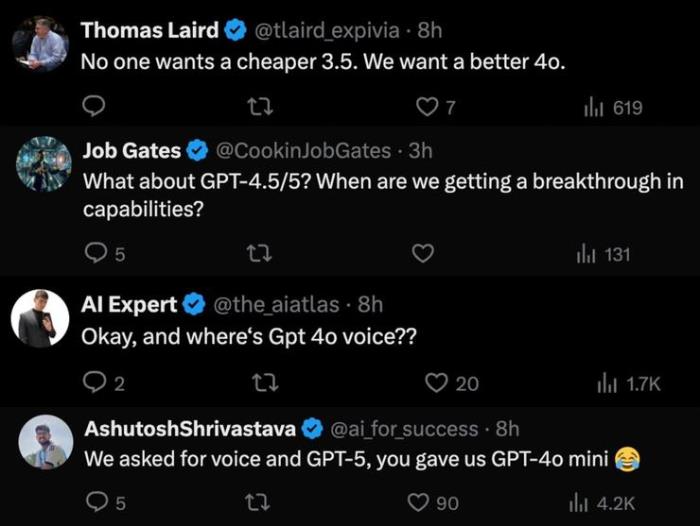
但也有國產大模型團隊指出,GPT-4o mini 是相對 GPT-4o 的“Mini”版本,具體參數量不詳,因此如商湯、面壁智能、上海人工智能實驗室等團隊難以與其比拼。
OpenAI 退出中國市場后,對國內模型團隊的影響有限。一位端側模型從業者告訴 AI 科技評論,OpenAI 在 Mini 模型上的這一舉動,或許是為了響應硅谷智能硬件興起的浪潮,同時對蘋果 AI 在端側能力上的需求作出反應。
從今年上半年開始,蘋果 AI 團隊相繼發布其在手機端側上運用的 AI 成果,如 Ferret-UI、OpenELM、MM1 等等,對模型落到端側起了開頭。相當于,蘋果已經在手機 AI 端出了開卷考試,接下來各家模型廠商與手機廠商都要思考如何答題。
國產小模型不輸 OpenAI
而根據以往成果發布,國產大模型團隊在文本小模型、乃至多模態小模型上的能力也表現卓然:
今年 4 月,商湯發布了1.8B(18億)參數規模的 SenseChat-Lite版本,作為端側模型,交互體驗對標GPT-4,當時性能已實現同等尺度性能最優。
后來,在 WAIC 期間,商湯又再次進行端側模型的更新,較 4 月推出的版本首包耗時降低 40%,速度更快。
上海人工智能實驗室 OpenGV Lab 的 InternVL 也是中國多模態小模型的系列典范。從 InternVL-Chat-V1.5 到書生萬象 Intern VL 2.0,OpenGV Lab 團隊開源了從多模態模型系列,參數規模從 1B 到 76B 不等,其中小模型最高 8B、最小 1B,均可單卡部署。據 AI 科技評論了解,其 1B 版本的參數規模實際只有 938 M。
值得注意的是,OpenGV Lab InternVL 系列的 26B 自開源以來一直是 Hugging Face 上的當紅炸子雞,以開源不過兩周的 InternVL 2.0 為例,其 26B 在 Hugging Face 上的下載量已超過 6000 次。
同樣在 Mini 模型上發力的國產代表團隊還有面壁智能。他們在小模型上的成果包含基座模型與多模態模型,在 Hugging Face 上的下載量已經近 95 萬次,Github 上獲得超過 1 萬星標,這一端側模型系列不僅是開源社區口碑之作,甚至一度火到全網熱搜第一。
今年 2 月,面壁端側模型“小鋼炮”發布,具備 GPT-3 同等性能但參數僅為24億的 MiniCPM-2.4B ,把知識密度提高了大概 86 倍 (如下圖所示):
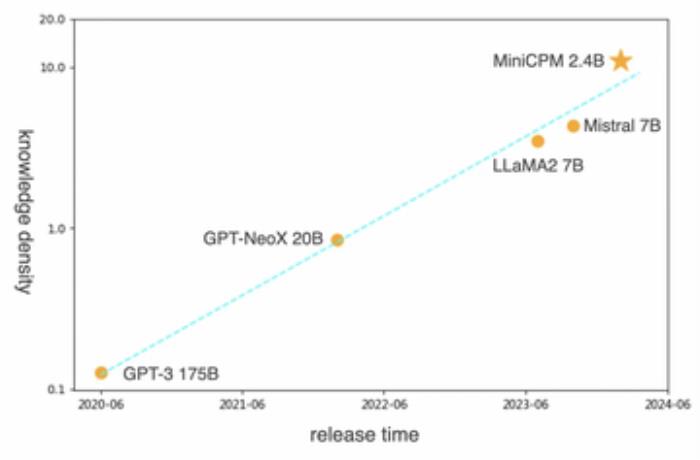
而后其又相繼在 4 、5月發布了2.0和2.5 版本。在 2.5 版本上,面壁 MiniCPM 以 1% 的參數規模,形成了可以跟GPT-4V 和 Gemini Pro 多模態能力對標的性能,模型參數只有 8B 大小,能夠放到終端上。
今年7月,面壁新發布的MiniCPM-S 1.2B 知識密度達到同規模稠密模型 MiniCPM 1.2B 的 2.57 倍,Mistral-7B 的 12.1 倍(如下圖所示):
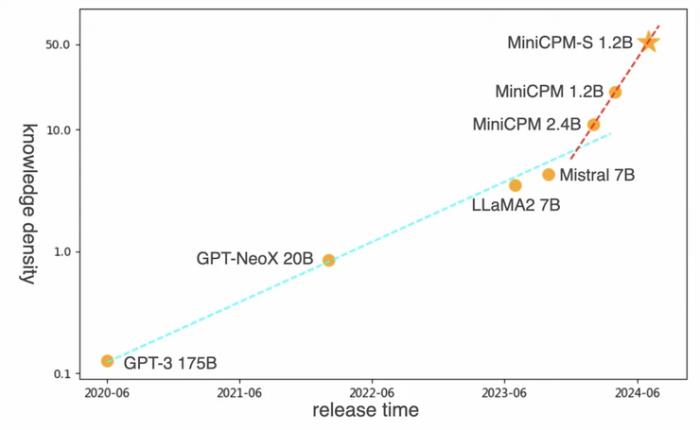
在面壁看來,他們做小模型的目標是“模型變小的同時、效果還能變好”。
當前,面壁有兩條產品線,一條是基座大模型,另一條是給大模型做小模型,在小模型上驗證大模型的技術極限。這兩條產品線,其實是一條路,就是面壁通往 AGI 的道路,大模型與小模型難以分開。一方面,要提升模型的效率,讓每個參數發揮更好的效果;另一方面,能在應用支持的成本下做出最好的模型。
而對于大模型,大眾的認知普遍存在偏差,實際上,參數規模大不代表模型的能力強。
以馬斯克的 Grok 為例,Grok 的參數規模為 3140 億,行內對它的評價其實不太好,有技術人員去測過,說 Grok 的效果大概比 Mistral 的 8*7B MoE 稍微好一點。那么大參數的模型實現這么小的效果,其實是失敗的。
在2021 年到 2022 年期間,國內最早做大模型的那批團隊扎堆卷模型參數量,阿里甚至將模型卷到了 10 萬億參數規模(非稠密模型)。
但當時大家對“大模型能做什么”是不清楚的,只是認為“大模型就是參數要大”,在用戶價值上,也并未達到后來 ChatGPT 的體驗。ChatGPT 發布后,大家才意識到“提升模型效果”才是大模型訓練的正確方向。
面壁認為,“小”模型的精髓在于高效,將每個參數發揮到最大作用——這才是大模型研究的正確方向。不然未來如果達到 AGI,但 AGI 比人還貴,那就沒意義了。
GPT-4o mini 的發布意味著能用更少的推理算力消耗實現更強更高效的模型,這也恰恰驗證了面壁提出的大模型時代的摩爾定律——模型的知識密度不斷提升,其中,知識密度=模型能力 / 推理算力消耗。
小模型的“新”挑戰
從年初開始,小模型的聲量開始增大。小模型崛起后,無疑帶來了幾個行業變化:
首先,計算成本更低的 AI 模型落到終端硬件產品上的門檻更低,端側模型興起。在此浪潮中,模型層廠商如面壁智能、手機廠商如蘋果華米OV 等也紛紛入局,端側模型的創業也迎來更多玩家。
端側模型雖然是“小”模型,但其智能水平也離不開一個基礎的大模型,同時需要具備豐富的訓練數據與完善的數據工程系統,才能做可控的訓練。因此,端側模型往往要與具體的行業與特定領域相結合。
與此同時,端側模型需要結合模型、硬件與計算。據了解,當前主流芯片廠商在端側 AI 芯片上的供給成本仍沒打下來。一位業者告訴 AI 科技評論,某知名芯片廠商的報價是 300 美金一臺設備,折算下來超過 2000 元人民幣,現階段能支撐起如此高昂的計算成本的硬件設備只有汽車、醫療等高端行業。
其次,小模型的開源社區形成后,有業者也認為,這將使“大模型的研究進入高校科研者的舒適區”。“過去大模型因為算力成本高昂,只有工業者能支撐得起,但當小模型的成本降下來后,越來越多高校科研人員也能參與這一方向的研究。”
這意味著,小模型團隊的研發壓力也在加大,競爭或許會變得更加激烈。
此外,也有從業者指出,OpenAI 發布 GPT-4o mini 是近日來大模型價格戰的縮影。OpenAI 將云端 API 的價格打下來后,其他海內外的云端大模型廠商在 C 端應用上的壓力會更大,“模應一體”的發展路徑或許會迎來新的變局。
端側大模型興起后,端側設備自己提供智能化的底座并且負擔推理成本,且個人數據隱私有保障,一系列的應用公司借助終端設備廠商提供的智能化底座來做應用。對于用到千億參數模型的應用,將最終也陷入推理成本的拼殺。
李大海猜測,GPT-4o mini 會是一個寬 MOE 的模型、而非一個端側模型。“(GPT-4o mini)作為一個性價比很高的云端模型,一方面對云端 API 市場應該會造成沖擊,一方面降低大模型落地產業成本,讓我們對大規模行業應用的興起抱有更強信心。”
言歸正傳。OpenAI 此次發布 GPT-4o mini,頂級公司的入場再一次驗證了小模型的研究風向與必然趨勢。在這一方向上,中國的大模型研究團隊如面壁智能、上海人工智能實驗室等均領先半年左右提出自己的解決,國產大模型從跟隨到引領,也反應了國產大模型技術的日新月異。
“GPT-4o mini 主打的是更快,大小相對 GPT-4o 來說更加 mini。但由于 GPT-4o 參數不詳,因此 GPT-4o mini 是否為端側小模型、是否能單卡部署,仍然存疑。”一位業內人士向 AI 科技評論評價。
所以,對待國產大模型的技術成果,我們或許應該多一份“民族自信”。

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
