

 新火種
2024-08-21
新火種
2024-08-21 


手機跑大模型提速4-5倍!微軟亞研院開源新技術有CPU就行
有CPU就能跑大模型,性能甚至超過NPU/GPU!
沒錯,為了優化模型端側部署,微軟亞洲研究院提出了一種新技術——T-MAC。
這項技術主打性價比,不僅能讓端側模型跑得更快,而且資源消耗量更少。

咋做到的??
在CPU上高效部署低比特大語言模型
一般來說,要想在手機、PC、樹莓派等端側設備上使用大語言模型,我們需要解決存儲和計算問題。
常見的方法是模型量化,即將模型的參數量化到較低的比特數,比如4比特、3比特甚至更低,這樣模型所需的存儲空間和計算資源就會減少。
不過這也意味著,在執行推理時,需要進行混合精度的矩陣乘法運算(mpGEMM),即用低精度的權重和高精度的激活向量進行計算。
然而,現有的系統和硬件并不原生支持這種混合精度的矩陣乘法,因此它們通常需要將低精度的權重轉換回高精度,這個過程叫做反量化(dequantization)。
但這種方法不僅效率低,而且當比特數進一步降低時,并不能帶來性能上的提升。
對此,新技術T-MAC采用基于查找表(LUT)的計算范式,無需反量化,直接支持混合精度矩陣乘。
這樣,T-MAC不僅提高了推理性能,還使得模型更加統一和可擴展,尤其適合在資源受限的端側設備部署。
此外,T-MAC不依賴于專用的硬件加速器NPU或GPU,能夠僅利用CPU部署模型。甚至在某些情況下,它的推理速度可以超過專用加速器。

T-MAC的關鍵創新在于采用基于查找表(LUT)的計算范式,而非傳統的乘累加(MAC)計算范式。
T-MAC利用查找表直接支持低比特計算,從而消除了其他系統中必須的反量化操作,并且顯著減少了乘法和加法操作的數量。
經過實驗,T-MAC展現出了卓越的性能:
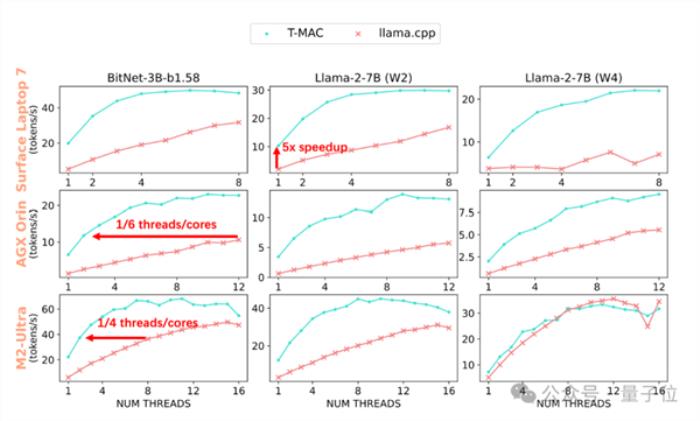
在配備了最新高通Snapdragon X Elite芯片組的Surface AI PC 上,3B BitNet-b1.58模型的生成速率可達每秒48個token,2bit 7B llama模型的生成速率可達每秒30個token,4bit 7B llama模型的生成速率可達每秒20個token。
這甚至超越了NPU的性能!
當部署llama-2-7B-4bit模型時,盡管使用NPU可以生成每秒10.4個token,但CPU在T-MAC的助力下,僅使用兩核便能達到每秒12.6個token,最高甚至可以飆升至每秒22個token。
這些都遠超人類的平均閱讀速度,相比于原始的llama.cpp框架提升了4~5倍。
 △BitNet on T-MAC (基于LUT) vs llama.cpp (基于反量化)
△BitNet on T-MAC (基于LUT) vs llama.cpp (基于反量化)
即使在較低端的設備如Raspberry Pi 5上,T-MAC針對3B BitNet-b1.58也能達到每秒11個token的生成速率。
同時,T-MAC也具有顯著的功耗優勢:
達到相同的生成速率,T-MAC所需的核心數僅為原始llama.cpp的1/4至1/6,降低能耗的同時也為其它應用留下計算資源。
值得注意的是,T-MAC的計算性能會隨著比特數的降低而線性提高,這一現象在基于反量化去實現的GPU和NPU中是難以觀察到的。
這進一步使得T-MAC能夠在2比特下實現單核每秒10個token,四核每秒28個token,大大超越了NPU的性能。
采用新的計算范式
好了,說完了效果,咱們接著展開T-MAC的技術細節。
矩陣乘不需乘,只需查表 (LUT)
對于低比特參數 (weights),T-MAC將每一個比特單獨進行分組(例如,一組4個比特),這些比特與激活向量相乘,預先計算所有可能的部分和,然后使用LUT進行存儲。
之后,T-MAC采用移位和累加操作來支持從1到4的可擴展位數。
通過這種方法,T-MAC拋棄了CPU上效率不高的FMA(乘加)指令,轉而使用功耗更低、效率也更高的TBL/PSHUF(查表)指令。
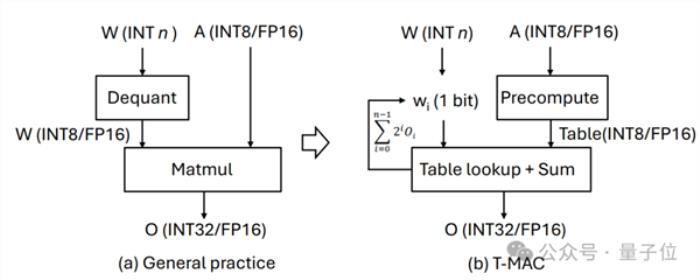 △混合精度GEMV基于現有反量化的實現范式 vs T-MAC基于查找表的新范式以比特為核心的計算,取代以數據類型為核心的計算
△混合精度GEMV基于現有反量化的實現范式 vs T-MAC基于查找表的新范式以比特為核心的計算,取代以數據類型為核心的計算
傳統的基于反量化的計算,實際上是以數據類型為核心的計算,這種方式需要對每一種不同的數據類型單獨定制。
每種激活和權重的位寬組合,如W4A16(權重int4激活float16) 和W2A8,都需要特定的權重布局和計算內核。
例如,W3的布局需要將2位和另外1位分開打包,并利用不同的交錯或混洗方法進行內存對齊或快速解碼。
然后,相應的計算內核需要將這種特定布局解包到硬件支持的數據類型進行執行。
而T-MAC通過從比特的視角觀察低比特矩陣乘計算,只需為單獨的一個比特設計最優的數據結構,然后通過堆疊的方式擴展到更高的2/3/4比特。
同時,對于不同精度的激活向量(float16/float32/int8),僅有構建表的過程需要發生變化,在查表的時候不再需要考慮不同的數據結構。
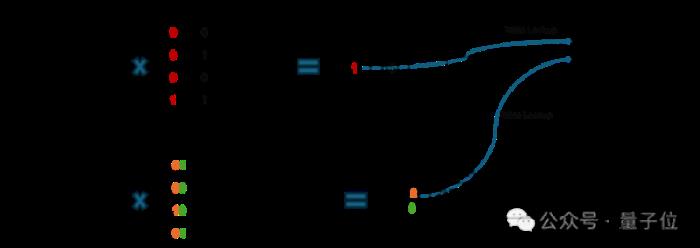 △以比特為核心的查表計算混合精度GEMV
△以比特為核心的查表計算混合精度GEMV
同時,傳統基于反量化的方法,從4-比特降低到3/2/1-比特時,盡管內存占用更少,但是計算量并未減小,而且由于反量化的開銷不減反增,性能反而可能會更差。
但T-MAC的計算量隨著比特數降低能夠線性減少,從而在更低比特帶來更好加速,為最新的工作BitNet, EfficientQAT等發布的2-比特模型提供了高效率的部署方案。
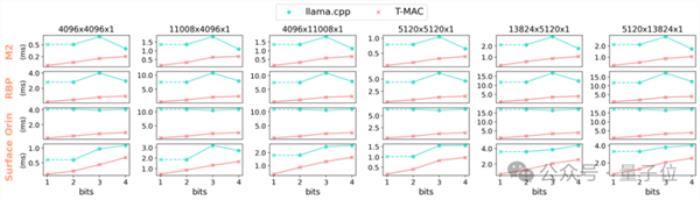
比如下圖展示了:
(1)使用不同端側設備CPU的單核,T-MAC在4到1比特的混合精度GEMV算子相較llama.cpp加速3-11倍。
(2)T-MAC的GEMM耗時能隨著比特數減少線性減少,而基于反量化的llama.cpp無法做到(1比特llama.cpp的算子性能由其2比特實現推算得到)。
高度優化的算子實現
概括而言,基于比特為核心的計算具有許多優勢,但將其實現在CPU上仍具有不小的挑戰:
與激活和權重的連續數據訪問相比,表的訪問是隨機的。
表在快速片上內存中的駐留對于最終的推理性能尤為重要,然而,片上內存是有限的,查找表(LUT)方法相比傳統的mpGEMV增大了片上內存的使用。
這是因為查找表需要保存激活向量與所有可能的位模式相乘的結果,這比激活本身要多得多。
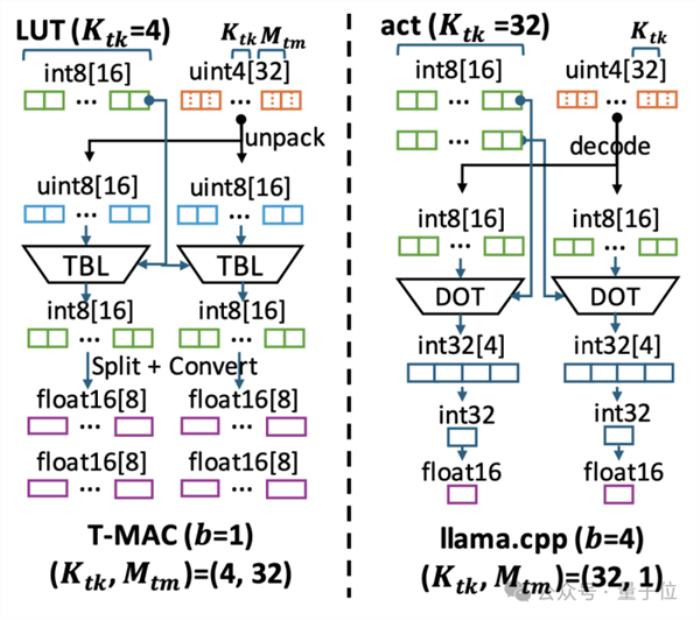
△T-MAC與llama.cpp在計算數據流上的不同
為此,微軟亞洲研究院的研究員們深入探究了基于查表的計算數據流,為這種計算范式設計了高效的數據結構和計算流程,其中包括:
1、將LUT存入片上內存,以利用CPU上的查表向量指令 (TBL/PSHUF) 提升隨機訪存性能。
2、改變矩陣axis計算順序,以盡可能提升放入片上內存的有限LUT的數據重用率。
3、為查表單獨設計最優矩陣分塊 (Tiling) 方式,結合autotvm搜索最優分塊參數
4、參數weights的布局優化:
a、weights重排,以盡可能連續訪問并提升緩存命中率
b、weights交錯,以提升解碼效率
5、對Intel/ARM CPU做針對性優化,包括
a、寄存器重排以快速建立查找表
b、通過取平均數指令做快速8-比特累加
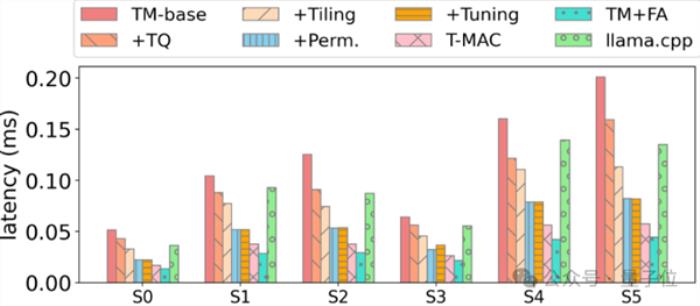
研究員們在一個基礎實現上,一步步應用各種優化,最終相對于SOTA低比特算子獲得顯著加速。
例如,在實現各種優化后,T-MAC 4-比特算子最終相對于llama.cpp獲得顯著加速:
最后,T-MAC現已開源,相關論文已在arXiv公開,感興趣可以進一步了解。
開源地址(含代碼):https://github.com/microsoft/T-MAC
論文:https://www.arxiv.org/pdf/2407.00088
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
