

 新火種
2023-12-26
新火種
2023-12-26 


NeurIPS2023Spotlight|騰訊AILab絕悟新突破:在星際2靈活策略應對職業選手
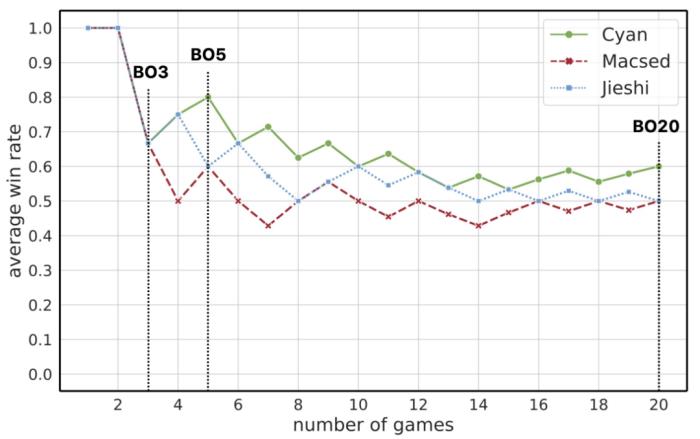
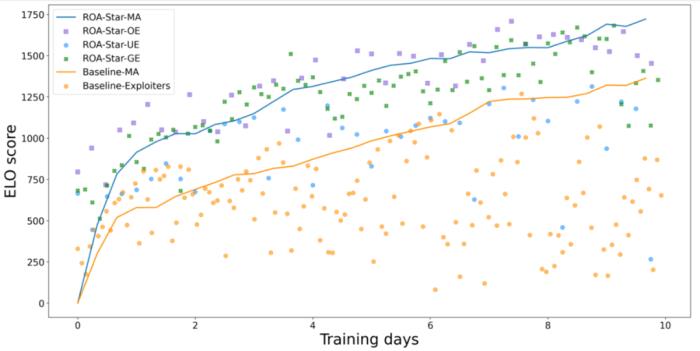
近日,騰訊 AI Lab 的游戲 AI 團隊宣布了其決策智能 AI "絕悟" 在《星際爭霸 2》中的最新研究進展,提出一種創新的訓練方法顯著提升了 AI 的局內策略應變能力,使其在考慮了 APM 公平的對戰環境中,與 3 位國內頂尖的神族職業選手各進行多達 20 局神族 vs 神族的對戰,穩定地保持 50% 及以上的勝率。該成果已獲 NeurIPS 2023 Spotlight 論文收錄。
實時策略游戲(RTS)以其復雜的游戲環境更貼近現實世界,一直是 AI 研究的焦點和挑戰所在。《星際爭霸 2》作為其中極具代表性的游戲,因其對資源收集、戰術規劃和對手分析的高實時要求,已成為業內廣泛用于訓練和驗證 AI 決策能力的理想平臺。早在 2018 年,騰訊 AI Lab 研發的 AI 就已擊敗游戲內最高難度的 AI。業界的聯盟訓練方法(League)雖然在星際 AI 強度上取得了突破性進展,但其中在 AI 局內策略應變能力以及訓練效率存在不足。針對這些問題,騰訊 AI Lab 研發了新的算法進行改進,一方面提出了一種基于目標條件的強化學習(Goal-Conditioned RL)方法來訓練利用者(Exploiter),使利用者在有限資源下能夠高效探索多樣策略并擊敗聯盟中的其他智能體(Agent);另一方面通過引入對手建模機制,有效提升了智能體面對不同對手戰術的應變能力。
這項研究有助于推進 AI 智能化,增強 AI 應對復雜問題的泛化能力。在從 MOBA 到足球、RTS,再到 3D 開放世界游戲(如 Minecraft)等多樣化游戲環境,“絕悟” 持續展現了其決策能力的提升。展望未來,決策智能 AI 將能更好地適應人類的真實需求,解決現實世界的復雜問題。基于目標條件的強化學習提升利用者訓練效果利用者(Exploiter)是聯盟訓練中的重要角色,用于發現聯盟中其他智能體的弱點,以豐富其他智能體陪練的對手池策略,為提升智能體策略應變能力提供基礎環境。
在經典的星際 AI 聯盟訓練框架中,利用者并沒有具體的目標策略指導,而是通過不斷的隨機探索來識別主智能體(Main Agent)和整個聯盟的弱點。然而,考慮到《星際爭霸 2》策略空間的龐大和復雜性,這種方法可能導致資源浪費和訓練低效。為了在有限的計算資源下提升利用者的學習效果,本研究提出了一種新穎的基于目標條件的強化學習訓練方法。該方法讓利用者能夠自動挑選有 “潛力” 的宏觀策略,并在相應宏觀策略條件下進行訓練,發現聯盟其他智能體的弱點。
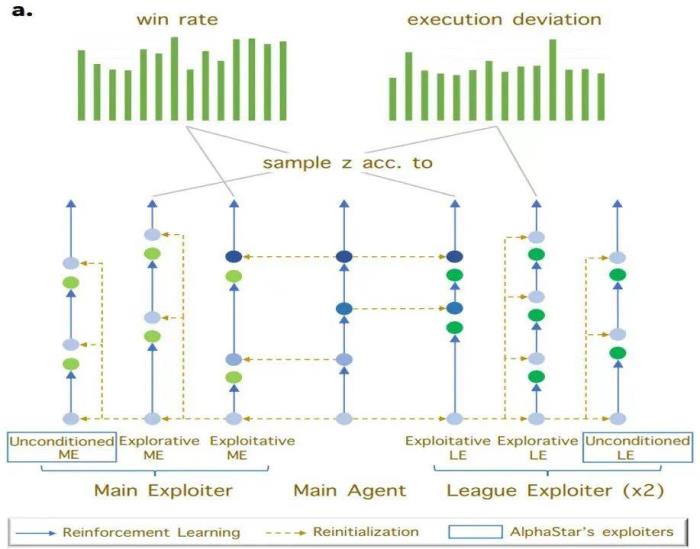
圖 1: 基于 goal-conditioned rl 的 exploiter 訓練示意圖如圖 1 所示,新方法通過評估主智能體在不同宏觀策略條件下的勝率和執行偏差,來指導利用者的策略選擇。從主智能體的高勝率宏觀策略中采樣的利用者被稱為利用型利用者(Exploitative Exploiter),它的特點在于參數會重置為當前主智能體的參數,利用主智能體在該宏觀策略下的高勝率能力,通過強化學習進一步提高微操技能,以擊敗其他智能體。同時,為了提升聯盟中能夠執行的宏觀策略多樣性,研究團隊引入了探索型利用者(Explorative Exploiter)。探索型利用者專注于學習主智能體在執行上存在大偏差的宏觀策略,以充分挖掘這類宏觀策略的價值。
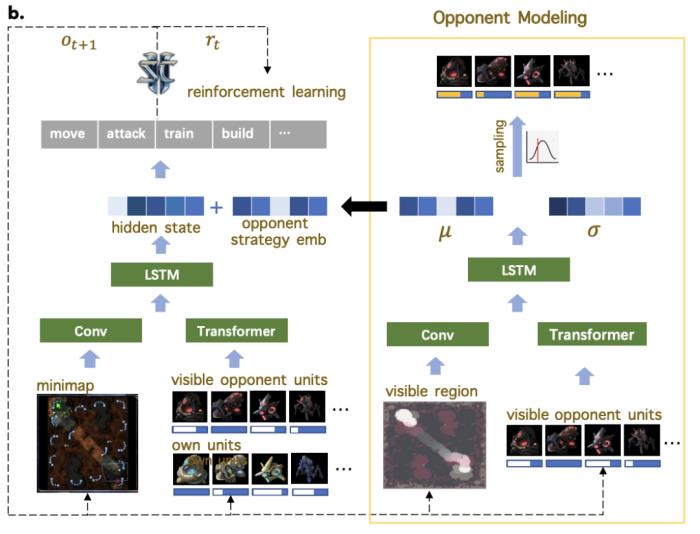
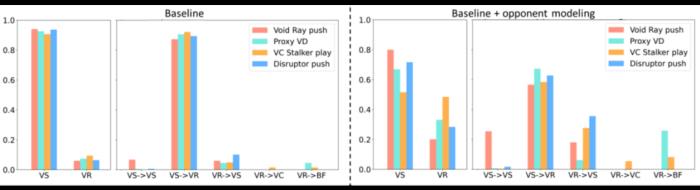
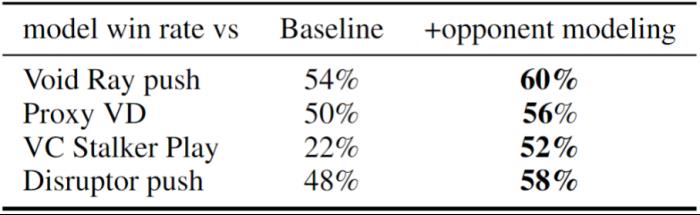
在訓練過程中,新方法除了將探索型利用者的參數重置為監督學習模型的參數外,還引入了課程學習機制和目標策略引導損失函數,以幫助其有效學習主智能體難以掌握的宏觀策略。基于對手建模提升 AI 局內策略應變能力局內策略應變能力在《星際爭霸 2》中至關重要,同時也是 AI 研究的一大挑戰。這一能力指的是 AI 根據對手的實時策略做出合理的自身策略調整。其難點在于 AI 需要在不完全的信息環境中快速準確地解讀和預測對手的策略,這不僅需要對復雜場景信息做高度抽象,還對預測能力有很高的要求。本研究基于對手建模的理念,增加了一個輔助任務網絡,專門用于估計對手的策略,并將這些信息的隱空間表達應用于主網絡的策略調整學習。
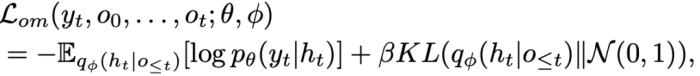
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
