

 新火種
2023-11-22
新火種
2023-11-22 


玩轉圍棋、國際象棋、撲克,DeepMind推出通用學習算法SoG
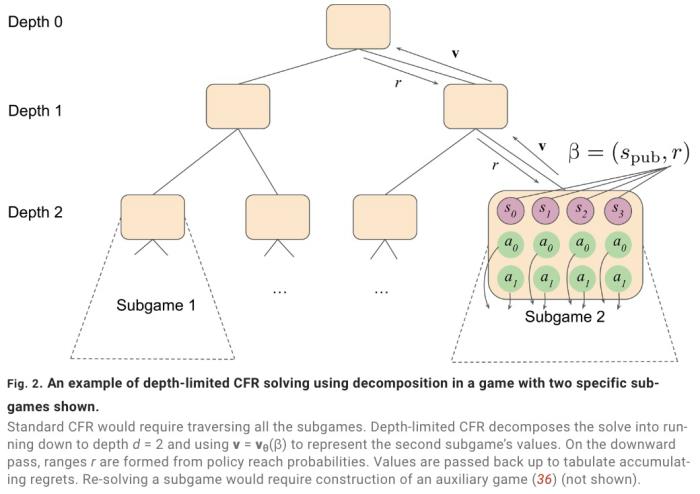
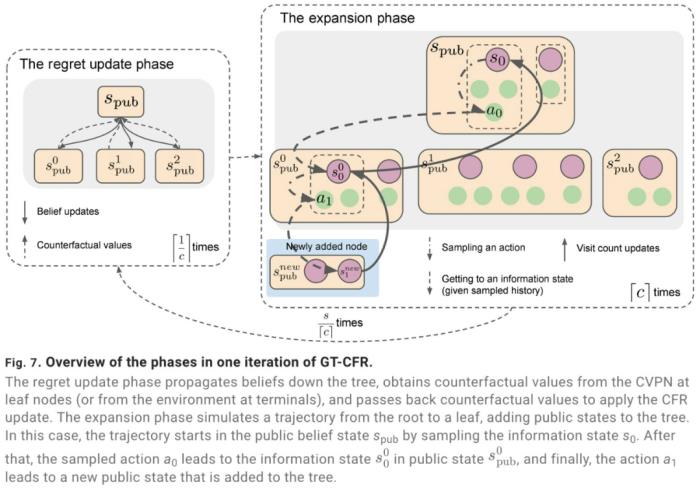
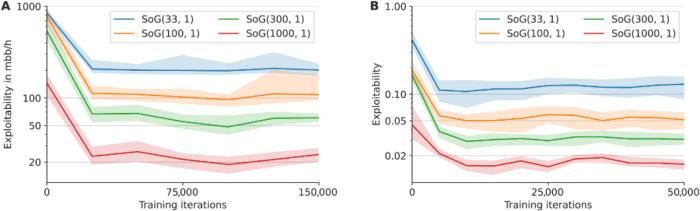
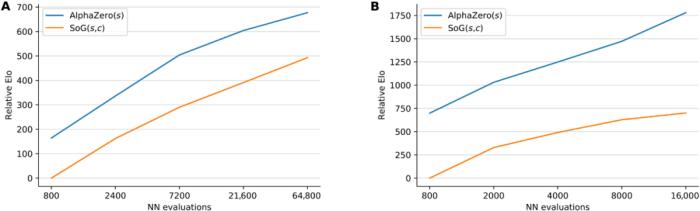
2016 年 3 月,一場機器人與圍棋世界冠軍、職業九段棋手李世石展開的圍棋人機大戰受到全球的高度關注。我們知道,最后的結果是 DeepMind 的機器人 AlphaGo 以 4 比 1 的總比分獲勝。這是人工智能領域一個里程碑性的事件,也讓「博弈」成為一個熱門的 AI 研究方向。AlphaGo 之后,DeepMind 又推出了贏得國際象棋的 AlphaZero、擊敗《星際爭霸 II》的 AlphaStar 等等。使用搜索和學習的方法,AI 在許多完美信息博弈中表現出強大的性能,而使用博弈論推理和學習的方法在特定的不完美信息博弈中表現出強大的性能。然而,大多數成功案例有一個重要的共同點:專注于單一博弈項目。例如,AlphaGo 不會下國際象棋,而 AlphaZero 雖然掌握了三種不同的完美信息博弈,但 AlphaZero 無法玩撲克牌,也不清楚能否擴展到不完美信息博弈。此外,現有研究往往會使用特定領域的知識和結構使 AI 實現強大的性能。現在,來自 Google Deepmind 的研究團隊提出了一種利用自我博弈學習、搜索和博弈論推理實現強大博弈性能的通用學習算法 ——Student of Games(SoG)。研究論文發表在《Science Advances》上。

相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
