

 新火種
2023-10-30
新火種
2023-10-30 


DeepMind用深度強化學習研究“人造太陽”!據說這是秘密進行了3年的工作
 “AI+物理”成功破圈,DeepMind 怕是要上天。
“AI+物理”成功破圈,DeepMind 怕是要上天。作者 | 王曄
編輯 | 陳彩嫻
北京時間凌晨四點,DeepMind在官方推特上發布消息,稱其與瑞士洛桑聯邦理工學院(EPFL)合作研究出第一個可以在托卡馬克(Tokamak)裝置內保持核聚變等離子體穩定的深度強化學習系統,為推進核聚變研究開辟了新途徑,工作已發表在Nature!
消息一出,立刻引起圍觀,收獲一千多點贊、數百轉發:
據該工作的其中一位成員@317070披露,該工作已經秘密進行了三年,并興沖沖地表示:“它真的成功了!深度強化學習真的很擅長搞定這些人類迫切想實現的科幻想法。”
我們都知道,DeepMind是全球最早將人工智能應用于科學研究(即“AI for Science”)的研究機構之一,在過去的幾年也取得了許多令人矚目的成就,成功地在生物、化學、數學與物理模擬等等領域扎下了AI的影子,并吸引一大批學者投身“AI for Science”方向的研究工作。
此前,在DeepMind兼職擔任高級研究科學家的華人學者王夢迪便曾對AI科技評論談到,DeepMind有強大的信心將人工智能用于推動人類文明的進步,這種自信也感染了許多年輕的科學家:
DeepMind的價值觀就是要推動人類文明的進步。我感覺研究人工智能的學者都非常自信,覺得自己有能力解決世界上最難的問題。這種自信非常棒,會給予自己主觀能動性,也會感染其他學者,幫助不同學科的人更快、更好地聯合在一起,去解決原先以為難于登天的問題。而近日DeepMind在難度更高的核物理發布突破成果,無疑更加證明、鞏固了其在“AI for Science”方向的領頭羊地位!
更有意思的是,AI科技評論編輯組還發現,早在五年前(2017年),就有中國網友在知乎上提出將深度強化學習系統用于學習可控核聚變裝置建造技術的設想。莫非 DeepMind 的科研是跟著知乎走的……(手動狗頭)
言歸正傳,我們來看看DeepMind這次又搞出了什么花樣!
什么是托卡馬克裝置?
首先,為了更好地了解DeepMind此次的突破,以及“AI+核聚變”的奧妙,我們需要知道:什么是托卡馬克(Tokamak)裝置?
此前,知乎上還有一個關于托卡馬克的討論:“劉慈欣在《三體》中為什么不待見托卡馬克裝置?(托卡馬克裝置有什么弊端)”:
鏈接:https://www.zhihu.com/question/31056640/answer/56816872
當時就有網友@Shigen Chin回答:
首先,超導托卡馬克的材料成本相對較高,相比之下激光核聚變只是設備一次性投資高,而超導托卡馬克對于裝備本身損耗比較嚴重,對于后續投入是不利因素(尤其是三體成為現實威脅 亟需技術突破的情況下)。其次,理論瓶頸,智子已經為物理理論研究建立壁壘,而超導托卡馬克作為一種相對而言在可控核聚變研究中出現較早的思路,一直到現在沒有大進展,很大程度上也是受理論研究所累,在沒有取得理論突破的情況下,托卡馬克裝置投入實用的可能性不大再次,托卡馬克本身的小型化十分困難,因為托卡馬克的實用功率和約束時間和裝備體積正相關,超低溫制冷,磁約束需要較為龐大的設備,而實現設備小型化也需要材料等基礎科學的進步,這些方面的進步又依賴于物理理論的進步(比如建立于原子尺度研究和量子力學基礎上的電子計算機的發明和量子計算機概念的提出 帶動了對于晶體管和光量子材料的工藝研究)。可能是基于以上的原因,大劉認為托卡馬克不適于承擔帶領人類走入聚變時代的重任(笑)。言歸正傳:
托卡馬克,又稱“環磁機”,俄語原文“Токамак”,是一種利用磁約束來實現磁約束聚變的環形容器,最早由位于蘇聯莫斯科庫爾恰托夫研究所(NRC KI)的物理學家伊戈爾·塔姆、安德烈·薩哈羅夫和列夫·阿齊莫維齊等人在1950年代發明。
根據百度百科的描述,托卡馬克的中央是一個環形的真空室,外面纏繞著線圈(如下面動圖)。通電時,托卡馬克的內部會產生巨大的螺旋型磁場,將其中的等離子體加熱到很高的溫度,以達到核聚變的目的:
 圖注:托卡馬卡裝置維基百科介紹,托卡馬克是當前用于生產受控熱核核聚變能中研究最深入的磁約束裝置類型。磁場被用于約束是因為等離子體冷卻會使反應停止,而超導托卡馬克可長時間約束等離子體。世界上第一個超導托卡馬克為俄制的T-7(托卡馬克7號):
圖注:托卡馬卡裝置維基百科介紹,托卡馬克是當前用于生產受控熱核核聚變能中研究最深入的磁約束裝置類型。磁場被用于約束是因為等離子體冷卻會使反應停止,而超導托卡馬克可長時間約束等離子體。世界上第一個超導托卡馬克為俄制的T-7(托卡馬克7號): 聽起來是不是很玄乎?一個更直白的例子是,2019年,新聞上報道中國耗資千億的“人造太陽”,就是可控托卡馬克裝置:
聽起來是不是很玄乎?一個更直白的例子是,2019年,新聞上報道中國耗資千億的“人造太陽”,就是可控托卡馬克裝置:
AI+可控核聚變的前世事實上,早在AlphaGo擊敗人類世界的圍棋冠軍李世石后,就有網友在知乎上提問:據說AlphaGo是從零開始自學,運用了深度神經網絡與蒙特卡洛樹狀搜索相結合的技術,那么是否能讓AlphaGo從零開始學習可控核聚變裝置建造技術呢?
 鏈接:https://www.zhihu.com/question/41295369/answer/142572075底下有網友@劉亞問回答,高溫等離子體高自由能與約束的問題是托卡馬克技術的主要難點,深度學習網絡可能有助于解決這些問題,但難點在于:托卡馬克裝置在目前的約束技術條件下,難以小型化裝置造價,以及氘消耗、等離子體加溫等其它方面運行的成本,使實驗裝置的數量、運行次數均受限,難以支持盲目的反復運行實驗涉及高溫等離子體,目前約束技術條件下重復反復運行有安全性問題缺乏獲取大樣本的條件綜上所述,深度學習技術不一定適合解決托卡馬克可控核聚變裝置。相比托卡馬克,另一類核聚變裝置——反場箍縮裝置(Reversedfieldpinch,RFP)更適合用深度學習進行研究,因為:“其內外兩套磁場方向相反的磁體合成的特殊磁場,可以穩定等離子體的邊緣,體積相對小、運行成本相對低、安全性相對高。”
鏈接:https://www.zhihu.com/question/41295369/answer/142572075底下有網友@劉亞問回答,高溫等離子體高自由能與約束的問題是托卡馬克技術的主要難點,深度學習網絡可能有助于解決這些問題,但難點在于:托卡馬克裝置在目前的約束技術條件下,難以小型化裝置造價,以及氘消耗、等離子體加溫等其它方面運行的成本,使實驗裝置的數量、運行次數均受限,難以支持盲目的反復運行實驗涉及高溫等離子體,目前約束技術條件下重復反復運行有安全性問題缺乏獲取大樣本的條件綜上所述,深度學習技術不一定適合解決托卡馬克可控核聚變裝置。相比托卡馬克,另一類核聚變裝置——反場箍縮裝置(Reversedfieldpinch,RFP)更適合用深度學習進行研究,因為:“其內外兩套磁場方向相反的磁體合成的特殊磁場,可以穩定等離子體的邊緣,體積相對小、運行成本相對低、安全性相對高。”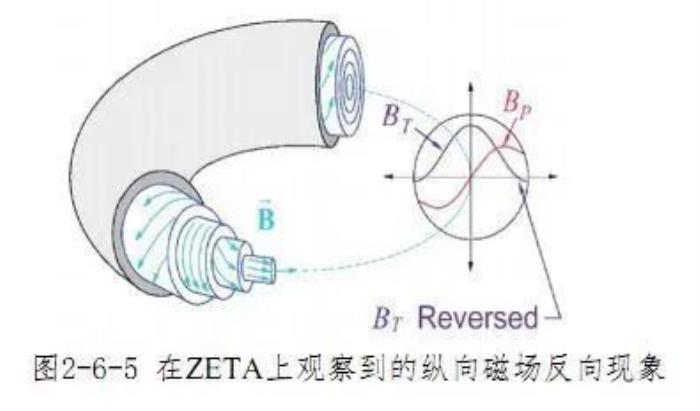 他還分享了資料,稱機器學習的研究者從上世紀90年代末就開始將機器學習方法用于反場箍縮研究穩定等離子體的邊緣的反饋控制:Barana O, Manduchi G, Serri A, et al. A neural network approach for the detection of the locking position in RFX[C]// Fusion Engineering, 1999. Symposium on. IEEE, 1999:575-578.Olofsson K E J. Nonaxisymmetric experimental modal analysis and control of resistive wall MHD in RFPs : System identification and feedback control for the reversed-field pinch[J]. Fusion Plasma Physics, 2012.除了以上研究,從2014年起,谷歌就和核聚變公司TAETechnology進行合作,將機器學習應用于不同類型的聚變反應堆,以加速試驗數據的分析;此外英國中部歐洲環面JET聯合設施也在利用人工智能來預測等離子體的行為。隨著核聚變反應堆規模的增大,托卡馬克設備越來越復雜,對于可靠性和準確性控制的要求也在不斷提高,人工智能在其中將起到越來越關鍵的作用。
他還分享了資料,稱機器學習的研究者從上世紀90年代末就開始將機器學習方法用于反場箍縮研究穩定等離子體的邊緣的反饋控制:Barana O, Manduchi G, Serri A, et al. A neural network approach for the detection of the locking position in RFX[C]// Fusion Engineering, 1999. Symposium on. IEEE, 1999:575-578.Olofsson K E J. Nonaxisymmetric experimental modal analysis and control of resistive wall MHD in RFPs : System identification and feedback control for the reversed-field pinch[J]. Fusion Plasma Physics, 2012.除了以上研究,從2014年起,谷歌就和核聚變公司TAETechnology進行合作,將機器學習應用于不同類型的聚變反應堆,以加速試驗數據的分析;此外英國中部歐洲環面JET聯合設施也在利用人工智能來預測等離子體的行為。隨著核聚變反應堆規模的增大,托卡馬克設備越來越復雜,對于可靠性和準確性控制的要求也在不斷提高,人工智能在其中將起到越來越關鍵的作用。DeepMind如何做?2月16日,DeepMind與EPFL合作研究的深度強化學習系統助力可控核聚變的工作在Nature上發布:
 鏈接:https://www.nature.com/articles/s41586-021-04301-9那么,他們是如何用深度強化學習實現在托卡馬克裝置內保持核聚變等離子體穩定的呢?托卡馬克裝置研究的一個主要方向是將等離子體的分布構建成不同配置的效果,以優化穩定性、封閉性和能量排放,并為第一個燃燒等離子體實驗ITER提供通知。而要在托卡馬克內限制每個配置,需要設計一個反饋控制器,通過精確控制幾個與等離子體磁耦合的線圈來操縱磁場,以達到理想的等離子體電流、位置和形狀。這個問題也就是著名的“托卡馬克磁控制問題”。在傳統方法中,要解決這個時變的、非線性的、多變量的控制問題,首先要解決一個反問題,即:預先計算一組前饋線圈電流和電壓,然后設計一組獨立的、單輸入、單輸出的PID控制器,使等離子體保持垂直位置,并控制徑向位置和等離子體電流,所有這些控制器在設計時也要注意不能相互干擾。大多數控制結構都會增加對等離子體形狀的外部控制回路,這就需要對等離子體平衡進行實時估計,以調制前饋線圈電流。控制器的設計建立在線性化模型動力學的基礎之上,需要進行增益調度以跟蹤時間變化的控制目標。盡管這些控制器在大多數情況下表現不錯,但每當目標等離子體配置發生變化,就需要花費大量的工程努力、設計努力和專業知識,同時還要進行復雜的平衡估計實時計算。這時,深度強化學習就派上了用場:強化學習可以作為一種全新的方法,用來設計非線性反饋控制器,可以直觀地設置性能目標,將重點轉移到“應該實現什么”,而不是“如何實現”。此外,強化學習技術極大簡化了控制系統,計算成本低的控制器取代了嵌套的控制結構,而內部化的狀態重建消除了對獨立平衡重建的要求。一句話:這些優勢可減少控制器的開發周期,加速對替代性等離子體配置的研究。在這個工作中,他們提出了一個由強化學習設計的磁性控制器,可以自主學習指揮全套的控制線圈,既可以實現高水平控制,也能滿足物理和操作的約束條件,在生產等離子體配置時大大減少了設計的工作量。
鏈接:https://www.nature.com/articles/s41586-021-04301-9那么,他們是如何用深度強化學習實現在托卡馬克裝置內保持核聚變等離子體穩定的呢?托卡馬克裝置研究的一個主要方向是將等離子體的分布構建成不同配置的效果,以優化穩定性、封閉性和能量排放,并為第一個燃燒等離子體實驗ITER提供通知。而要在托卡馬克內限制每個配置,需要設計一個反饋控制器,通過精確控制幾個與等離子體磁耦合的線圈來操縱磁場,以達到理想的等離子體電流、位置和形狀。這個問題也就是著名的“托卡馬克磁控制問題”。在傳統方法中,要解決這個時變的、非線性的、多變量的控制問題,首先要解決一個反問題,即:預先計算一組前饋線圈電流和電壓,然后設計一組獨立的、單輸入、單輸出的PID控制器,使等離子體保持垂直位置,并控制徑向位置和等離子體電流,所有這些控制器在設計時也要注意不能相互干擾。大多數控制結構都會增加對等離子體形狀的外部控制回路,這就需要對等離子體平衡進行實時估計,以調制前饋線圈電流。控制器的設計建立在線性化模型動力學的基礎之上,需要進行增益調度以跟蹤時間變化的控制目標。盡管這些控制器在大多數情況下表現不錯,但每當目標等離子體配置發生變化,就需要花費大量的工程努力、設計努力和專業知識,同時還要進行復雜的平衡估計實時計算。這時,深度強化學習就派上了用場:強化學習可以作為一種全新的方法,用來設計非線性反饋控制器,可以直觀地設置性能目標,將重點轉移到“應該實現什么”,而不是“如何實現”。此外,強化學習技術極大簡化了控制系統,計算成本低的控制器取代了嵌套的控制結構,而內部化的狀態重建消除了對獨立平衡重建的要求。一句話:這些優勢可減少控制器的開發周期,加速對替代性等離子體配置的研究。在這個工作中,他們提出了一個由強化學習設計的磁性控制器,可以自主學習指揮全套的控制線圈,既可以實現高水平控制,也能滿足物理和操作的約束條件,在生產等離子體配置時大大減少了設計的工作量。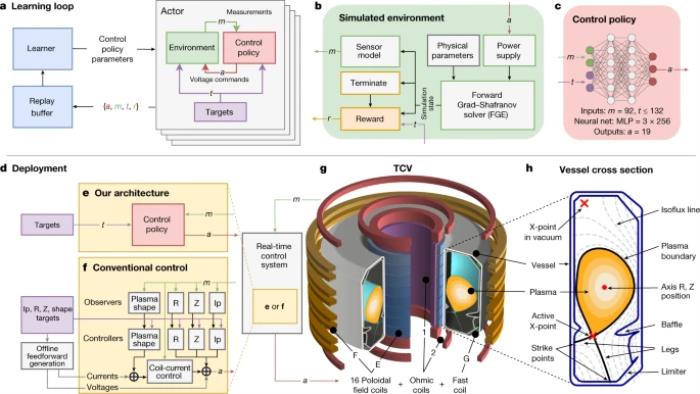
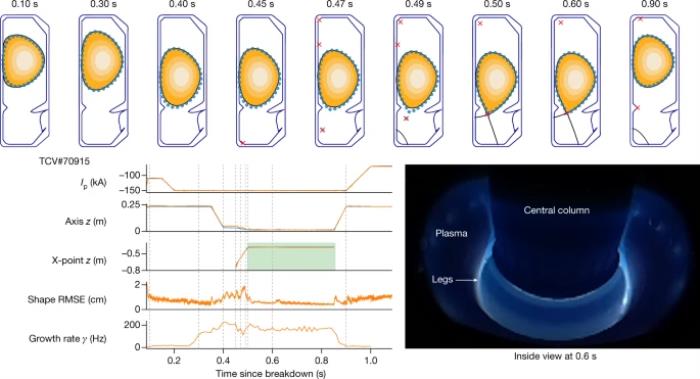 圖注:通過深度強化學習,托卡馬克裝置中的等離子體電流、垂直穩定性、位置和形狀控制情況此外,他們還介紹了TCV上的可持續“雨滴” (droplets’),其中兩個獨立的等離子體可同時保持在容器:
圖注:通過深度強化學習,托卡馬克裝置中的等離子體電流、垂直穩定性、位置和形狀控制情況此外,他們還介紹了TCV上的可持續“雨滴” (droplets’),其中兩個獨立的等離子體可同時保持在容器: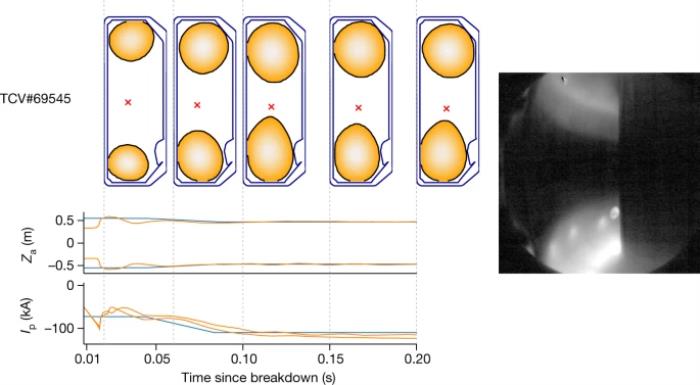 圖注:在 200 毫秒控制窗口中持續控制 TCV 上的兩個獨立“雨滴”
圖注:在 200 毫秒控制窗口中持續控制 TCV 上的兩個獨立“雨滴”寫在最后目前為止,在可控核聚變上取得的最好成績來自歐洲聯合環狀反應堆(JET),今年的2月9日,JET中的聚變反應在5秒內以中子的形式釋放出總共59兆焦耳的能量——這個數值并不高,大概只能燒開幾十壺開水而已。人類早已實現了輸出能量小于輸入能量的可控核聚變,以JET創下的世界紀錄為例,其Q值(聚變能增益系數,輸出能量與輸入能量之比)約為0.33左右。要實現真正可用的核聚變清潔能源,需要通過新的范式的研究,不斷提高核聚變的Q值。DeepMind 團隊堅信:他們的深度強化學習系統為托卡馬克裝置中的等離子體磁約束提供了一個新的范式。更重要的是,他們的控制設計表明了基于機器學習的控制方法的優勢。要實現AI+核聚變,需要科學與工程的雙管齊下,硬件與算法缺一不可。他們相信,深度強化學習框架有可能塑造未來的核聚變研究與托卡馬克裝置的研究發展。大家怎么看?參考鏈接:1.https://www.zhihu.com/question/31056640/answer/568168722.https://scitechdaily.com/science-made-simple-what-is-a-tokamak/3.https://www.zhihu.com/question/41295369/answer/142572075


相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
