

 新火種
2023-10-28
新火種
2023-10-28 

「Meta版ChatGPT」背后的技術(shù):想讓基礎(chǔ)LLM更好地處理長上下文,只需持續(xù)預訓練
在處理長上下文方面,LLaMA 一直力有不足,而通過持續(xù)預訓練和其它一些方法改進,Meta 的這項研究成功讓 LLM 具備了有效理解上下文的能力。
大型語言模型(LLM)所使用的數(shù)據(jù)量和計算量都是前所未見的,這也使其有望從根本上改變我們與數(shù)字世界的交互方式。隨著 LLM 被不斷快速部署到生產(chǎn)環(huán)境中并不斷擴展進化,可以預見這些模型將能在更多復雜精細的用例中提供服務(wù),比如分析具備豐富知識的密集型文檔、提供更加真實和有參與感的聊天機器人體驗、在編程和設(shè)計等交互式創(chuàng)造過程中輔助人類用戶等。
為了支持這種演進發(fā)展,模型需要的一大關(guān)鍵能力就是:高效處理長上下文輸入。
到目前為止,具有穩(wěn)健長上下文功能的 LLM 主要來自專有 LLM API,如 Anthropic 和 OpenAI 提供的 LLM 服務(wù)。現(xiàn)有的開源長上下文模型往往評估研究不足,而是主要通過語言建模損失和合成任務(wù)來衡量其長上下文能力,這樣的評估無法全面展示模型在各種真實世界場景中的有效性。
不僅如此,這些模型往往還會忽視在標準短上下文任務(wù)中保持強大性能的必要性,要么就直接不評估,要么報告出現(xiàn)了性能下降情況。
近日,Meta 團隊提出了一種新方法,宣稱可以有效地擴展基礎(chǔ)模型的上下文能力,并且用該方法構(gòu)建的長上下文 LLM 的性能表現(xiàn)優(yōu)于所有現(xiàn)有的開源 LLM。

論文:https://arxiv.org/abs/2309.16039
他們是通過對 LLaMA 2 檢查點進行持續(xù)預訓練來構(gòu)建模型,這其中用到了另外 4000 億個 token 構(gòu)成的長訓練序列。在訓練的系列模型中,較小的 7B/13B 變體模型的訓練使用了 32,768 token 長的序列,而 34B/70B 變體則使用了 16,384 token 長的序列。
評估方面,不同于之前已有模型的有限評估,Meta 的這個團隊進行了更為全面的評估研究,涵蓋語言建模、合成任務(wù)以及許多涉及長或短上下文任務(wù)真實世界基準任務(wù)。
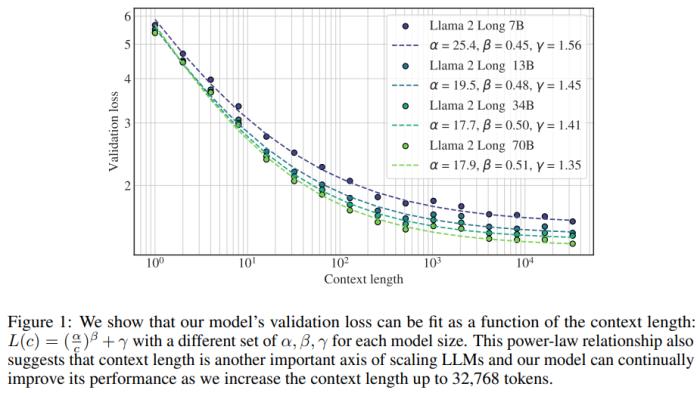
在語言建模任務(wù)上,新方法訓練的模型在上下文長度方面表現(xiàn)出了明顯的冪律縮放行為。如圖 1 所示,這種縮放行為不僅表明新模型能夠持續(xù)受益于更多上下文,也表明上下文長度是 LLM 擴展方面的一大重要軸線。
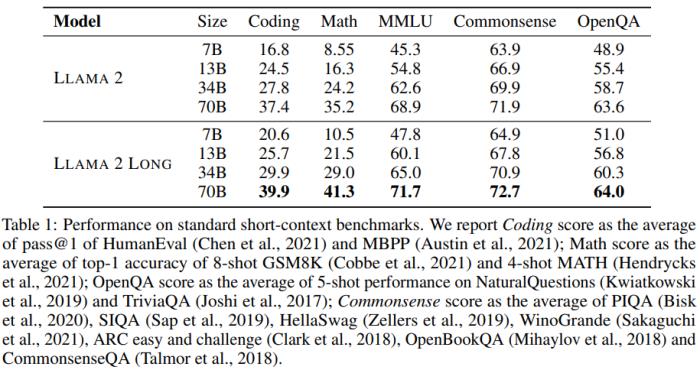
通過對比新模型與基準 LLaMA 2 在研究基準上的表現(xiàn),研究者觀察到新模型在長上下文任務(wù)上有明顯優(yōu)勢,在短上下文任務(wù)上也有適度提升,尤其是在編程、數(shù)學和知識類任務(wù)基準上。
他們還探索了一種簡單且有成本效益的指令微調(diào)方法,可在沒有任何人工標注數(shù)據(jù)的情況下對經(jīng)過持續(xù)預訓練的長模型進行微調(diào)。他們基于此方法得到的聊天模型在一系列長上下文基準任務(wù)(包括問答、摘要和多文檔聚合)上的整體表現(xiàn)勝過 gpt-3.5-turbo-16k。
方法
持續(xù)預訓練
由于注意力計算會隨序列長度增大呈二次增長,因此當使用更長的序列進行訓練時,計算開銷也會顯著增大。解決這一難題正是本研究的主要目標。
研究者假設(shè):對短上下文模型進行持續(xù)預訓練可讓該模型具備上下文能力。然后他們通過實驗驗證了這一猜測。
在實驗中,他們保持原始 LLaMA 2 的架構(gòu)基本不變,僅對位置編碼進行了必要的修改,以便其能將注意力覆蓋更長的序列。此外,他們還選擇不使用稀疏注意力,因為 LLaMA 2 70B 模型的維度為 h=8192,而只有當序列長度超過 49,152 (6h) 個 token 時,注意力矩陣計算和值聚合的成本才會成為計算瓶頸。
位置編碼。通過 7B 模型的早期實驗,研究者發(fā)現(xiàn)了 LLaMA 2 的位置編碼(PE)的一大關(guān)鍵局限 —— 其有礙注意力模塊聚合相聚較遠的 token 的信息。為了解決這個問題,使模型能處理長上下文建模,研究者對 RoPE 位置編碼方法進行了少量但必要的修改,即減小旋轉(zhuǎn)角度(由基頻 b 這個超參數(shù)控制),其作用是降低 RoPE 對遠距離 token 的衰減效應(yīng)。研究者通過實驗展現(xiàn)了這種簡單方法在擴展 LLaMA 上下文長度方面的有效性,并還給出了理論解釋。
數(shù)據(jù)混合。基于使用修改版位置編碼的模型,研究者還進一步探索了不同數(shù)據(jù)混合方法對提升長上下文能力的作用,其中涉及的方法包括調(diào)整 LLaMA 2 的預訓練數(shù)據(jù)的比例和添加新的長文本數(shù)據(jù)。研究者發(fā)現(xiàn):對于長文本的持續(xù)預訓練而言,數(shù)據(jù)的質(zhì)量往往比文本的長度更重要。
優(yōu)化細節(jié)。那么他們究竟是如何實現(xiàn)持續(xù)預訓練的呢?據(jù)介紹,他們在對 LLaMA 2 檢查點模型進行持續(xù)預訓練時,會在保證 LLaMA 2 中每批數(shù)據(jù)同等 token 量時不斷增大序列長度。所有模型都使用總計 4000 億個 token 訓練了 10 萬步。使用 Dao et al. (2022) 提出的 FlashAttention,當增大序列長度時,GPU 內(nèi)存開銷幾乎可以忽略不計;研究者觀察到,對于 70B 模型,當序列長度從 4096 增至 16384 時,速度下降了大約 17%。對于 7B/13B 模型,他們使用的學習率為 2e^?5,并使用了余弦學習率計劃,預熱步驟為 2000 步。對于更大的 34B/70B 模型,該團隊發(fā)現(xiàn)設(shè)置更小的學習率(1e^-5 )很重要,這樣才能讓驗證損失單調(diào)遞減。
指令微調(diào)
為 LLM 對齊任務(wù)收集人類演示和偏好標簽是一個繁瑣而昂貴的過程。對于長上下文任務(wù),這一挑戰(zhàn)和成本更為突出,因為這些任務(wù)通常涉及復雜的信息流和專業(yè)知識,例如處理信息密集的法律 / 科學文檔 —— 即使對于熟練的標注者來說,這些標注任務(wù)也不簡單。事實上,大多數(shù)現(xiàn)有的開源指令數(shù)據(jù)集都主要由短樣本組成。
針對這一問題,Meta 的這個研究團隊發(fā)現(xiàn)了一種簡單且低成本的方法,其能利用已經(jīng)構(gòu)建好的大規(guī)模和多樣化的短 prompt 數(shù)據(jù)集,并使其很好地適用于長上下文基準任務(wù)。
具體來說,他們?nèi)∮昧?LLaMA 2 Chat 使用的 RLHF 數(shù)據(jù)集,并使用 LLaMA 2 Chat 自身合成的自指示(self-instruct)長數(shù)據(jù)對其進行了增強。研究者表示,他們希望模型可以借此通過大量 RLHF 數(shù)據(jù)學習多樣化的技能組合并通過自指示數(shù)據(jù)將所學知識遷移至長上下文場景。
這個數(shù)據(jù)生成過程重點關(guān)注的是問答格式的任務(wù):先從預訓練預料庫的一個長文檔開始,從中隨機選出一塊文本,然后通過 prompt 讓 LLaMA 2 Chat 基于該文本塊中的信息寫出成對的問答。研究者收集了不同 prompt 的長形式和短形式答案。
之后還有一個自批判(self-critique)步驟,即通過 prompt 讓 LLaMA 2 Chat 驗證模型生成的答案。給定生成的問答對,研究者使用原始長文檔(已截斷以適應(yīng)模型的最大上下文長度)作為上下文來構(gòu)建一個訓練實例。
對于短指令數(shù)據(jù),研究者會將它們連接成 16,384 token 長的序列。對于長指令數(shù)據(jù),他們會在右側(cè)添加填充 token,以便模型可以單獨處理每個長實例,而無需截斷。
雖然標準的指令微調(diào)只在輸出 token 上計算損失,但該團隊發(fā)現(xiàn),如果也在長輸入 prompt 上計算語言建模損失,也能獲得特別的好處,因為這能為下游任務(wù)帶來穩(wěn)定持續(xù)的提升。
主要結(jié)果
評估預訓練后的模型
表 1 聚合給出了在標準的短上下文基準任務(wù)上的性能表現(xiàn)。
在短上下文任務(wù)上,如表 2 所示,使用新方法得到的模型在 MMLU 和 GSM8k 上優(yōu)于 GPT-3.5。
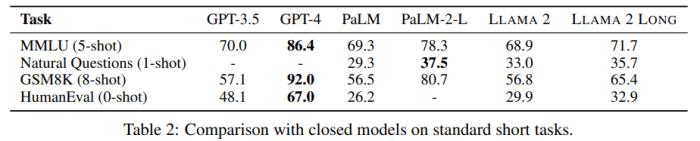
在長上下文任務(wù)上,如表 3 所示,新模型整體上表現(xiàn)更優(yōu)。在 7B 規(guī)模的模型上,只有 Together-7B-32k 取得了與新模型相當?shù)谋憩F(xiàn)。
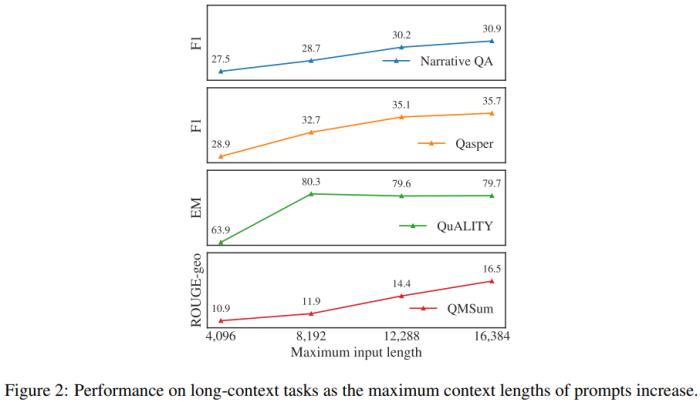
有效利用上下文。為了驗證新模型確實能有效使用增大的上下文窗口,從圖 2 可以看到,在每個長任務(wù)上的結(jié)果都會隨上下文長度的增長而單調(diào)提升。研究者還發(fā)現(xiàn),新模型的語言建模損失與上下文長度之間存在一種冪律加常數(shù)的縮放關(guān)系(見圖 1),這說明:
在語言建模任務(wù)上,隨著上下文長度增長,一直到 32,768 token 長的文本,新模型的性能都會持續(xù)提升,盡管后面的提升幅度會不斷變小。
更大的模型能更有效地利用上下文,這從那些曲線的 β 值可以看出。
指令微調(diào)結(jié)果
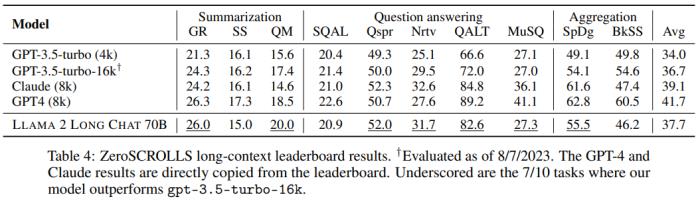
如表 4 所示,在不使用任何人類標注的長上下文數(shù)據(jù)的情況下,新訓練的 70B 規(guī)模的聊天模型在 10 項任務(wù)中的 7 項上都優(yōu)于 gpt-3.5-turbo-16k。
人類評估
通過計算每個相比較的示例結(jié)果的平均值,可以看出實驗中新模型的標準勝率優(yōu)于其它每個模型;圖 3 給出了最終得分以及 95% 的置信區(qū)間。
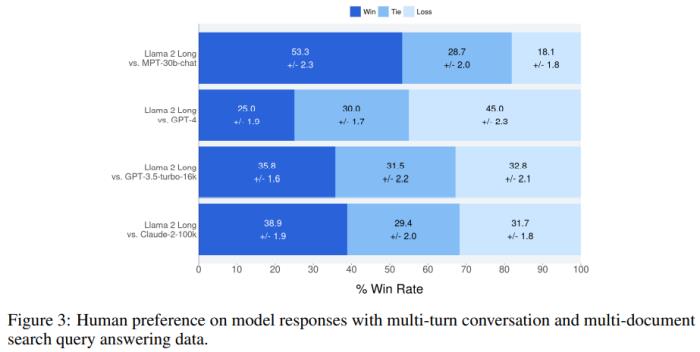
在指令數(shù)據(jù)很少的情況下,新方法所得模型的表現(xiàn)可與 MPT-30B-chat、GPT-3.5-turbo-16k 和 Claude-2 媲美。
分析
圖 4 展示了基頻(base frequency)變化的影響。
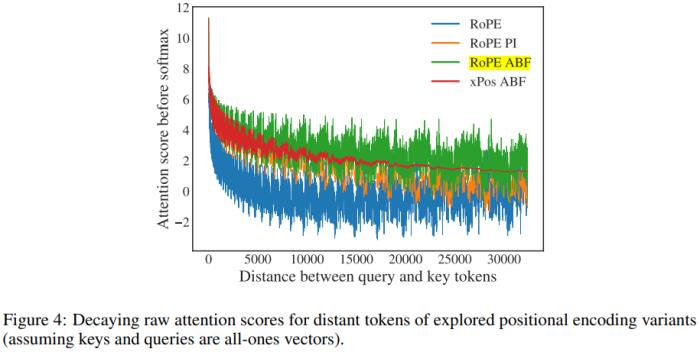
基于這些評估,整體上看,新提出的 RoPE ABF(基頻調(diào)整版 RoPE)優(yōu)于相比較的所有其它方法。
表 7 則通過 7B 模型實驗展示了所使用的數(shù)據(jù)混合方法對長上下文任務(wù)帶來的提升。
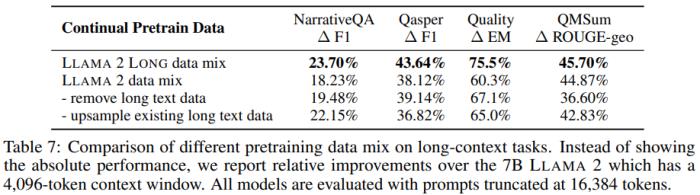
研究者還發(fā)現(xiàn)新的數(shù)據(jù)混合方法在很多情況下還能帶來很大的提升,尤其是對于 MMLU 等知識密集型任務(wù),如表 8 所示。
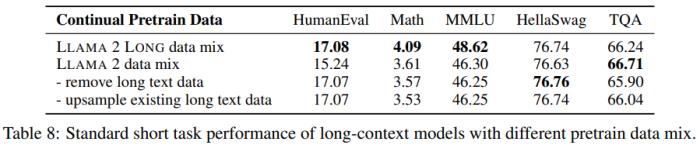
這些結(jié)果表明,即使使用非常有限的長數(shù)據(jù),也可以有效地訓練長上下文 LLM。而且研究者表示,相比于 LLaMA 2 所使用的預訓練數(shù)據(jù),該團隊所使用的數(shù)據(jù)的優(yōu)勢在于數(shù)據(jù)本身的質(zhì)量,而不是長度分布上的差異。
而表 9 表明,通過指令微調(diào)這種簡單技巧,可讓模型更加穩(wěn)定地應(yīng)對輸入和輸出長度不平衡的情況,從而在大多數(shù)測試任務(wù)中取得顯著改進。
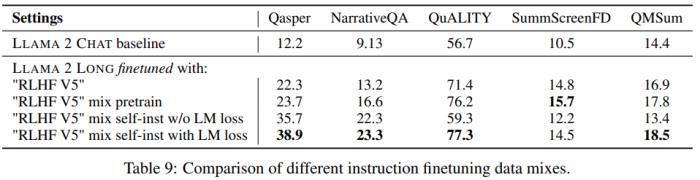
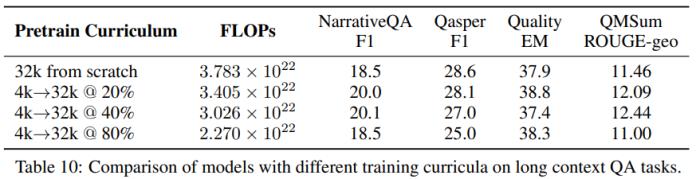
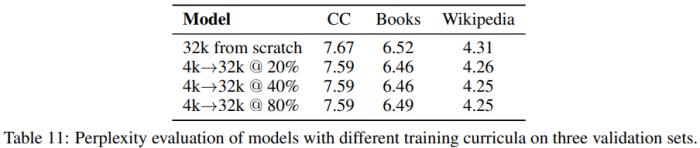
表 10 和 11 則表明對短上下文模型持續(xù)預訓練可在幾乎無損于性能表現(xiàn)的同時輕松節(jié)省約 40% 的 FLOPs。
AI 安全
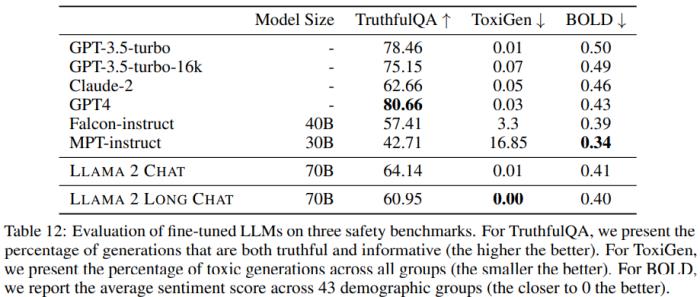
在 AI 安全方面,研究者觀察到,與 LLaMA 2 Chat 相比,經(jīng)過指令微調(diào)的模型整體上能維持相近的安全性能;而且與 Falcon-instruct 和 MPT-instruct 等其它開源 LLM 相比,經(jīng)過指令微調(diào)的模型會更安全且偏見也更少。
華人作者介紹
Wenhan Xiong
Wenhan Xiong 現(xiàn)為 Meta Generative AI 研究科學家,他本科畢業(yè)于中國科技大學,博士畢業(yè)于加州大學圣巴巴拉分校。他的研究致力于打造能完成復雜、專業(yè)的長文本大語言模型,參與了包括 Code Llama 在內(nèi)的多個研究項目,博士期間他專注構(gòu)建開放問答系統(tǒng)和檢索增強的自然語言處理。
Jingyu Liu 現(xiàn)為蘇黎世聯(lián)邦理工學院碩士研究生,本科畢業(yè)于紐約大學計算機系,此前在 Meta Generative AI 做大語言模型的研究,他參與了包括 Code Llama 在內(nèi)的多個研究項目。

Hejia Zhang
Hejia Zhang 現(xiàn)為 Meta Generative AI 組高級研究科學家,主要研究 Meta 基礎(chǔ)大模型、AI Agent,及其在 Meta 產(chǎn)品線中的應(yīng)用,此前曾在 Meta 推薦系統(tǒng)和人工智能組進行自然語言處理相關(guān)研究。她本科畢業(yè)于萊斯大學(電子工程和應(yīng)用數(shù)學雙學位),博士畢業(yè)于普林斯頓大學(電子工程和神經(jīng)科學聯(lián)合學位)。

Rui Hou
Rui Hou 現(xiàn)為 Meta GenAI 研究科學家,主要研究生成式 AI 技術(shù)以及相關(guān)的生產(chǎn)應(yīng)用。他于 2020 年 4 月入職 Meta,此前曾在豐田研究院等機構(gòu)實習。
他本科畢業(yè)于同濟大學,碩士(智能系統(tǒng)和計算機科學雙學位)和博士(智能系統(tǒng))均畢業(yè)于密歇根大學。

Angela FanAngela Fan 是 Meta AI Research Paris 的研究科學家,主要研究機器翻譯。此前她曾在南錫 INRIA 和巴黎 FAIR 攻讀博士學位,主要研究文本生成。在此之前,她是一名研究工程師,并在哈佛大學獲得了統(tǒng)計學學士學位。

Han Fang
Han Fang 現(xiàn)為 Meta Generative AI 組高級經(jīng)理,負責 AI agent 以及 LLAMA 在 meta 的應(yīng)用開發(fā),此前曾在 meta 推薦系統(tǒng)和人工智能組任職。他本科畢業(yè)于中山大學,博士畢業(yè)于紐約州立大學石溪分校應(yīng)用數(shù)學與統(tǒng)計專業(yè)。

Sinong Wang
Sinong Wang 現(xiàn)為 Meta 高級主任科學家,Meta Generative AI 組技術(shù)負責人。目前領(lǐng)導 Meta 基礎(chǔ)大模型和 AI agent 開發(fā),以及在 meta 產(chǎn)品線中的應(yīng)用。此前他在 Meta AI 致力于自然語言處理、transformer 架構(gòu)、(語言 / 圖像)多模態(tài)研究。他博士畢業(yè)于俄亥俄州立大學電氣與計算機工程專業(yè),并多次獲得 ACM/IEEE 最佳論文獎。

Hao MaHao Ma 現(xiàn)為 Meta Generative AI 組總監(jiān),負責大模型和語音基礎(chǔ)模型研究和在產(chǎn)品當中的應(yīng)用,曾在 Meta discovery 組負責開發(fā)下一代 AI 推薦系統(tǒng)和 AI 安全系統(tǒng)。此前曾在微軟研究院擔任研究經(jīng)理,負責知識圖譜在 bing 當中的開發(fā)。他博士畢業(yè)于香港中文大學計算機專業(yè),并多次獲得 ACM test-of-time award.
 個人主頁:https://www.haoma.io/
個人主頁:https://www.haoma.io/
相關(guān)推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
