

 新火種
2023-10-28
新火種
2023-10-28 


專注E2E語(yǔ)音識(shí)別,騰訊AILab開(kāi)源語(yǔ)音處理工具包PIKA
機(jī)器之心報(bào)道
作者:魔王、杜偉
PyTorch + Kaldi,騰訊 AI Lab 開(kāi)源輕量級(jí)語(yǔ)音處理工具包 PIKA,專注于端到端語(yǔ)音識(shí)別任務(wù)。
Kaldi 是一個(gè)開(kāi)源的語(yǔ)音識(shí)別系統(tǒng),由 Daniel Povey 主導(dǎo)開(kāi)發(fā),在很多語(yǔ)音識(shí)別測(cè)試和應(yīng)用中廣泛使用。但它依賴大量腳本語(yǔ)言,且核心算法是用 C++ 編寫(xiě)的,對(duì)聲學(xué)模型的更新和代碼調(diào)試帶來(lái)一定難度。
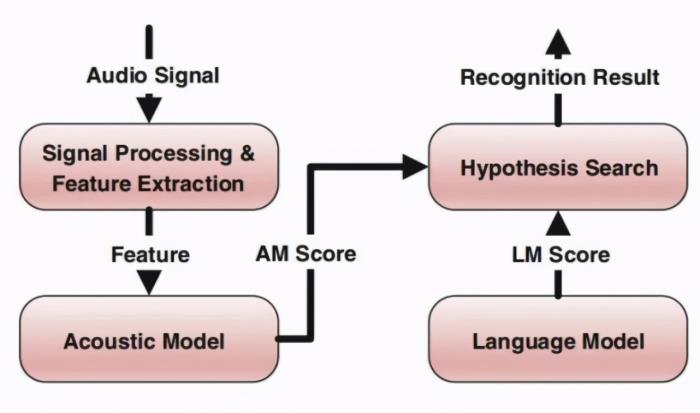
語(yǔ)音識(shí)別系統(tǒng)架構(gòu)
「Kaldi 之父」Daniel Povey 表示正在打造下一代 Kaldi。去年夏天在 WAIC 開(kāi)發(fā)者日上,Daniel 分享了他對(duì)下一代 Kaldi 的期望,希望能夠基于 PyTorch 甚至 TensorFlow 構(gòu)建語(yǔ)義識(shí)別模型。
學(xué)術(shù)界和業(yè)界也都在努力改進(jìn)語(yǔ)音識(shí)別流程,加快技術(shù)迭代。此前,Yoshua Bengio 團(tuán)隊(duì)成員 Mirco Ravanelli 等人開(kāi)發(fā)了一個(gè)新型開(kāi)源框架——PyTorch-Kaldi,試圖繼承 Kaldi 的效率和 PyTorch 的靈活性,彌補(bǔ) PyTorch 和 Kaldi 之間的鴻溝:在 PyTorch 中實(shí)現(xiàn)聲學(xué)模型,在 Kaldi 中執(zhí)行特征提取、標(biāo)簽 / 對(duì)齊計(jì)算和解碼。
近日,騰訊 AI Lab 開(kāi)源了一個(gè)基于 PyTorch 和 (Py)Kaldi 的輕量級(jí)語(yǔ)音處理工具包 PIKA。PIKA 首個(gè)版本專注于端到端語(yǔ)音識(shí)別,開(kāi)發(fā)團(tuán)隊(duì)以 PyTorch 作為深度學(xué)習(xí)引擎,使用 Kaldi 進(jìn)行數(shù)據(jù)格式化和特征提取。

項(xiàng)目地址:https://github.com/tencent-ailab/pika
具體而言,PIKA 具備以下特征:
即時(shí)數(shù)據(jù)增強(qiáng)和特征加載器;
TDNN Transformer 編碼器,以及基于卷積和 Transformer 的解碼器結(jié)構(gòu);
RNNT 訓(xùn)練和批解碼;
利用 Ngram FST 的 RNNT 解碼(即時(shí)重評(píng)分、aka 和 shallow fusion);
RNNT 最小貝葉斯風(fēng)險(xiǎn)(MBR)訓(xùn)練;
用于 RNNT 的 LAS 前向與后向重評(píng)分器;
基于高效 BMUF(塊模型更新過(guò)濾)的分布式訓(xùn)練。
安裝和依賴
PIKA 開(kāi)發(fā)團(tuán)隊(duì)推薦使用 Anaconda,因?yàn)樗蠖鄶?shù)的依賴項(xiàng)。其他主要依賴如下:
PyTorch
用戶可前往 PyTorch 官網(wǎng)自行安裝,代碼和腳本應(yīng)能夠在 PyTtorch 0.4.0 及以上版本運(yùn)行。但為了確保與 RNNT 損失模塊兼容,PIKA 開(kāi)發(fā)團(tuán)隊(duì)推薦使用 PyTorch 1.0.0 以上版本。
Pykaldi 和 Kaldi
開(kāi)發(fā)團(tuán)隊(duì)使用 Kaldi 和 PyKaldi(Kaldi 的 python 包裝器)進(jìn)行數(shù)據(jù)處理、特征提取和 FST 操作。用戶可前往 Pykaldi 網(wǎng)站自行安裝,為提升效率請(qǐng)確保使用 ninja 構(gòu)建 Pykaldi。完成所有 pykaldi 安裝流程后,Kaldi 和 Pykaldi 依賴項(xiàng)即準(zhǔn)備完成。
CUDA-Warp RNN-Transducer
對(duì)于 RNNT 損失模塊,開(kāi)發(fā)者采用了 warp-rnnt(https://github.com/1ytic/warp-rnnt)項(xiàng)目中的 pytorch 綁定。
使用方法
在使用 PIKA 之前,我們需要先檢查 egs 目錄中的所有訓(xùn)練和解碼腳本。
數(shù)據(jù)準(zhǔn)備和 RNNT 訓(xùn)練
egs/train_transducer_bmuf_otfaug.sh 包括數(shù)據(jù)準(zhǔn)備和 RNNT 訓(xùn)練。用戶需要準(zhǔn)備訓(xùn)練數(shù)據(jù)并指定訓(xùn)練數(shù)據(jù)目錄:
繼續(xù) MBR 訓(xùn)練
有了 RNNT 訓(xùn)練模型后,用戶可以使用 egs/train_transducer_mbr_bmuf_otfaug.sh 繼續(xù) MBR 訓(xùn)練(假設(shè)使用的訓(xùn)練數(shù)據(jù)相同,則可以省略數(shù)據(jù)準(zhǔn)備步驟)。用戶需要確保指定初始模型:
訓(xùn)練 LAS 前向與后向重評(píng)分器
用戶可以利用 egs/train_las_rescorer_bmuf_otfaug.sh 為 RNNT 模型訓(xùn)練 LAS 前向與后向重評(píng)分器。LAS 重評(píng)分器將與 RNNT 模型共享編碼器部分,并使用兩層 LSTM 作為額外的編碼器。用戶需要確保指定編碼器共享:
該工具還支持雙向 LAS 重評(píng)分,即前向與后向重評(píng)分。后向重評(píng)分(自右至左)通過(guò)訓(xùn)練 LAS 模型時(shí)反轉(zhuǎn)序列標(biāo)簽來(lái)實(shí)現(xiàn)。通過(guò)以下代碼,用戶可以輕松執(zhí)行 LAS 后向重評(píng)分訓(xùn)練:
解碼
egs/eval_transducer.sh 是主要的評(píng)估腳本,包含解碼 pipeline。指定以下兩個(gè)模型可以實(shí)現(xiàn) LAS 前向與后向重評(píng)分:
PIKA 工具包中的所有訓(xùn)練和解碼超參數(shù)都基于大規(guī)模訓(xùn)練和內(nèi)部評(píng)估數(shù)據(jù)。用戶可能需要調(diào)參以獲得最優(yōu)性能。此外,WER (CER) 評(píng)分腳本基于中文普通話任務(wù),處理不同語(yǔ)言的用戶可以重寫(xiě)評(píng)分腳本。
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢(qián)損失負(fù)任何責(zé)任。
