

 新火種
2025-05-20
新火種
2025-05-20 


“起大早趕晚集”的谷歌大模型,這次真的“遙遙領(lǐng)先”了?
最早推出Transformer架構(gòu)的谷歌,一度在大模型競(jìng)賽中落后。好在隨著Gemini的不斷進(jìn)化,谷歌正在回到第一梯隊(duì)。
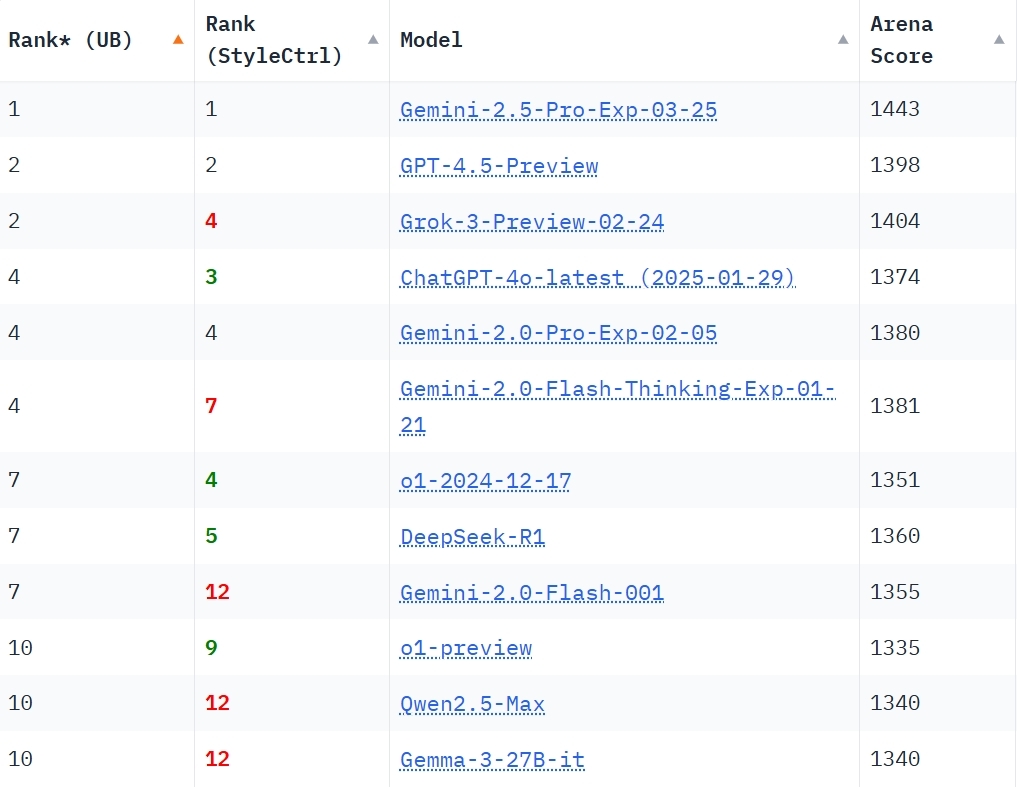
3月26日,Gemini 2.5 Pro上線,這個(gè)模型一經(jīng)推出就登頂各大榜單,在Chatbot Arena上較第二名高出整整39分!
Gemini 2.5 Pro是一款推理模型。谷歌表示,推理能力不僅僅指分類和預(yù)測(cè),而是指系統(tǒng)分析信息、得出邏輯結(jié)論、融入上下文和細(xì)微差別,以及做出明智決策的能力。
據(jù)悉Gemini 2.5 Pro 目前支持 100 萬 token 的上下文窗口,很快將推出200萬token的上下文窗口,繼承并發(fā)揚(yáng)了 Gemini 模型的優(yōu)勢(shì)——原生多模態(tài)能力和超長上下文長度。
這讓它能夠理解海量數(shù)據(jù)集,并處理來自多種信息源的復(fù)雜問題,包括文本、音頻、圖像、視頻,甚至完整的代碼倉庫。
在Chatbot Arena(由加州大學(xué)伯克利分校 SkyLab 和 LMSYS 的研究者開發(fā),主要用于根據(jù)人類偏好評(píng)估大語言模型的性能)上,Gemini 2.5 Pro以橫掃所有類別的顯著優(yōu)勢(shì)排名第一,并且比緊隨其后的Grok-3整整高出了39分。
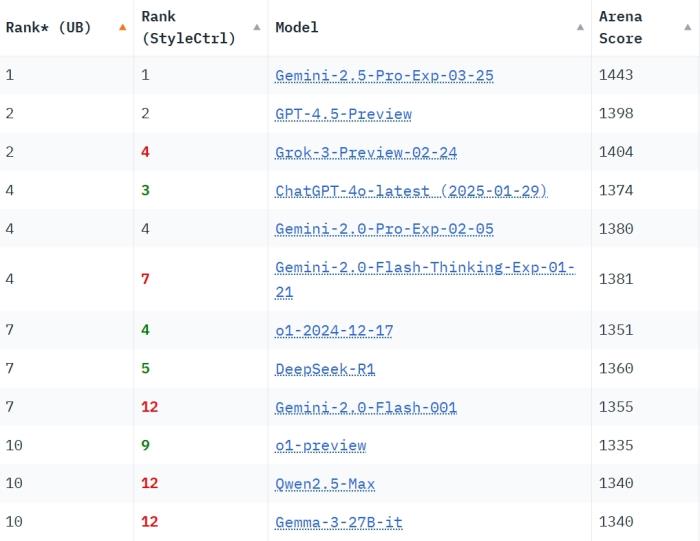
同時(shí)Gemini 2.5 Pro還獲得了創(chuàng)意寫作、指令遵循和長查詢?nèi)箢I(lǐng)域唯一的冠軍。
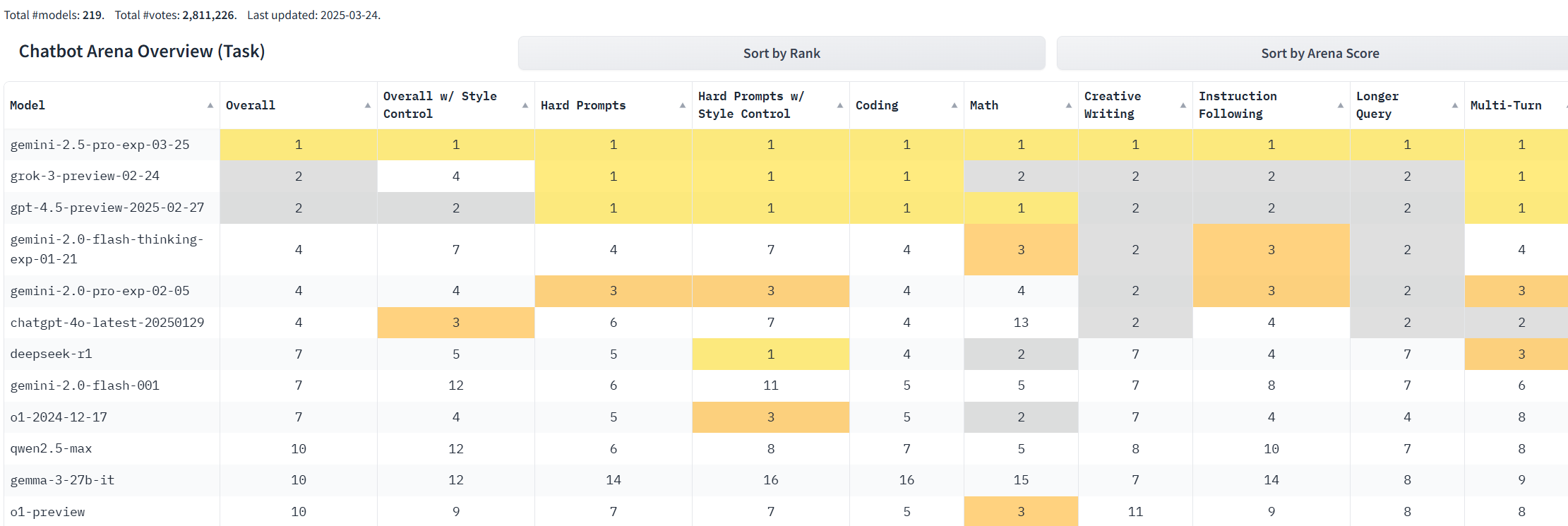
此外,Gemini 2.5 Pro成功登頂了視覺競(jìng)技場(chǎng)(Vision Arena)排行榜榜首。
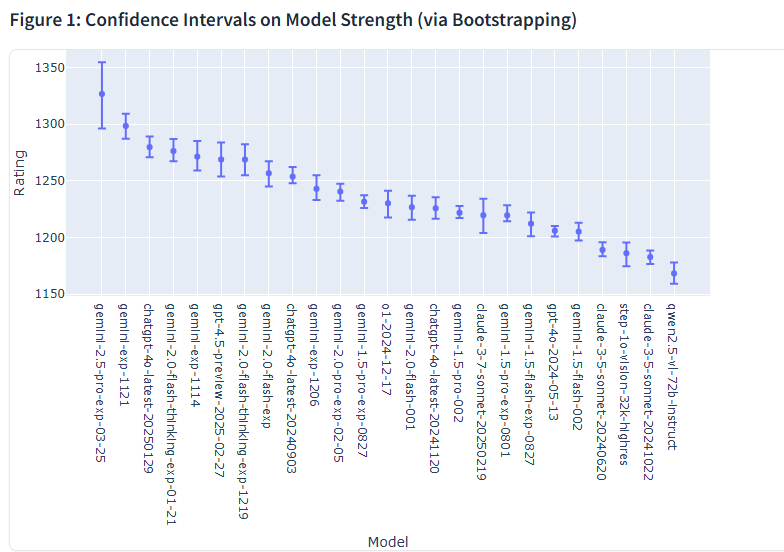
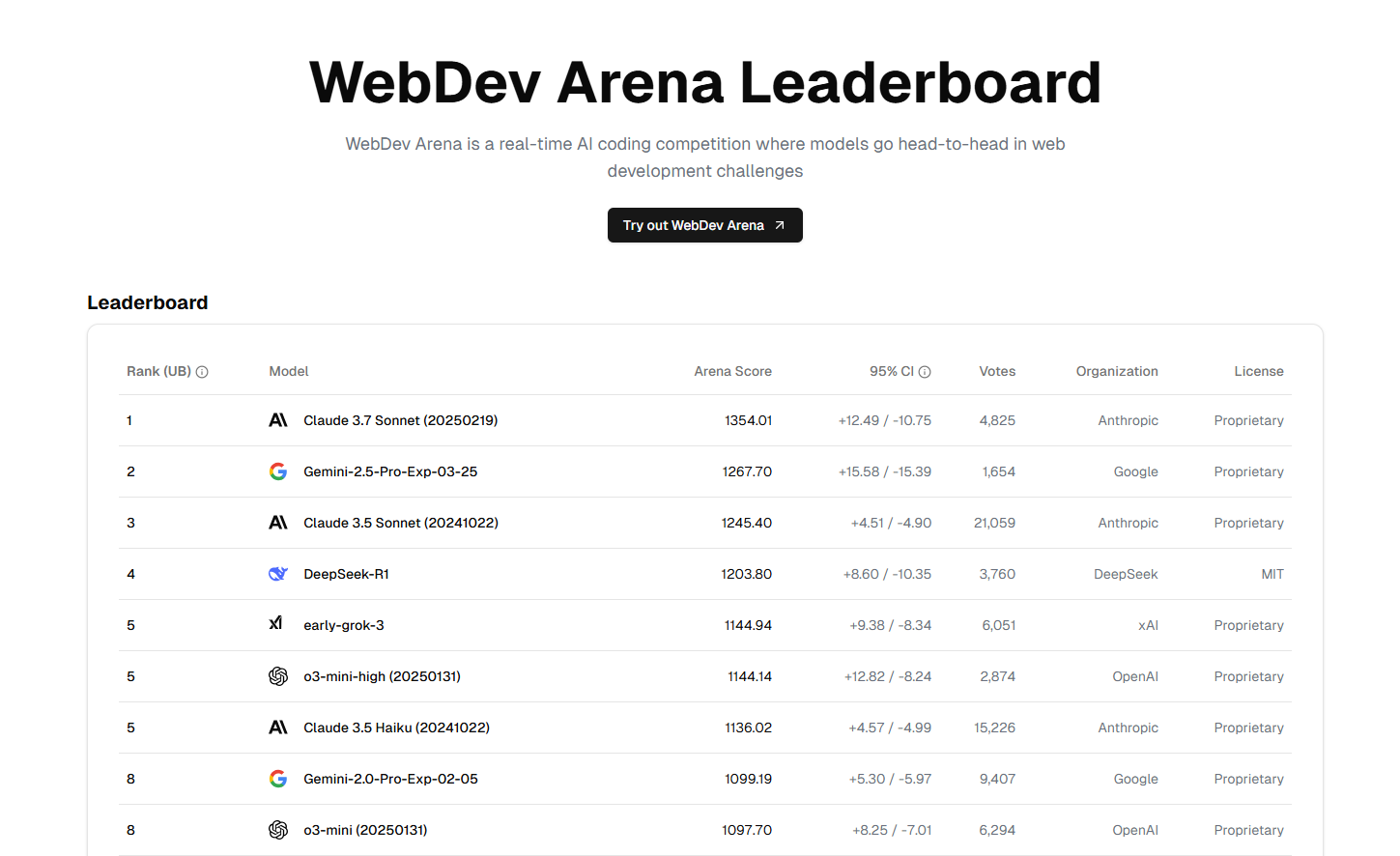
在網(wǎng)頁開發(fā)領(lǐng)域,作為首個(gè)實(shí)力媲美 Claude 3.7 Sonnet 的模型,Gemini 2.5 Pro成功獲得了網(wǎng)頁開發(fā)競(jìng)技場(chǎng)(WebDev Arena)的第二名。
不僅如此,Gemini 2.5 Pro在Humanity’s Last Exam(no tools),GPQA和 AIME 2025等數(shù)學(xué)和科學(xué)基準(zhǔn)評(píng)測(cè)中同樣表現(xiàn)卓越。
Humanity’s Last Exam (no tools)即 “人類的最后考試(無工具)”,這里的 “無工具” 指在進(jìn)行該考試時(shí),不允許使用外部工具,如搜索引擎、數(shù)據(jù)庫等。已往實(shí)驗(yàn)顯示,最先進(jìn)的 LLMs 在 HLE 上的準(zhǔn)確率普遍低于 10%,且存在信心與能力失衡、推理效率低等問題,表明當(dāng)前 LLM 的能力與人類專家在封閉式學(xué)術(shù)問題上的前沿能力之間的差距。在這一背景下,Gemini 2.5 Pro 18.8%的成績顯得非常突出。

據(jù)悉,Gemini 2.5 Pro 已在 Google AI Studio 和 Gemini 應(yīng)用中,向 Gemini Advanced 用戶開放,并將在 Vertex AI 上推出。
而它會(huì)在未來幾周內(nèi)公布定價(jià)方案,用戶可以在更高使用配額下,將模型應(yīng)用于大規(guī)模生產(chǎn)環(huán)境。
有意思的是,最近國內(nèi)和國外兩大著名的“起大早趕晚集”選手都發(fā)布了最新大模型,含金量是否都能達(dá)到評(píng)測(cè)顯示的效果呢?
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
