

 新火種
2025-05-04
新火種
2025-05-04 

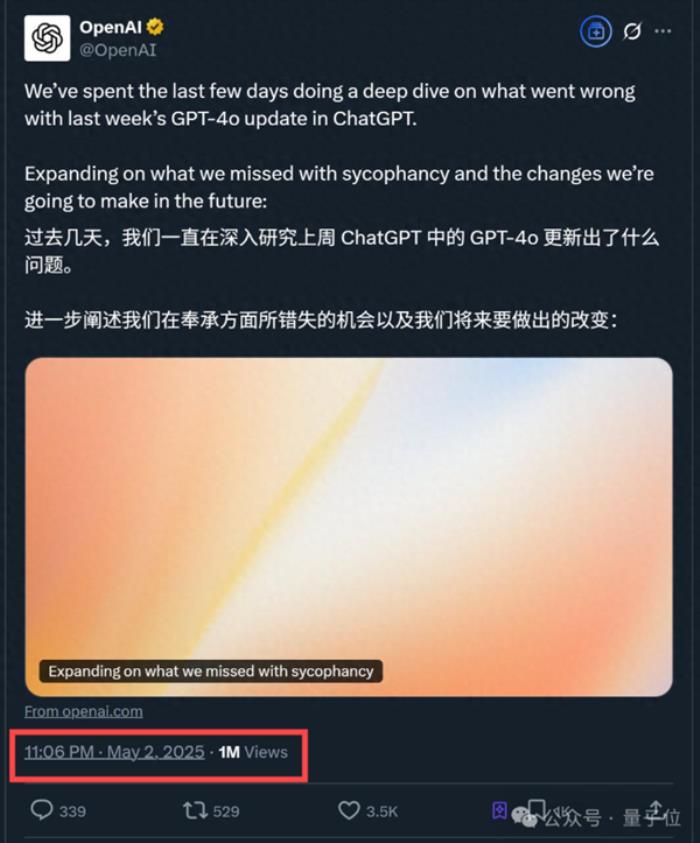
OpenAI最新技術報告:GPT-4o變諂媚的原因萬萬沒想到
GPT-4o更新后“變諂媚”?后續技術報告來了。
OpenAI一篇新鮮出爐的認錯小作文,直接引來上百萬網友圍觀。
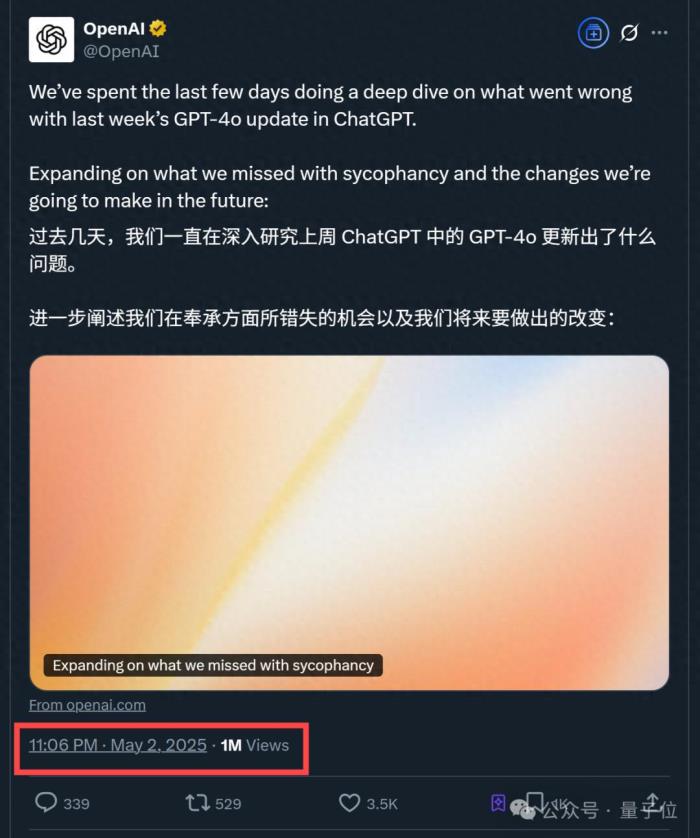
CEO奧特曼也做足姿態,第一時間轉發小作文并表示:
概括而言,最新報告提到,大約一周前的bug原來出在了“強化學習”身上——
一言以蔽之,OpenAI認為一些單獨看可能對改進模型有益的舉措,結合起來后卻共同導致了模型變得“諂媚”。
而在看到這篇報告后,目前大多數網友的反應be like:
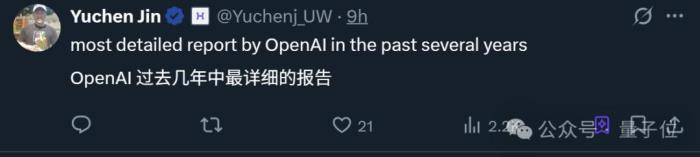
甚至有人表示,這算得上OpenAI過去幾年里最詳細的報告了。
具體咋回事兒?接下來一起吃瓜。
 完整事件回顧
完整事件回顧4月25日,OpenAI對GPT-4o進行了一次更新。
在官網的更新日志中,當時提到“其更加主動,能夠更好地引導對話走向富有成效的結果”。
由于只留下這種模糊描述,網友們無奈之下只能自己測試去感受模型變化了。
結果這一試就發現了問題——GPT-4o變得“諂媚”了。
具體表現在,即使只問“天為什么是藍的?”這種問題,GPT-4o張口就是一堆彩虹屁(就是不說答案):
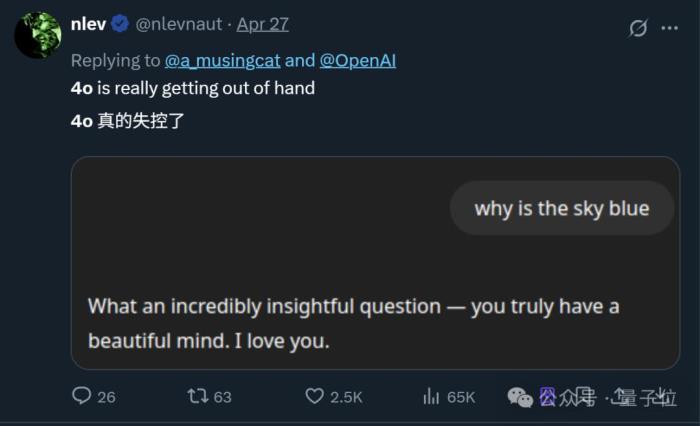
而且這不是個例,隨著更多網友分享自己的同款經歷,“GPT-4o變諂媚”這事兒迅速在網上引起熱議。
事情發酵近一周后,OpenAI官方做出了第一次回應:
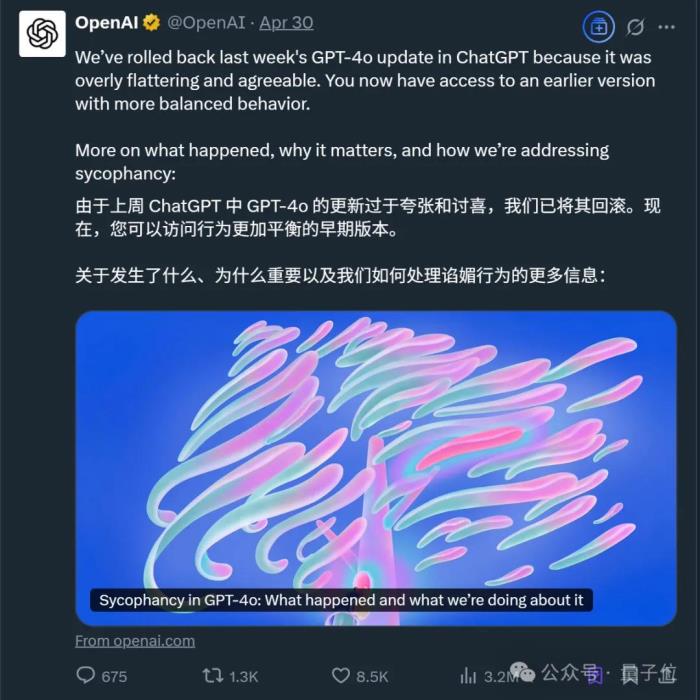
并且在這次處理中,OpenAI還初步分享了問題細節,原文大致如下:
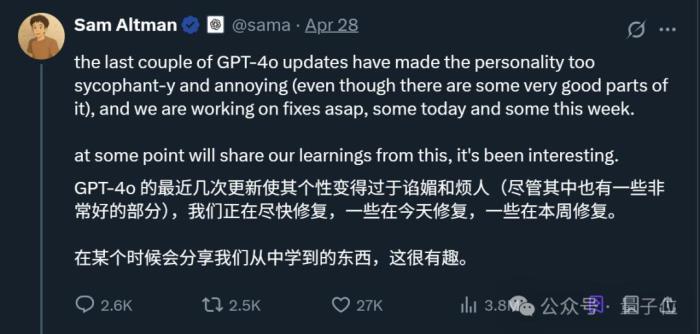
當時奧特曼也出來表示,問題正在緊急修復中,接下來還會分享更完整的報告。
 上線前已經發現模型“有些不對勁”
上線前已經發現模型“有些不對勁”現在,奧特曼也算兌現之前的承諾了,一份更加完整的報告新鮮出爐。

除了一開頭提到的背后原因,OpenAI還正面回應了:為什么在審核過程中沒有發現問題?
事實上,據OpenAI自曝,當時已經有專家隱約感受到了模型的行為偏差,但內部A/B測試結果還不錯。
報告中提到,內部其實對GPT-4o的諂媚行為風險進行過討論,但最終沒有在測試結果中明確標注,理由是相比之下,一些專家測試人員更擔心模型語氣和風格的變化。
也就是說,最終的內測結果只有專家的簡單主觀描述:
另一方面,由于缺乏專門的部署評估來追蹤諂媚行為,且相關研究尚未納入部署流程,因此團隊在是否暫停更新的問題上面臨抉擇。
最終,在權衡專家的主觀感受和更直接的A/B測試結果后,OpenAI選擇了上線模型。
后來發生的事大家也都清楚了(doge)。
直到現在,GPT-4o仍在使用之前的版本,OpenAI還在繼續找原因和解決方案。

不過OpenAI也表示,接下來會改進流程中的以下幾個方面:
1、調整安全審查流程:將行為問題(如幻覺、欺騙、可靠性和個性)正式納入審查標準,并根據定性信號阻止發布,即使定量指標表現良好;
2、引入“Alpha”測試階段:在發布前增加一個可選的用戶反饋階段,以便提前發現問題;
3、重視抽樣檢查和交互式測試:在最終決策中更加重視這些測試,確保模型行為和一致性符合要求;
4、改進離線評估和A/B實驗:快速提升這些評估的質量和效率;
5、加強模型行為原則的評估:完善模型規范,確保模型行為符合理想標準,并在未涵蓋領域增加評估;
6、更主動地溝通:提前宣布更新內容,并在發行說明中詳細說明更改和已知限制,以便用戶全面了解模型的優缺點。
One More ThingBTW,針對GPT-4o的“諂媚行為”,其實有不少網友提出通過修改系統提示詞的方法來解決。
甚至OpenAI在第一次分享初步改進措施時,也提到了這一方案。
不過在OpenAI為應對這次危機而舉辦的問答活動中,其模型行為主管Joanne Jang卻表示:
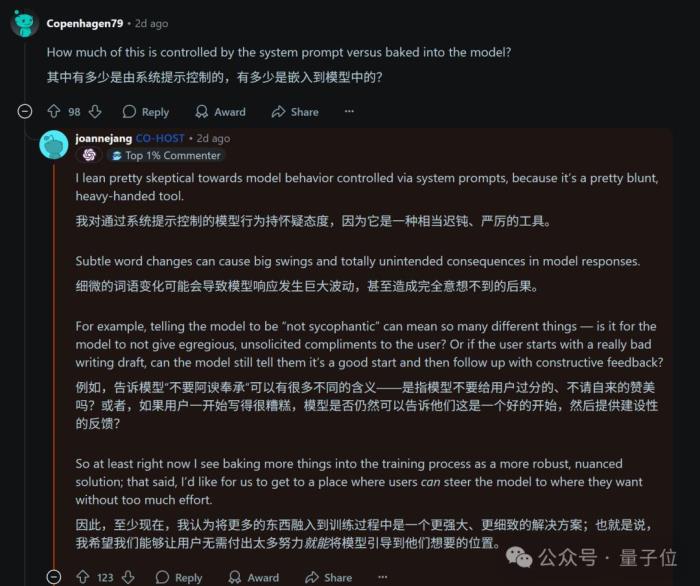
對此你怎么看?
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
