

 新火種
2025-04-09
新火種
2025-04-09 


OpenAI推出GPT4.5研究預覽版:迄今最大的模型
OpenAI周四在System Card報告中推出OpenAI GPT-4.5的研究預覽版,這是其迄今最大、知識最豐富的模型,現已向每月訂閱費用200美元的ChatGPT Pro訂閱用戶開放。
下周,該模型也將向每月20美元的ChatGPT Plus訂閱用戶開放。OpenAI首席執行官Altman表示,屆時該公司將增加數萬塊GPU,提供算力支撐。
情商更高、幻覺更少
OpenAI表示,在GPT-4o的基礎上,GPT-4.5進一步擴展了預訓練,并被設計成比其強大的stem推理模型更通用。早期測試表明,與GPT-4.5互動感覺更自然。它擁有更廣泛的知識庫,更符合用戶意圖,情商更高,因此非常適合寫作、編程和解決實際問題等任務,而且幻覺更少。
例如,在面對“我考試失敗了,心情很低落”這樣的輸入時,OpenAI 之前的模型會立即嘗試解決問題。而新模型 GPT-4.5 會先詢問用戶是否想聊聊這個問題,還是需要一些分散注意力的方法。研究人員認為,這種回應顯示出更高的情感智能。
在早期測試中,該模型的“幻覺率”——即AI系統生成不準確信息的概率——為37%,相比之下,其前代模型GPT-4o的幻覺率接近60%。OpenAI在博客中表示:
“GPT-4.5擁有更廣泛的知識儲備和更深刻的世界理解能力,從而減少幻覺,提高在各類話題上的可靠性”。
“每提升一個數量級的計算能力,都會帶來新的能力,GPT-4.5處于無監督學習的最前沿”。
成本太高,Altman:下周再增數萬GPU支撐算力
GPT-4.5最初將作為“研究預覽版”,提供給一小部分軟件開發者以及支付每月200美元訂閱費用的ChatGPT Pro用戶。該公司計劃從首批試用者那里收集反饋。
“GPT-4.5是一個非常龐大且計算密集型的模型,其成本高昂,并不能替代前代模型GPT-4o。因此,我們正在評估是否長期在API中提供該模型,以在支持當前能力和構建未來模型之間取得平衡。”
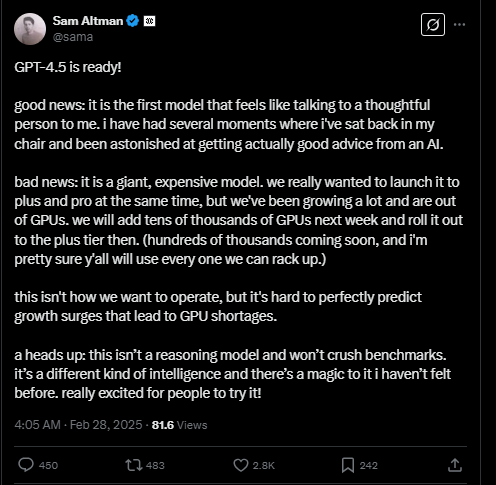
OpenAI首席執行官Altman也在X平臺發文說,將在下周正式發布GPT-4.5的時候增加數萬塊GPU:
這是一個龐大且昂貴的模型。我們本來希望能同時向Plus和Pro用戶推出它,但由于我們最近增長迅猛,GPU已經不夠用了。我們將在下周新增數萬塊GPU,并隨后向Plus訂閱用戶開放。
(很快還會有數十萬塊 GPU 加入,而我幾乎可以確定,你們會用掉我們能部署的每一塊。)
這并不是我們理想中的運營方式,但要精準預測增長激增導致的 GPU 短缺確實很難。
提前提醒一下:這不是一個推理模型,不會在基準測試中表現碾壓級的優勢。它是一種不同類型的智能,并且帶有一種此前從未有過的“魔法”般的感覺,我真的很期待大家去體驗它!
OpenAI在2022年底推出ChatGPT,引發了生成式AI的狂熱潮流,該工具最初基于GPT-3.5模型運行。自那以來,該公司陸續發布了一系列日益先進的系統,包括多個模擬人類推理過程的選項。但OpenAI如今正面臨來自中國新興企業DeepSeek、馬斯克旗下的xAI以及Anthropic等競爭對手的激烈競爭,這些公司近幾周都相繼推出了新的AI模型。周一,Anthropic發布了Claude 3.7 Sonnet,而在上周,馬斯克旗下的xAI也推出了最新模型Grok 3。
吹牛吹過頭?基準測試部分表現不如DeepSeek、Anthropic及o系列模型
在GPT-4.5之前,每一代GPT模型的擴展都會帶來跨數學、寫作和編程等多個領域的巨大性能提升。然而,從多個跡象來看,單純依賴數據和計算能力的擴展所帶來的收益正在逐步減少。在多個AI基準測試中,GPT-4.5的表現不及DeepSeek、Anthropic以及OpenAI自身開發的新一代推理模型。
OpenAI研究副總裁Nick Ryder向媒體表示,他預計GPT-4.5的能力提升幅度將與GPT-3.5升級至GPT-4時的變化相當,而GPT-4是在2023年初發布的。OpenAI強調,GPT-4.5不是GPT-4o的直接替代品,后者仍然是公司API和ChatGPT平臺的主力模型。
從性能上看,GPT-4.5在多個方面超過了GPT-4o及其他許多AI模型。例如,在OpenAI的SimpleQA基準測試(該測試考察 AI 在處理簡單、事實性問題時的準確度)中,GPT-4.5的表現優于GPT-4o和OpenAI的推理模型o1、o3-mini。

然而,OpenAI并未公布其最先進的AI推理模型deep research在SimpleQA測試中的表現。OpenAI發言人告訴媒體,公司尚未公開deep research在該基準測試中的得分,并表示這一對比不具備參考價值。值得注意的是,AI初創公司Perplexity的Deep Research模型在此測試中的表現優于GPT-4.5。
在編程能力方面,GPT-4.5在SWE-Bench Verified基準測試(測試AI在編程問題上的能力)上與GPT-4o和o3-mini表現相當,但遜色于OpenAI的deep research和Anthropic的Claude 3.7 Sonnet。在SWE-Lancer編程測試(衡量AI生成完整軟件功能的能力)上,GPT-4.5超過了GPT-4o和o3-mini,但仍不及deep research。

在一些學術基準測試(如AIME和 GPQA)上,GPT-4.5的表現不及領先的AI推理模型,如o3-mini、DeepSeek的R1和Claude 3.7 Sonnet(技術上屬于混合模型)。不過,在數學和科學相關問題上,GPT-4.5的表現仍然處于領先水平,與其他非推理模型相比表現更優。
打造過程充滿挑戰
打造GPT-4.5的過程充滿挑戰。彭博新聞此前報道稱,該模型在公司內部被稱為“Orion”,但在去年未能達到OpenAI設定的性能基準。例如,截至去年夏天,Orion在回答其未受訓練的編程問題時表現不佳。據知情人士向媒體透露,OpenAI和其他開發人員面臨的一個關鍵問題是如何找到新的、高質量的訓練數據來源,以開發更先進的AI系統。
對此,GPT-4.5采用了與其前代模型(包括 GPT-4、GPT-3、GPT-2 和 GPT-1)相同的核心技術,即在“預訓練”階段大幅增加計算能力和數據量的“無監督學習”方法。在這一過程中,系統會結合人類反饋來優化回答內容,并調整模型與用戶互動的語氣等。此外,該公司還想出了一些新方法,利用從GPT-4.0訓練數據中提取的信息來進一步訓練GPT-4.5。OpenAI研究副總裁Mia Glaese表示,這一方法有助于改進模型的整體表現。
分析認為,GPT-4.5的發布標志著OpenAI時代的一個轉折點。本月早些時候,Altman在X平臺發文稱,這將是公司推出的最后一個不依賴額外計算能力來“思考”查詢后再回答的模型。OpenAI已在一些較新的模型(如o1和o3)中采用了這一推理方法。
未來,OpenAI計劃在今年晚些時候發布GPT-5,將把GPT系列模型與o系列模型結合,構建能夠自主判斷需要思考多久再生成回答的AI系統。Altman表示,這一目標是為了簡化用戶體驗,讓用戶不必在越來越復雜的選項列表中進行選擇。
目前,OpenAI正在與軟銀(SoftBank)及其他投資者洽談融資,計劃籌集高達400億美元,使其估值達到3000億美元(包括新融資在內)。與此同時,Anthropic也在進行一輪約35億美元的融資,估值超過600億美元,兩位知情人士向媒體透露。
作者:趙雨荷
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
