

 新火種
2023-09-09
新火種
2023-09-09 


網易云信神經網絡音頻降噪算法:提升瞬態噪聲抑制效果
網易云信音頻實驗室自主研發了一個針對瞬態噪聲的輕量級網絡音頻降噪算法(網易云信 AI 音頻降噪),對于 Non-stationary Noise 和 Transient Noise 都有很好的降噪量,并且控制了語音信號的損傷程度,保證了語音的質量和理解度。

基于信號處理的傳統音頻降噪算法對于 Stationary Noise(平穩噪聲)有比較好的降噪效果。但是對于 Non-stationary Noise(非平穩噪聲),特別是 Transient Noise(突發噪聲)降噪效果較差,而且有些方法對于語音也有較大的損傷。隨著深度學習在 CV(Computer Vision)上的廣泛應用,基于神經網絡的音頻降噪算法大量涌現,這些算法很好的彌補了傳統算法對于 Non-stationary Noise 降噪效果不好的問題,在 Transient Noise 上也有較大的提升。
但是,基于神經網絡的音頻降噪在計算復雜度上存在挑戰。雖然我們生活中的終端設備的計算能力在不斷提升,比如個人筆記本、手機等,但是大模型的深度學習算法,很難在絕大部分設備(特別是不含 GPU 的設備)上運行。目前也有一些開源的、基于神經網絡的低開銷降噪算法[1,2,3],能夠在大部分終端設備上達到實時運行的標準。但是這些算法的運算量對于 RTC(實時通信)的 SDK 依然太大,其原因是 SDK 中包含了大量算法,每個子算法的開銷都必須嚴格把控,才能保證整個 SDK 的運算開銷在一個合理范圍,并且能夠在大部分終端設備上運行。
針對上述挑戰,網易云信音頻實驗室自主研發了一個針對瞬態噪聲的輕量級網絡音頻降噪算法(網易云信 AI 音頻降噪),對于 Non-stationary Noise 和 Transient Noise 都有很好的降噪量,并且控制了語音信號的損傷程度,保證了語音的質量和理解度。與此同時,云信的 AI 音頻降噪將計算開銷控制在一個非常低的量級,達到了和傳統算法接近的計算量,比如 MMSE [4]。目前,網易云信的 AI 音頻降噪已經成功落地在其自研的新一代音視頻技術架構(NERTC)中,在大幅提升降噪效果的同時,也在大多數終端機型上成功應用,包括了大部分中低端機型。
本文介紹的內容,即網易云信音頻實驗室發表于 INTER-NOISE 2021 的《A Neural Network Based Noise Suppression Method for Transient Noise Control with Low-Complexity Computation》一文,本篇文章詳細介紹了在基于深度學習的音頻降噪算法中,如何在低計算開銷的情況下,實現對不同噪聲,包括 Transient Noise 的抑制。
方法
在介紹算法細節之前,我們需要先在數學上來構建一下問題模型。在公式(1)中,x (n) 、s (n) 、和 d (n)分別代表帶噪信號、干凈語音信號和噪聲信號。

帶噪信號x (n)代表麥克風在實際場景中所收集的信號,其中n代表時域采樣點。我們對公式(1)做一個 STFT(短時傅里葉變化)得到(2),

其中
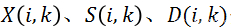
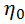

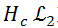
特征表示
為了要實現低計算量的目的,我們需要最大限度的去壓縮模型大小,這樣必然導致在同等狀況下,壓縮后模型的表現會更差。為了彌補模型變小后帶來的效果下降,該研究從輸入特征(Input Feature)入手,選擇更能代表語音特性的特征,從而去區分語音和噪聲。當然特征大小(Feature Size)也需要嚴格控制,共同保證低計算量的要求。現在開源的單通道深度學習降噪算法中,比較普遍的 Feature 是用信號的 Magnitude 和 Phase,或者直接用頻域信號的 Complex Value。這樣的做法好處是可以保證模型能獲得所有的頻域信息,沒有任何信息丟失;但是缺點是這些頻域信息對于語音信號和噪聲信號的分離度不夠,而且輸入的參數量偏大。方法 [1] 中用到了 Pitch Correlation(基音相關性),
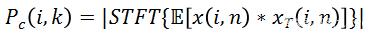
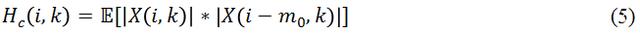
其中
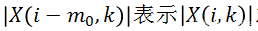
另外一個和
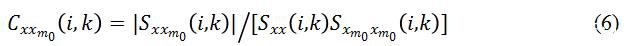
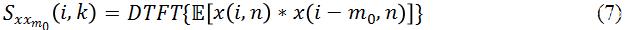
可以看出,Coherence 也可以突出信號中的諧波信息,不同之處在于它也是基于時域的相關性,而且增加了歸一化處理。
損失函數
Valin 在 [1] 中提出了一種損失函數,
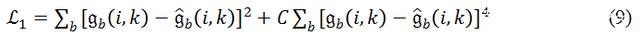
其中
在研究過程中研究發現,雖然
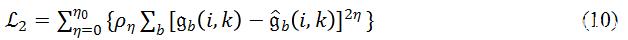
在
學習模型以及實時處理
該研究沿用了 [1] 中 RNN-GRU 模型,原因是 RNN 相比其他學習模型(例如 CNN)攜帶時間信息,可以學習到數據中前后在時序上的聯系。該研究認為這種聯系在語音信號上非常重要,特別是在一個實時的、幀長相對較短的語音算法中。模型的結構如 Fig.1 所示。訓練后的模型會被嵌入網易云信的 SDK 中,通過讀取硬件設備的音頻流,對 Buffer 進行分幀處理并送入 AI 降噪預處理模塊中,預處理模塊會將對應的 Feature 計算出來,并輸出到訓練好的模型中,通過模型計算出對應的 Gain 值,對信號進行調整,最終達到降噪效果(Fig.2)。
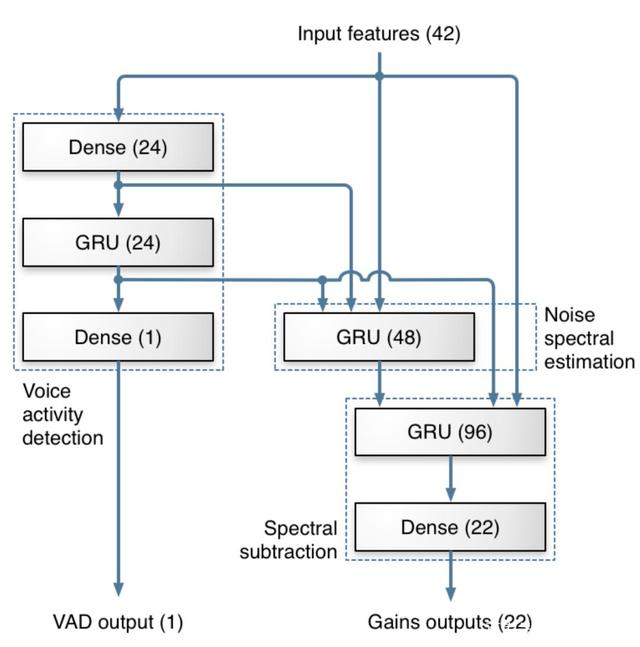
Figure 1: GRU模型。
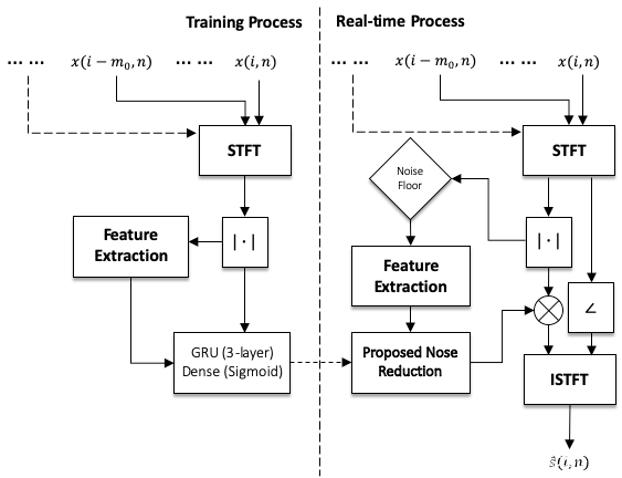
Figure 2: 訓練和實時處理框圖。
測量結果和討論
在測試階段,該研究首先建立了和 Training/Validation 完全不同的一個測試集。在對比項上,選擇了 [4] 作為傳統信號處理的降噪算法代表。在基于深度學習的算法中,研究者首先選擇了 RNNoise[1],以此來評估優化所帶來的效果提升。其次,該研究選擇了 DNS-Net[2]和 DTLN[3]當下兩個熱度很高的實時 AI 降噪算法來作為對比項。
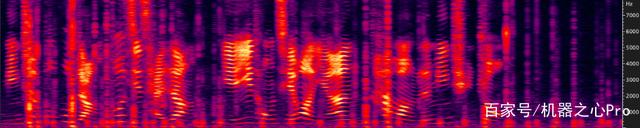
(a)Noisy signal (5dB SNR)


Fig.3 展示了一段 Keyboard Noise 下的降噪前后對比。Keyboard Noise 作為 Transient Noise 中的一種,是在 RTC 場景中非常容易遇到的噪聲。比如在一個在線會議中,會議中的任意一位參會者在用鍵盤記錄會議信息時,都會讓這個會議陷入鍵盤噪聲中。Fig.3 展示的是在 5dB SNR 場景下的情況。從圖中可以看出,網易云信 AI 降噪在非語音部分,對鍵盤噪聲的壓制極大,基本全部消掉;在和語音重合部分,雖然沒有完全消掉,但是也有明顯抑制,并且保護了語音質量。
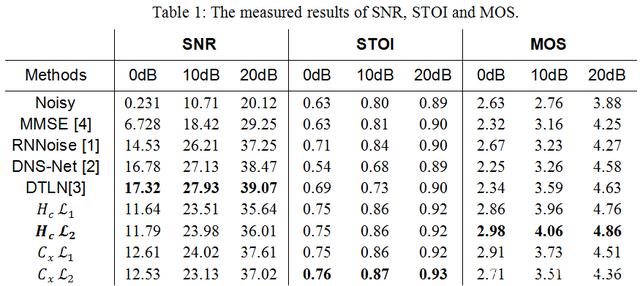
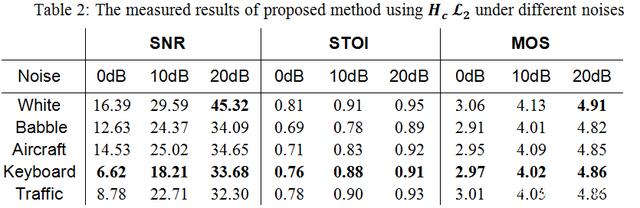
在 RTC 場景中,當降噪后 SNR 達到 20dB 以上,3-4dB 的差值對于聽感來說差異較小。所以該研究在調試中把降噪量穩定在一個范圍內,然后盡量去追求更高的語音理解度(STOI[5])和語音質量(MOS[6])。Table 1 展示了云信 AI 降噪和對比項之間的量化對比。從結果中可以看出,網易云信自研的 Feature 和 Loss Function 在整體上呈現對語音保護更好,降噪量略小。其中,
網易云信的 AI 降噪在 10ms 的音頻幀數據(16kHz 采樣率)中只需要約 400,000 次浮點計算,經過云信自研的 AI 推理框架 NENN 加速,在 iPhone12 上每 10ms 的運算平均時間低于 0.01ms,峰值時間低于 0.02ms,CPU 占比小于 0.02%。
總結
綜上所述,網易云信 AI 降噪實現了一個輕量級的實時神經網絡音頻降噪算法。它在 Stationary 和 Non-Stationary Noise 上都有很好的效果,對于業界的難點 Transient Noise 也有很好的抑制效果;與此同時,相較同類 AI 降噪算法,云信 AI 降噪對語音質量有著更好的保護。
自成立以來,網易云信音頻實驗室除了保障產品的算法研發和優化需求之外,已提交專利數十項。接下來,網易云信音頻實驗室將在基礎算法、模型方面加強研究,結合具體行業和應用場景,以技術創新引領產品創新。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
