

 新火種
2023-09-08
新火種
2023-09-08 


谷歌大腦新研究:單一任務強化學習遇瓶頸?「災難性遺忘」的鍋!
魚羊 發(fā)自 凹非寺量子位 報道 | 公眾號 QbitAI
雅達利游戲,又被推上了強化學習基礎問題研究的舞臺。
來自谷歌大腦的最新研究提出,強化學習雖好,效率卻很低下,這是為啥呢?
——因為AI遭遇了「災難性遺忘」!
所謂災難性遺忘,是機器學習中一種常見的現(xiàn)象。在深度神經(jīng)網(wǎng)絡學習不同任務的時候,相關權重的快速變化會損害先前任務的表現(xiàn)。
而現(xiàn)在,這項圖靈獎得主Bengio參與的研究證明,在街機學習環(huán)境(ALE)的單個任務中,AI也遇到了災難性遺忘的問題。
研究人員還發(fā)現(xiàn),在他們提出的Memento observation中,在原始智能體遭遇瓶頸的時候,換上一只相同架構的智能體接著訓練,就能取得新的突破。
單一游戲中的「災難性干擾」
在街機學習環(huán)境(Arcade Learning Environment,ALE)中,多任務研究通常基于一個假設:一項任務對應一個游戲,多任務學習對應多個游戲或不同的游戲模式。
研究人員對這一假設產(chǎn)生了質(zhì)疑。
單一游戲中,是否存在復合的學習目標?也就是說,是否存在這樣一種干擾,讓AI覺得它既要蹲著又要往前跑?
來自谷歌大腦的研究團隊挑選了「蒙特祖瑪?shù)膹统稹棺鳛檠芯繄鼍啊?/p>
「蒙特祖瑪?shù)膹统稹贡徽J為是雅達利游戲中最難的游戲之一,獎勵稀疏,目標結(jié)構復雜。
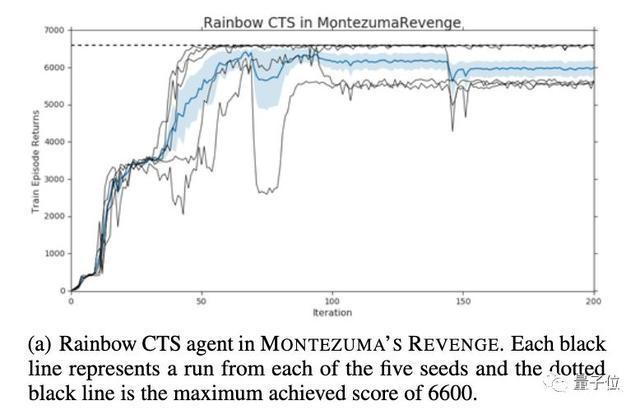
研究人員觀察到,CTS模型計算的Rainbow智能體,會在6600分的時候到達瓶頸。更長時間的訓練和更大的模型大小都不能有所突破。
不過,只需從這個位置開始,換上一只具有相同架構的新智能體,就能突破到8000分的水平。
如此再重置一次,AI的最高分就來到了14500分。
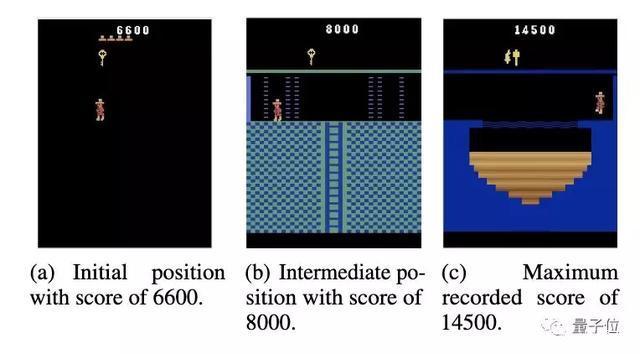
需要說明的是,在換上新智能體的時候,其權重設置與初始的智能體無關,學習進度和權重更新也不會影響到前一個智能體。
研究人員給這種現(xiàn)象起了一個名字,叫Memento observation。
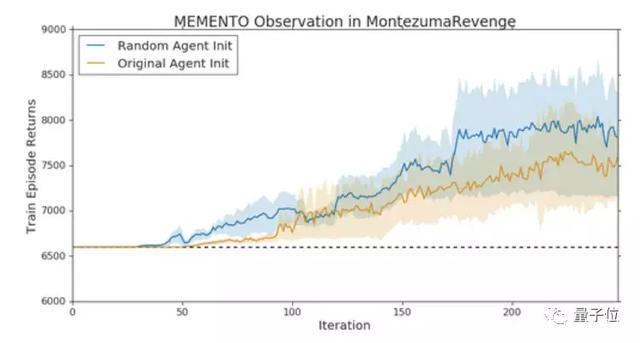
Memento observation表明,探索策略不是限制AI在這個游戲中得分的主要因素。
原因是,智能體無法在不降低第一階段游戲性能的情況下,集成新階段游戲的信息,和在新區(qū)域中學習值函數(shù)。
也就是說,在稀疏獎勵信號環(huán)境中,通過新的獎勵集成的知識,可能會干擾到過去掌握的策略。
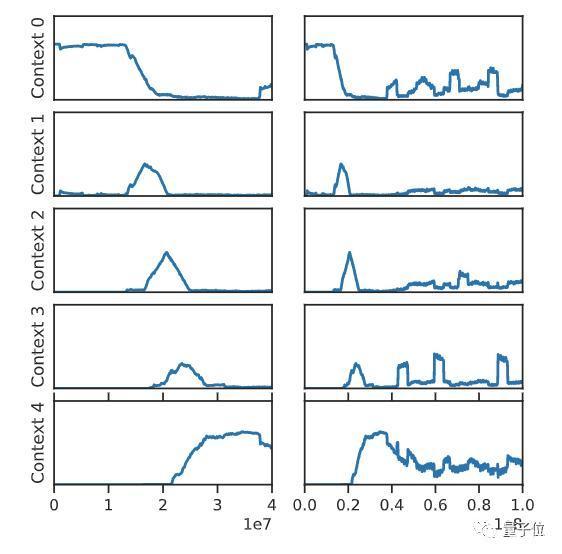
上圖是整個訓練過程中,對游戲的前五個環(huán)境進行采樣的頻率。
在訓練早期(左列),因為尚未發(fā)現(xiàn)之后的環(huán)節(jié),智能體總是在第一階段進行獨立訓練。到了訓練中期,智能體的訓練開始結(jié)合上下文,這就可能會導致干擾。而到了后期,就只會在最后一個階段對智能體進行訓練,這就會導致災難性遺忘。
并且,這種現(xiàn)象廣泛適用。
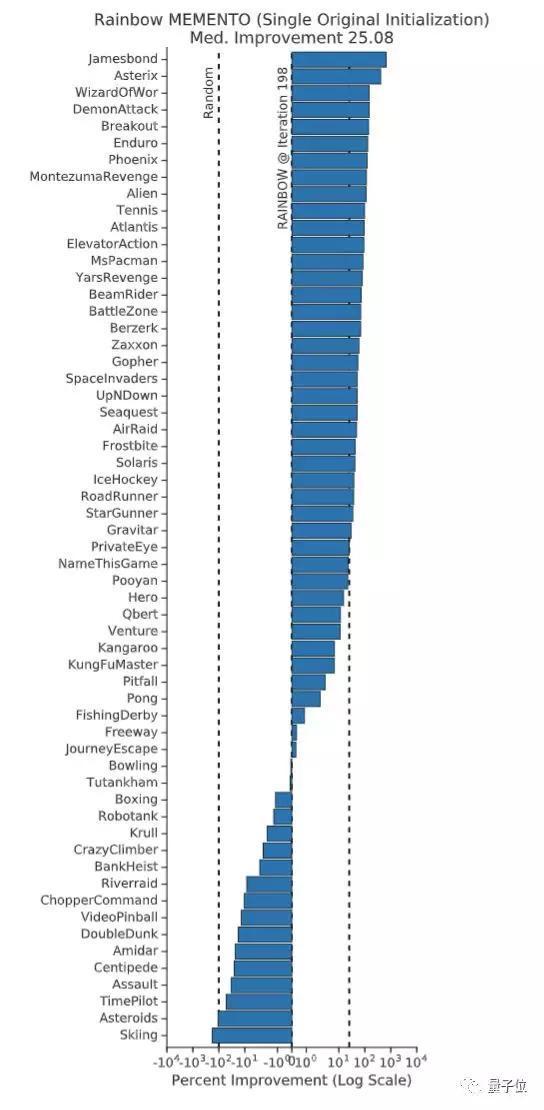
上面這張圖中,每柱對應一個不同的游戲,其高度代表Rainbow Memento智能體相對于Rainbow基線增長的百分比。
在整個ALE中,Rainbow Memento智能體在75%的游戲中表現(xiàn)有所提升,其中性能提升的中位數(shù)是25%。
這項研究證明,在深度強化學習中,單個游戲中的AI無法持續(xù)學習,是因為存在「災難性干擾」。
并且,這一發(fā)現(xiàn)還表明,先前對于「任務」構成的理解可能是存在誤導的。研究人員認為,理清這些問題,將對強化學習的許多基礎問題產(chǎn)生深遠影響。
傳送門
論文地址:https://arxiv.org/abs/2002.12499
GitHub:https://github.com/google-research/google-research/tree/master/memento
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
