

 新火種
2023-10-19
新火種
2023-10-19 


OpenAI科學家最新演講:GPT
編輯:桃子【新智元導讀】GPT-4參數規模擴大1000倍,如何實現?OpenAI科學家最新演講,從第一性原理出發,探討了2023年大模型發展現狀。



「GPT-4即將超越拐點,并且性能實現顯著跳躍」。
這是OpenAI科學家Hyung Won Chung在近來的演講中,對大模型參數規模擴大能力飆升得出的論斷。
在他看來,我們所有人需要改變觀點。LLM實則蘊藏著巨大的潛力,只有參數量達到一定規模時,能力就會浮現。
Hyung Won Chung將這次演講題目定為「2023年的大型語言模型」,旨對LLM領域的發展做一個總結。
在這個領域中,真正重要的是什么?雖然「模型擴展」無疑是突出的,但其深遠的意義卻更為微妙和細膩。
在近一個小時的演講中,Hyung Won Chung從三個方面分享了自己過去4年從業以來對「擴展」的思考。
都有哪些亮點?
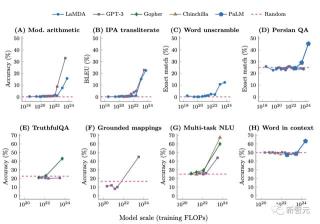
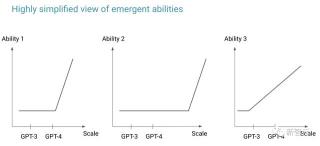
參數規模越大,LLM勢必「涌現」
Hyung Won Chung強調的核心點是,「持續學習,更新認知,采取以“規模”為先的視角非常重要」。
因為只有在模型達到一定規模時,某些能力才會浮現。
多項研究表明,小模型無法解決一些任務,有時候還得需要依靠隨機猜測,但當模型達到一定規模時,就一下子解決了,甚至有時表現非常出色。
因此,人們將這種現象稱之為「涌現」。
即便當前一代LLM還無法展現出某些能力,我們也不應該輕言「它不行」。相反,我們應該思考「它還沒行」。
一旦模型規模擴大,許多結論都會發生改變。
這促使許多研究人員能夠以一個新的視角去看待這個問題,即推理思路的根本性轉變,從「一些方法現在不起作用」,到「一些方法只是在當前不起作用」。
也就是,最新方法可能不適用于當前模型,但是3-5年后,可能變得有效。
有著新穎視角的AI新人,通常可以帶做出有影響力研究。那是因為他們不受一種直覺和想法的束縛,即經驗豐富的人可能已經嘗試過但發現不成功的方法。
Hyung Won Chung表示,自己平時在實驗過程中,會記錄下失敗的過程。每當有了新的模型,他就會再次運行實驗,再來查驗哪些是成功的,哪些是失敗的,以此往復。
這樣一來,就可以不斷更新和糾正自我認知和理解,適應技術的日新月異。
目前,GPT-3和GPT-4之間的能力仍然存在顯著差距,嘗試去彌合與當前模型的差距可能是無效的。
那么,已經有了規模的發展性觀點后,我們該如何擴大參數規模?
第一性原理看Transformer
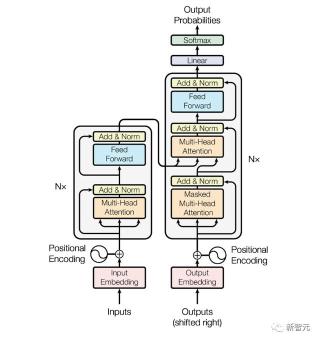
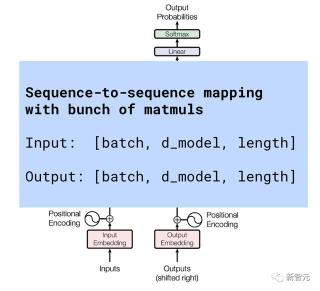
迄今為止,所有大模型背后的架構都是基于Transformer搭建的。想必很多人已經對下圖的樣子熟記于心。
這里,Hyung Won Chung從第一性原理出發探討Transformer的核心思想,并強調了Transformer內部架構細節并非關注重點。
他注意到,許多LLM的研究者不熟悉擴展的具體操作。因此,這部分內容主要是為那些想要理解大型模型訓練含義的技術人員準備的。
從功能性角度來看,可以把Transformer看作帶有矩陣乘法一種簡潔的序列到序列的映射,并可以進行相應數組轉換。
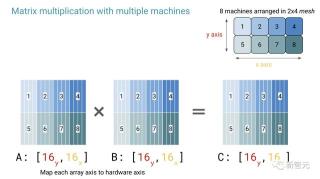
所以,擴大Transformer的規模就是,讓很多很多機器高效地進行矩陣乘法。
通過將注意力機制拆分為單獨的頭,利用多臺機器和芯片,并使用GSP MD方法進行無需通信的并行化。
然后借助Jax的前端工具PJ將陣列軸映射到硬件,可以實現大型語言模型的并行化。
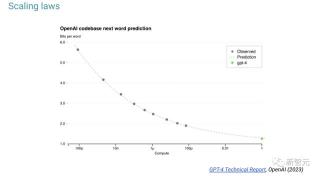
預訓練模型的規模將跨越數量級,縮放法則是用小規模模型開發的。
1萬倍GPT-4,讓神經網絡學習目標函數
再進一步擴展模型規模時,設想是GPT-4的10000倍,應該考慮什么?
對Hyung Won Chung來說,擴展不只是用更多的機器做同樣的事情,更關鍵的是找到限制進一步擴展的「歸納偏差」(inductive bias)。
總之,擴展并不能解決所有問題,我們還需要在這大規模工程的工作中做更多研究,也就是在后訓練中的工作。
你不能直接與預訓練模型對話,但它會在提示后繼續生成,而不是回答問題。即使提示是惡意的,也會繼續生成。
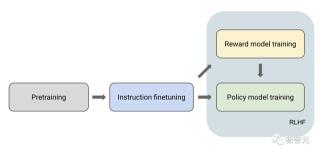
模型后訓練的階段的步驟包括,指令調優——獎勵模型訓練——策略模型訓練,這也就是我們常說的RLHF。
盡管RLHF有著一些弊端,比如獎勵模型容易受到「獎勵黑客」的影響,還有開放的研究問題需要解決,但是我們還是要繼續研究RLHF。
因為,最大似然法歸納偏差太大;學習目標函數(獎勵模型)以釋放縮放中的歸納偏差,是一種不同的范式,有很大的改進空間。
另外,RLHF是一種有原則的算法 ,需要繼續研究,直到成功為止。
總之,在Hyung Won Chung認為,最大似然估計目標函數,是實現GPT-4 10000倍規模的瓶頸。
使用富有表達力的神經網絡學習目標函數,將是下一個更加可擴展的范式。隨著計算成本的指數級下降,可擴展的方法終將勝出。
「不管怎么說,從第一原理出發理解核心思想是唯一可擴展的方法」。
參考資料:https://twitter.com/xiaohuggg/status/1711714757802369456?s=20https://twitter.com/dotey/status/1711504620025942243https://docs.google.com/presentation/d/1636wKStYdT_yRPbJNrf8MLKpQghuWGDmyHinHhAKeXY/edit#slide=id.g27b7c310230_0_496相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
